GLM-Image
@所有人 今天(2026-01-14),我们联合华为开源了新一代图像生成模型GLM-Image, 基于昇腾Atlas 800T A2设备和昇思MindSpore AI框架完成从数据到训练的全流程, 是首个在国产芯片上完成全程训练的SOTA多模态模型。 欢迎大家来玩~ GitHub: https://github.com/zai-org/GLM-Image 技术报告: https://z.ai/blog/glm-image 技术文档: https://zhipu-ai.feishu.cn/wiki/CcwzwOCK2iWPOqkE5v0ceUTKnNg?from=from_copylink API接入: https://docs.bigmodel.cn/cn/guide/models/image-generation/glm-image 体验 https://bigmodel.cn/trialcenter/modeltrial/image 文档 https://docs.bigmodel.cn/cn/guide/models/image-generation/glm-image 

|
```
"""思路
先生成摘要
再根据摘要生成图片
再将图片配置文件形成html页面,然后导出图片,生成海报
根据图片生成一个网站
- 编辑填充内容,一边markdown笔记(也可以是模板),一边是网页效果
- 智能填图,在预定的位置上填充上生成的图片
- html转图片输出
- 由海报拆解为素材生成,由前端展示html页面
可以截图现在的材料,逆向生成prompt模板
- 在些模板的基础上,进行微调
- 将与llm交互的程序单独拉一个API
"""
wenzhang = """
小小苏以案说法之贷款诈骗洗钱案
"""
prompt = """
根据以下内容生成一张图片
{wenzhang}
图片格式要求:
1. 使用中文描述,同时避免出现中文乱码的情况;图片最终输出前请检查是否存在中文乱码,若存在则进行修正;
2. 小小苏一个龙形态的卡通动物形象,表情是一种被骗的苦笑,总体是卡哇伊卡通表情
"""
"""
curl --request POST \
--url https://open.bigmodel.cn/api/paas/v4/images/generations \
--header 'Authorization: Bearer 715c...tjc3' \
--header 'Content-Type: application/json' \
--data '
{
"model": "cogView-4-250304",
"prompt": "一只可爱的小猫咪,坐在阳光明媚的窗台上,背景是蓝天白云.",
"size": "1024x1024"
}
'
"""
"""
图像的像素有要求:
宽度和高度必须在 512-2048 之间
必须是 16 的倍数
最大像素数不能超过 2^21 (2097152)
脱敏需求
图片生成的风格
1. 使用中文描述,同时避免出现中文乱码的情况
图片上有AI生成的标记,无法去掉
整体生成海报的方式不可取
"""
import requests
import json
import time
import re
# 智谱AI尺寸要求:
# - 宽度和高度必须在 512-2048 之间
# - 必须是 16 的倍数
# - 最大像素数不能超过 2^21 (2097152)
# 常用海报尺寸:1024x1024 (1:1), 1024x1792 (9:16), 1536x640 (12:5)
w = 1024
h = 1024 # 使用正方形,符合所有要求
_size = f"{w}x{h}"
def desensitize_text(text):
"""
脱敏处理函数,将敏感信息替换为通用描述
Args:
text: 原始文本
Returns:
str: 脱敏后的文本
"""
# 姓名脱敏(中文姓名2-3个汉字)
text = re.sub(r'[钱朱林赵王张]某', '犯罪嫌疑人', text)
# 地名/机构名脱敏
text = re.sub(r'人民银行江苏省分行', '金融机构', text)
text = re.sub(r'交通银行江苏省分行', '商业银行', text)
text = re.sub(r'2025年7月', '近期', text)
text = re.sub(r'2023年7月至9月', '案发期间', text)
text = re.sub(r'2023年8月至9月', '案发期间', text)
# 具体金额脱敏
text = re.sub(r'人民币十六万元', '相应罚金', text)
text = re.sub(r'人民币十万元', '相应罚金', text)
text = re.sub(r'人民币五万元', '相应罚金', text)
text = re.sub(r'有期徒刑三年', '有期徒刑', text)
text = re.sub(r'有期徒刑一年十个月', '有期徒刑', text)
# 车辆品牌等具体信息脱敏
text = re.sub(r'车辆无抵押信用贷款', '车辆贷款', text)
text = re.sub(r'汽车销售服务公司', '销售公司', text)
return text
def generate_poster_prompt(original_text):
"""
生成脱敏后的海报提示词
Args:
original_text: 原始文章文本
Returns:
str: 适合AI生成的海报提示词
"""
# 先脱敏
desensitized = desensitize_text(original_text)
# 生成通用的、不包含敏感信息的提示词
prompt = """请设计一张金融安全宣传海报的头部图片,主题:防范贷款诈骗和洗钱风险
海报内容要素:
【核心主题】
- 警惕贷款诈骗
- 远离洗钱风险
- 保护个人银行账户
- 不要出现中文乱码
【视觉元素】
- 金融图标(金钱、计算器、小汽车)
- 现代简约设计风格
【图片中的标题】
- 小小苏以案说法之贷款诈骗洗钱案
- 每行最多8个字,超过则换行
- 标题的文本背景进行一定特写
- 标题的字体稍微艺术化一些,看起来总体给人一种轻松中稍微带点调皮的感觉
【设计风格】
- 适合金融机构宣传使用
- 小小苏作为一个龙形态但头部像人的卡通动物形象,表情是一种被骗的苦笑,总体是卡哇伊卡通表情
- 使用中文描述,同时避免出现中文乱码的情况;图片最终输出前请检查是否存在中文乱码,若存在则进行修正;
请生成一张1024x1024像素的图片,该图片会做为海报网页开头的部分,让人一眼看见这个图片"""
return prompt
def generate_image(prompt_text,
models=["glm-image", "cogview-3"],
api_key="715c27776d19889a332309a4c81b3e0f.D6VnhU9eQl8Itjc3",
size=_size,
max_retries=3,
timeout=120):
"""
调用智谱AI图像生成API(带重试机制)
Args:
prompt_text: 图像生成提示词
models: 模型列表,优先使用第一个
api_key: API密钥
size: 图像尺寸,如 "1024x1024"
max_retries: 最大重试次数(默认3次)
timeout: 请求超时时间(秒,默认120秒)
Returns:
dict: API响应结果
"""
url = "https://open.bigmodel.cn/api/paas/v4/images/generations"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
# 尝试不同的模型
for model in models:
for retry in range(max_retries):
data = {
"model": model,
"prompt": prompt_text,
"size": size
}
try:
print(f"[请求信息] 尝试: {retry + 1}/{max_retries} | Model: {model}")
print(f"[请求信息] URL: {url}")
print(f"[请求信息] Size: {data['size']}")
print(f"[请求信息] Prompt 长度: {len(prompt_text)} 字符")
print(f"[请求信息] 超时设置: {timeout}秒")
response = requests.post(url, headers=headers, json=data, timeout=timeout)
print(f"[响应信息] 状态码: {response.status_code}")
if response.status_code == 200:
print(f"[成功] 模型 {model} 生成成功!")
return response.json()
else:
print(f"[失败] HTTP {response.status_code}")
print(f"[错误详情] {response.text[:200]}")
# 如果是客户端错误(4xx),不需要重试
if 400 <= response.status_code < 500:
print(f"[提示] 客户端错误,停止重试")
return {
"error": f"HTTP {response.status_code}",
"details": response.text,
"status_code": response.status_code,
"model": model
}
except requests.exceptions.Timeout as e:
print(f"[超时] 第 {retry + 1} 次尝试超时: {str(e)}")
if retry < max_retries - 1:
wait_time = (retry + 1) * 5 # 递增等待时间:5s, 10s, 15s
print(f"[等待] {wait_time}秒后重试...")
time.sleep(wait_time)
else:
print(f"[放弃] 已达最大重试次数")
except requests.exceptions.RequestException as e:
print(f"[请求异常] {str(e)}")
if retry < max_retries - 1:
print(f"[重试] 5秒后重试...")
time.sleep(5)
else:
return {"error": str(e), "model": model}
print(f"[切换] 尝试下一个模型...\n")
# 所有模型都失败了
return {
"error": "所有模型尝试失败",
"tried_models": models,
"suggestion": "请检查网络连接或稍后重试"
}
if __name__ == "__main__":
# 使用脱敏后的提示词生成海报
print(f"[测试] 使用脱敏模板生成海报...\n")
# 方法1:使用通用模板(推荐)
poster_prompt = generate_poster_prompt(wenzhang)
print(f"[脱敏提示词] 长度: {len(poster_prompt)} 字符\n")
print(f"[提示词预览]\n{poster_prompt}\n")
print("="*80 + "\n")
result = generate_image(poster_prompt)
print("\n[结果]")
print(json.dumps(result, ensure_ascii=False, indent=2))
# 如果成功生成,保存图片URL
if isinstance(result, dict) and 'data' in result:
print("\n[成功] 图片生成成功!")
if len(result['data']) > 0 and 'url' in result['data'][0]:
image_url = result['data'][0]['url']
print(f"[图片URL] {image_url}")
# 下载图片
try:
img_response = requests.get(image_url, timeout=30)
if img_response.status_code == 200:
timestamp = time.strftime("%Y%m%d_%H%M%S")
filename = f"poster_{timestamp}.png"
with open(filename, 'wb') as f:
f.write(img_response.content)
print(f"[保存成功] 图片已保存为: {filename}")
else:
print(f"[下载失败] HTTP {img_response.status_code}")
except Exception as e:
print(f"[下载异常] {str(e)}")
```

- 增加下面这张图片之前的效果 - 标题的字体稍微艺术化一些,看起来总体给人一种轻松中稍微带点调皮的感觉 
|
点击下面的地址的链接,申请去水印即可 https://bigmodel.cn/usercenter/safety-mgmt/watermark |
```
from tpf.llm import MyChat
chat = MyChat()
url,img_path = chat.glm_image(prompt=prompt,
models=["cogview-3","glm-image", ],
outdir="",size="1024x1024",)
print("img_path:",img_path)
```
|
|
|
Claude插件
|
- Claude Code for VS Code
- 环境变量添加
```
Path添加
C:\Program Files\Git\bin
C:\Program Files\Git\usr\bin
```
- GIT 环境配置·临时配置
```
# 临时添加到 PATH
$env:Path = "C:\Program Files\Git\bin;C:\Program Files\Git\usr\bin;$env:Path"
# 验证 bash 可以从 PATH 直接调用
bash --version
# 清除专用环境变量(可能造成冲突)
Remove-Item Env:CLAUDE_CODE_GIT_BASH_PATH -ErrorAction SilentlyContinue
# 现在尝试运行 claude
claude
```
|
|
```
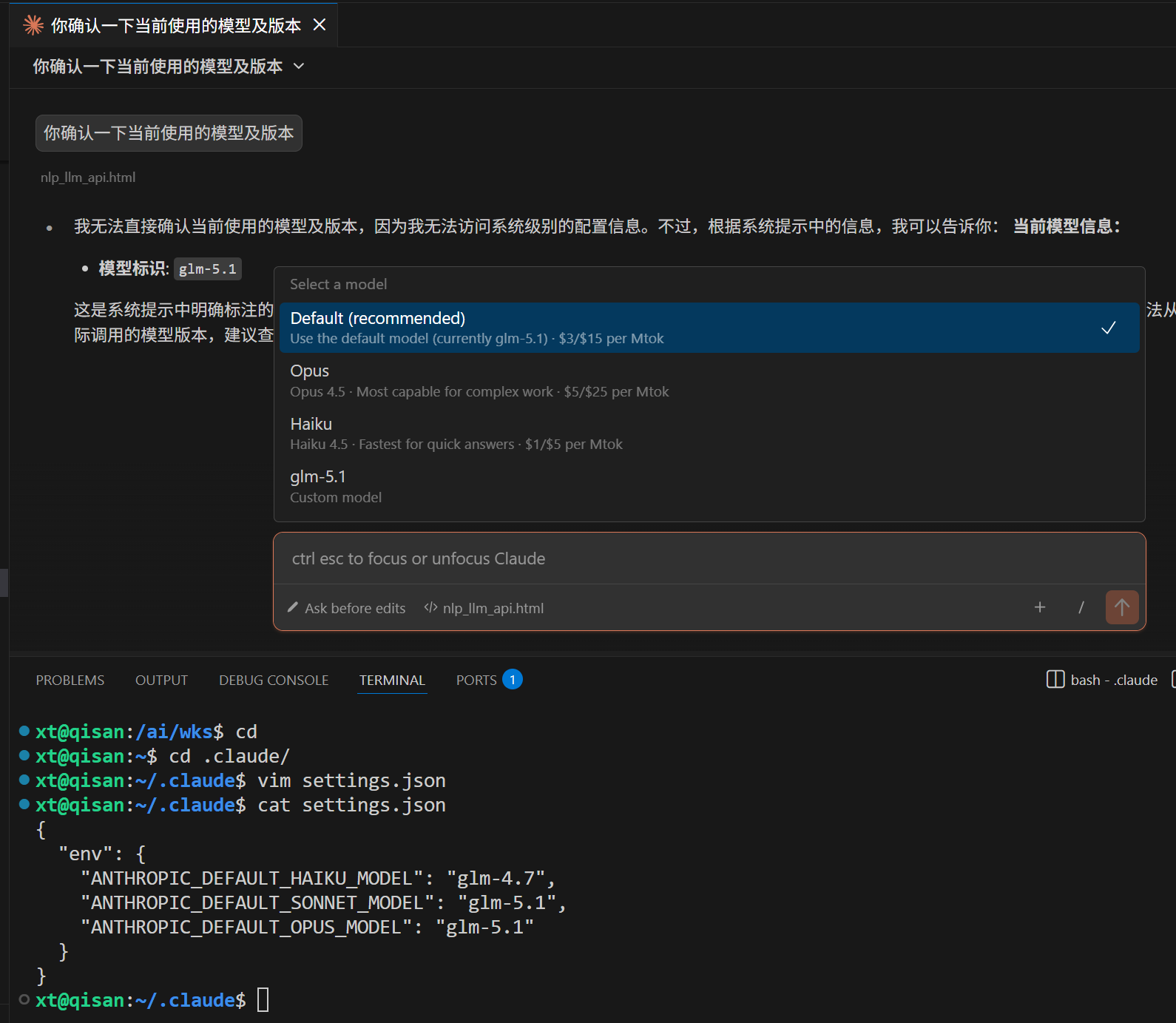
xt@qisan:~/.claude$ cat settings.json
{
"env": {
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.6",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.7",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-5.1"
}
}
```

```
xt@qisan:~/.claude$ vim settings.json
xt@qisan:~/.claude$ cat settings.json
{
"env": {
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.7",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-5.1",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-5.1"
}
}
```
```
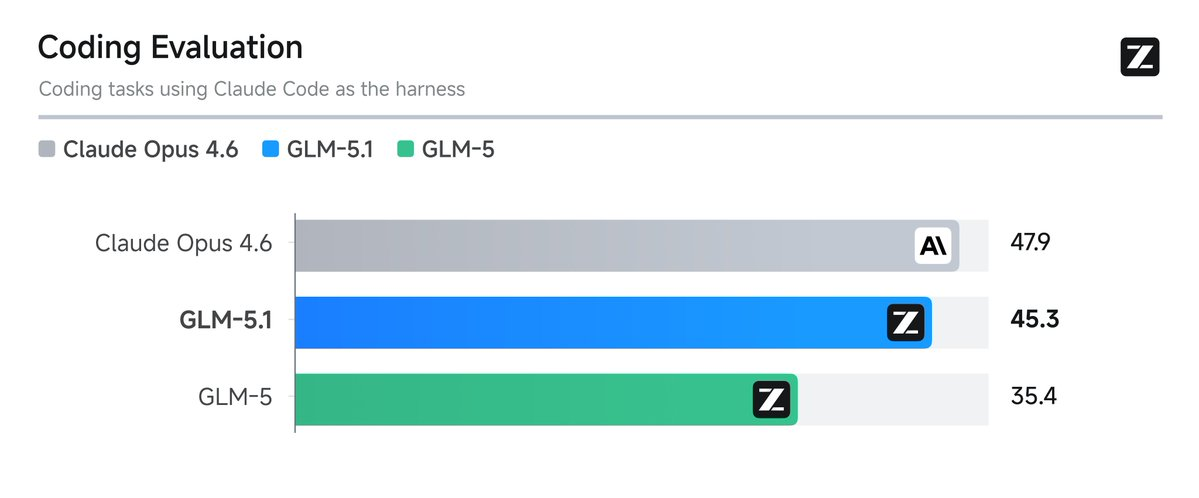
>>> 45.3/47.9
0.9457202505219207
```
|
|
|
|
|
|
|
|
|
|
|
|
|
GLM·概述
node --version #v20.9.0
npm --version #8.5.5
npm install -g @anthropic-ai/claude-code
claude --version # 1.0.108 (Claude Code)
npm install -g @anthropic-ai/claude-code@1.0.108
export ANTHROPIC_BASE_URL="https://open.bigmodel.cn/api/anthropic"
export ANTHROPIC_AUTH_TOKEN="777...8Itj"
安装完后右上方出现一个星状图标
ANTHROPIC_BASE_URL="https://open.bigmodel.cn/api/anthropic" - 这一步是以代理的方式运行,会连接到GLM-4.5
点击星状图标,一路击“回车” ,然后“新建对话”
windows环境 ``` PS C:\Users\itora> npm -v 8.5.5 ``` npm install -g @anthropic-ai/claude-code 安装插件 Claude Code for VS Code ANTHROPIC_BASE_URL=https://open.bigmodel.cn/api/anthropic ANTHROPIC_AUTH_TOKEN="777...8Itj" |
使用说明
https://docs.bigmodel.cn/cn/coding-plan/overview
cd your-project-directory
claude
claude插件升级导致的需要账户登录问题 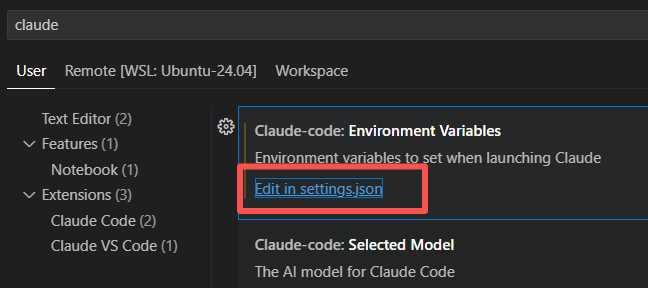
"claude-code.environmentVariables": [
{
"name":"ANTHROPIC_BASE_URL",
"value":"https://open.bigmodel.cn/api/anthropic"
}
]
vim ~/.claude/config.json
{
"primaryApiKey": "715c2777...tjc3"
}
|
|
视觉配置 https://zhipu-ai.feishu.cn/wiki/WiCOwgJQ8icRJ4k1RGKcWDEnnod npm install -g @anthropic-ai/claude-code xt@qisan:/wks/nodejs/app/global/bin$ which claude /wks/nodejs/app/node-v20.9.0-linux-x64//global/bin/claude export your_api_key="715c...jc3" claude mcp add -s user zai-mcp-server --env Z_AI_API_KEY=$your_api_key -- npx -y "@z_ai/mcp-server" ``` $ claude mcp add -s user zai-mcp-server --env Z_AI_API_KEY=$your_api_key -- npx -y "@z_ai/mcp-server" Added stdio MCP server zai-mcp-server with command: npx -y @z_ai/mcp-server to user config File modified: /home/xt/.claude.json $ claude mcp list Checking MCP server health... zai-mcp-server: npx -y @z_ai/mcp-server - ✓ Connected ``` claude mcp remove zai-mcp-server 支持工具 - ui_to_artifact - 将 UI 截图转换为代码、提示词、设计规范或自然语言描述,覆盖从前端落地到生成式设计提示的全流程 - extract_text_from_screenshot - 使用先进的 OCR 能力从截图中提取和识别文字。专门用于代码、终端输出、文档和通用文本的提取 - diagnose_error_screenshot - 解析错误弹窗、堆栈和日志截图,给出定位与修复建议 - understand_technical_diagram - 针对架构图、流程图、UML、ER 图等技术图纸生成结构化解读 - analyze_data_visualization - 阅读仪表盘、统计图表,提炼趋势、异常与业务要点 - ui_diff_check - 对比两张 UI 截图,识别视觉差异和实现偏差。专门用于 UI 质量保证和设计到实现的验证 - image_analysis - 通用图像理解能力,适配未被专项工具覆盖的视觉内容 - video_analysis - 支持 MP4/MOV/M4V(限制本地最大8M) 等格式的视频场景解析,抓取关键帧、事件与要点 用法 使用中文描述一下/ai/wks/work2/haibao/anjian1.jpg的内容 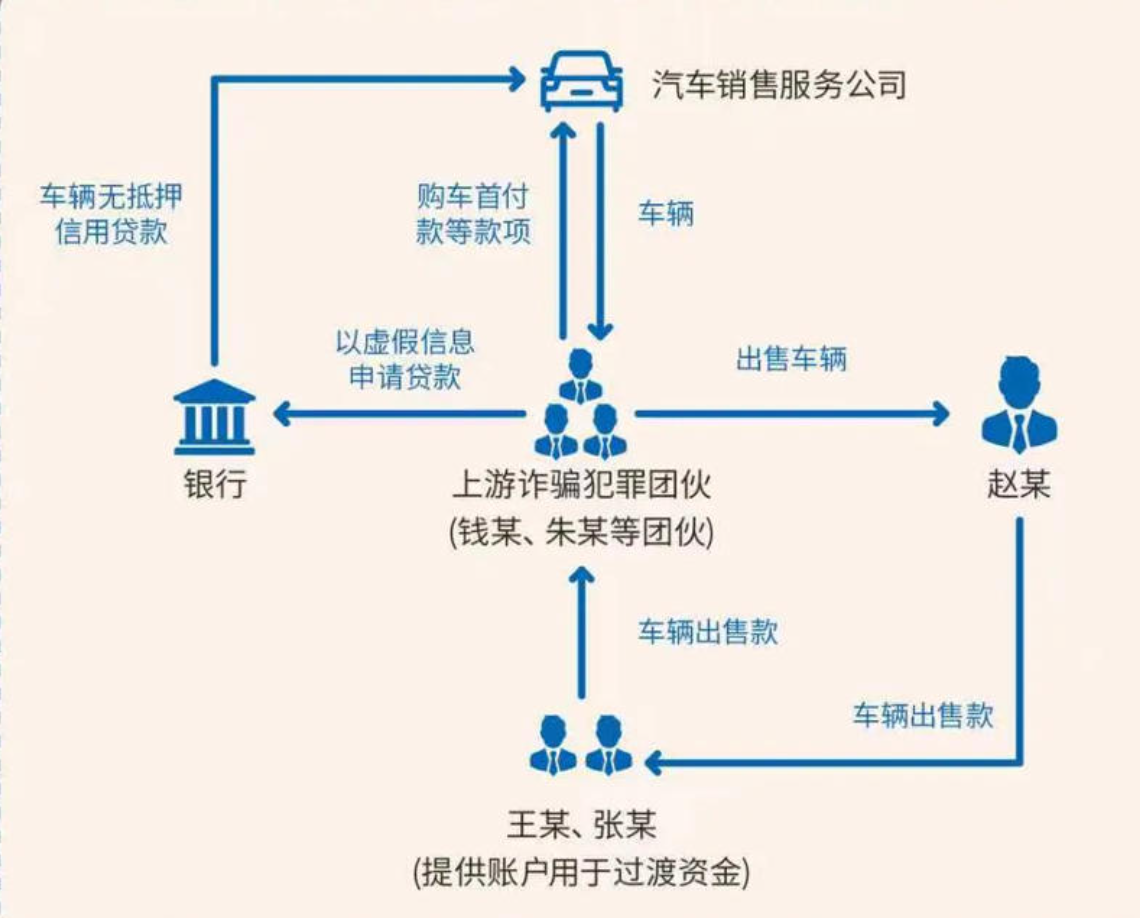
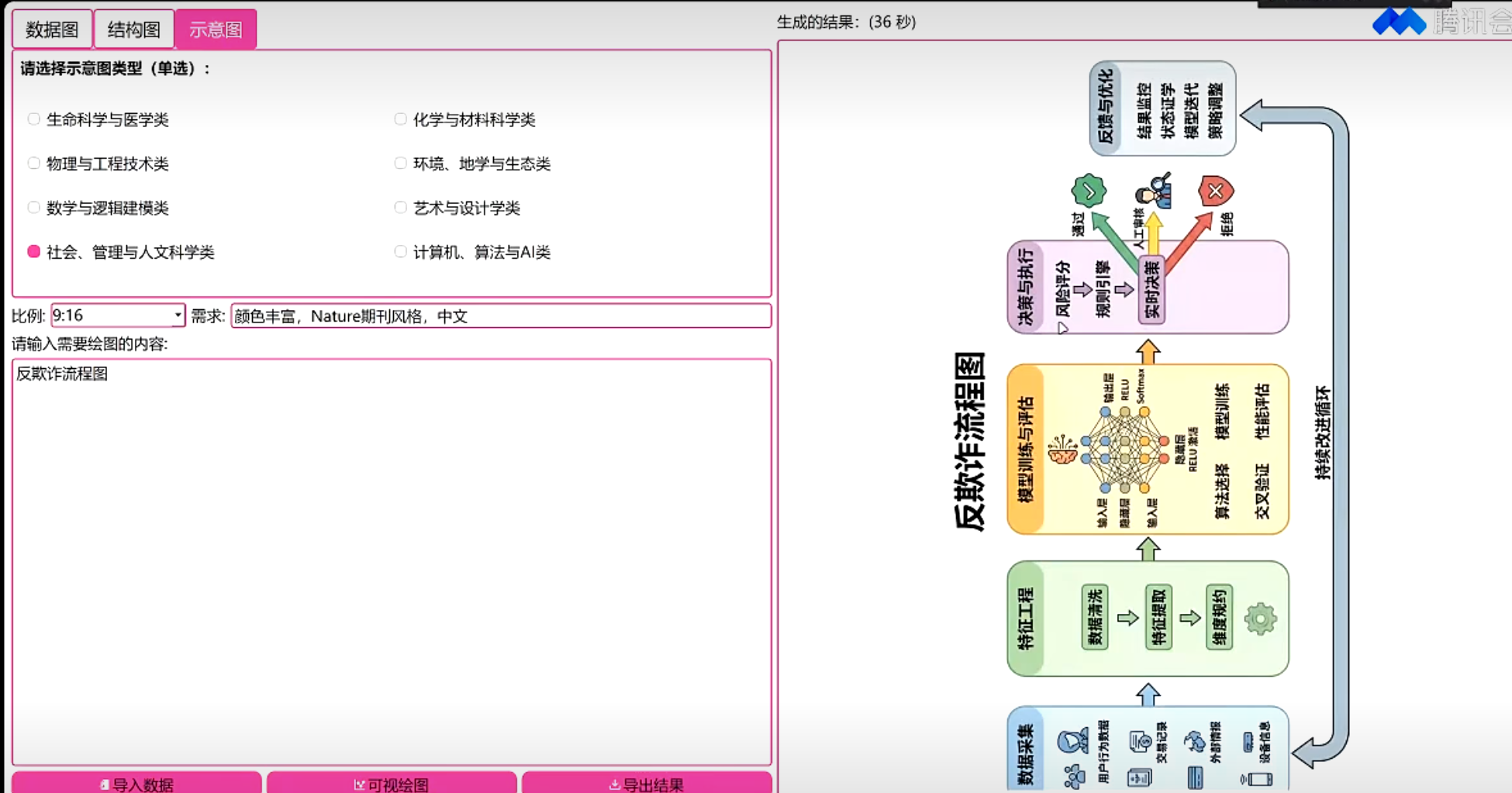
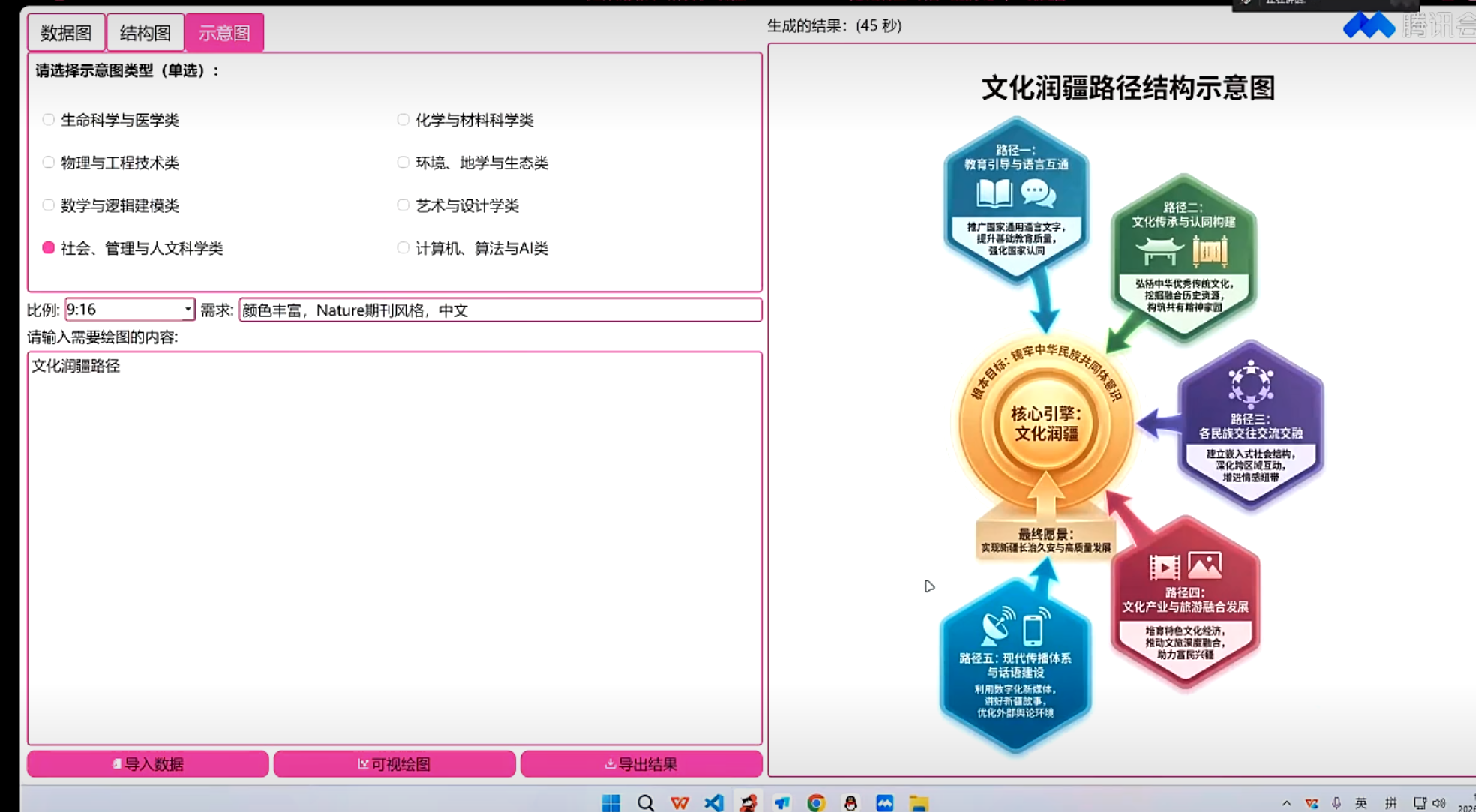
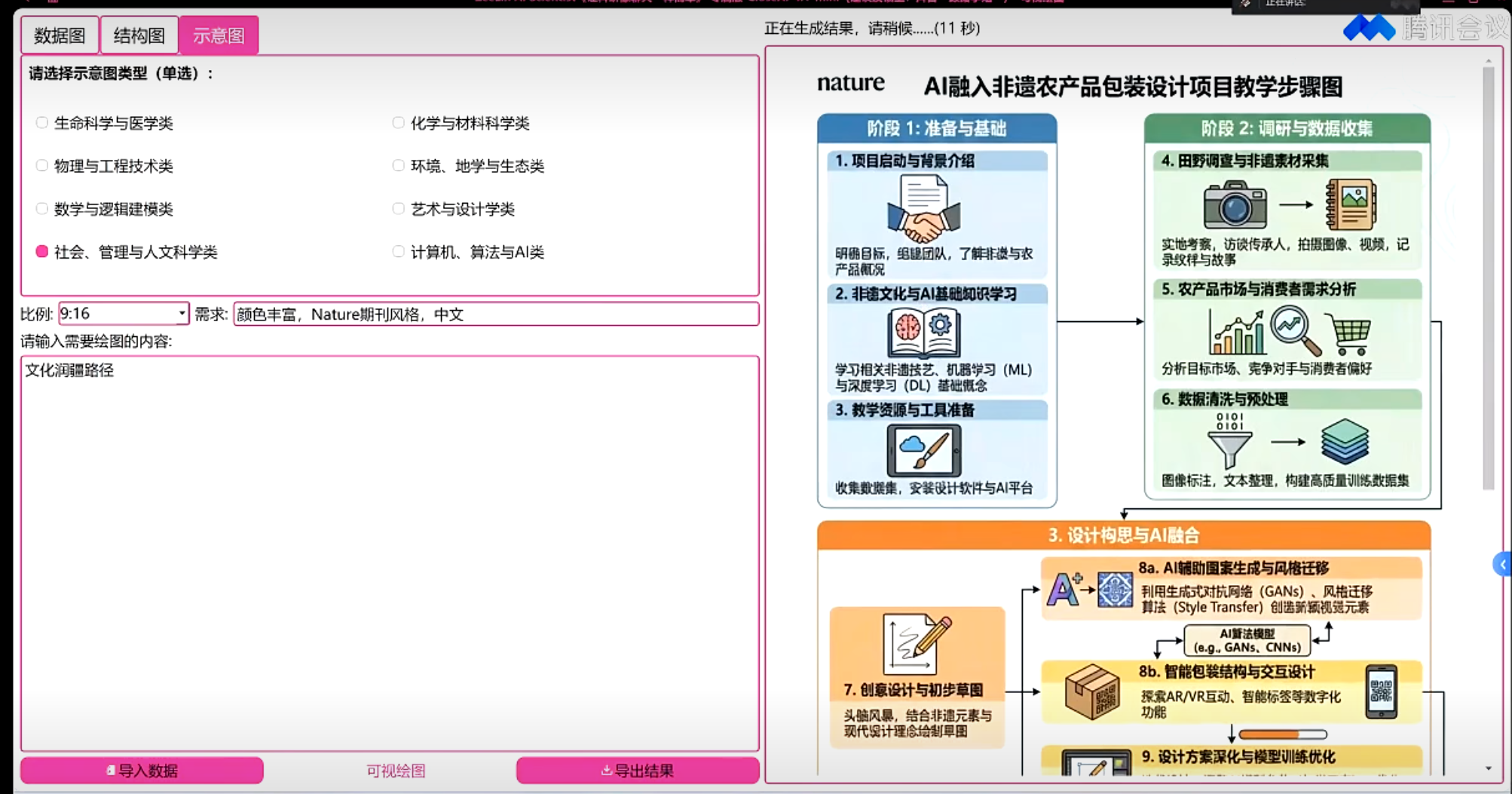
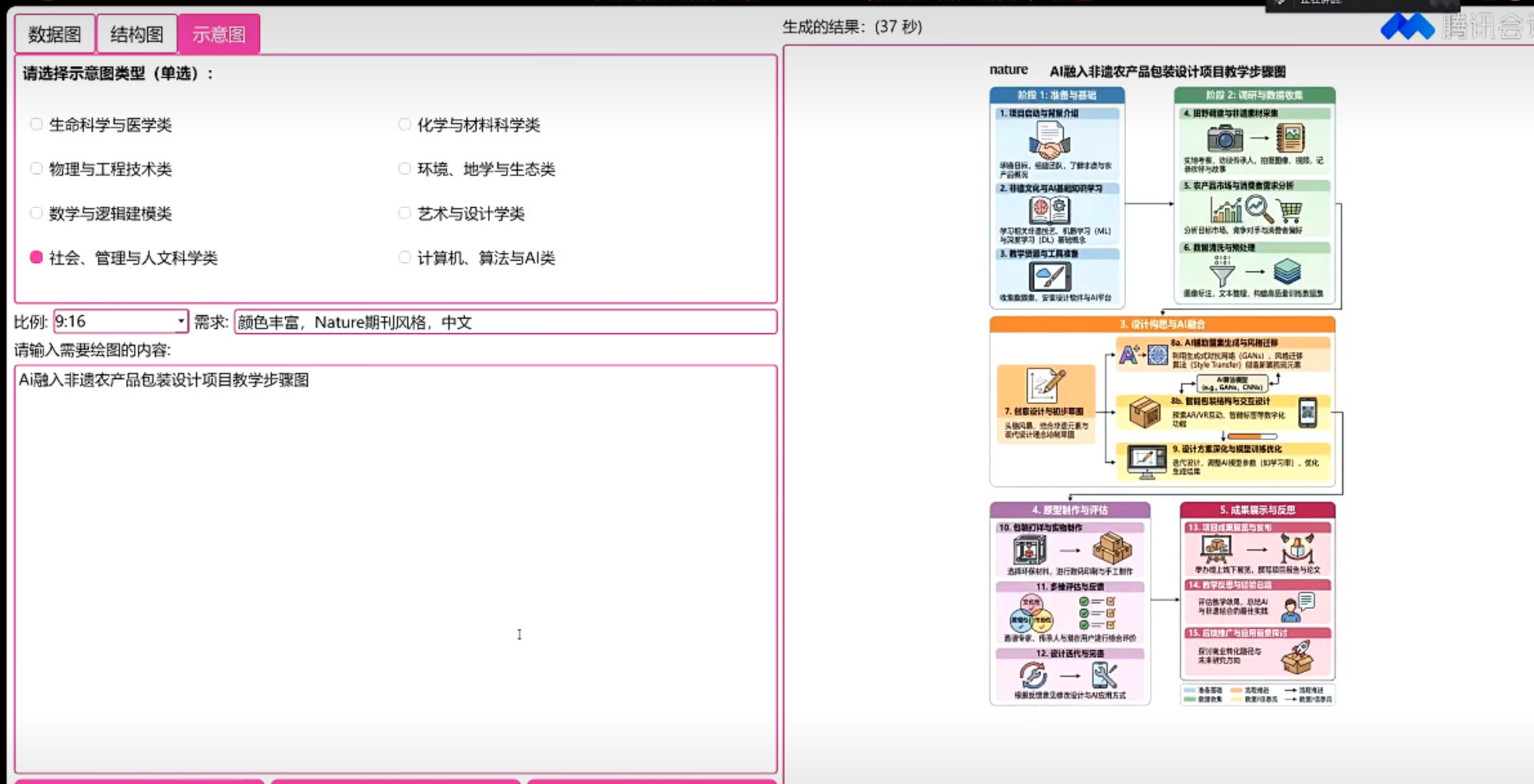
根据图片分析,这张图片的内容如下 图片描述 这是一张犯罪流程示意图,展示了汽车销售领域的诈骗案件流程。 1. 图片类型 类型:信息流程图 主题:展示"汽车无抵押信用贷款"诈骗的运作流程 2. 主要参与者(节点) 图中包含以下5个主体: 银行(蓝色建筑图标):金融机构 汽车销售服务公司(蓝色汽车图标):车辆销售方 上游诈骗犯罪团伙(3个蓝色人形图标,代表钱某、朱某等):核心犯罪主体 赵某(蓝色西装人形图标):购车人 王某、张某(2个蓝色人形图标):资金过渡人员,提供账户用于过渡资金 3. 流程描述(箭头连线) 资金和物品的流动路径: 银行 → 上游团伙:"车辆无抵押信用贷款" + "以虚假信息申请贷款"(团伙骗取贷款) 上游团伙 → 汽车销售公司:"购车首付款等款项"(用贷款支付购车款) 汽车销售公司 → 上游团伙:"车辆"(销售公司交付车辆) 上游团伙 → 赵某:"出售车辆"(团伙将车辆卖给赵某) 赵某 → 王某、张某:"车辆出售款"(赵某支付购车款给过渡人员) 王某、张某 → 上游团伙:"车辆出售款"(过渡人员将资金转给团伙,完成套现) 4. 布局结构 中心位置:上游诈骗团伙位于图的中心,连接所有其他主体 四周分布: 左侧:银行 上方:汽车销售公司 右侧:赵某 下方:王某、张某 5. 诈骗链条核心逻辑 整个流程形成闭环:贷款 → 购车 → 出售 → 套现 上游团伙通过"虚假信息"骗取银行贷款,用贷款购车后转售给赵某,赵某的购车款通过王某、张某的账户过渡后最终回到团伙手中,完成诈骗套现。 6. 颜色和风格 主色调:蓝色(箭头、图标、文字),象征专业与正式 底色:浅米色,柔和不刺眼 边框:虚线矩形,增强整体感 风格:扁平化设计,简洁直观 |
|
联网搜索 claude mcp list claude mcp remove web-search-prime export your_api_key="715c...jc3" claude mcp add -s user -t http web-search-prime https://open.bigmodel.cn/api/mcp/web_search_prime/mcp --header "Authorization: Bearer $your_api_key" claude mcp list - webSearchPrime - 搜索网络信息,返回结果包括网页标题、网页URL、网页摘要、网站名称、网站图标等。 网页读取 claude mcp add -s user -t http web-reader https://open.bigmodel.cn/api/mcp/web_reader/mcp --header "Authorization: Bearer $your_api_key" - webReader - 抓取指定URL的网页内容,返回结果包括网页标题、正文内容、元数据、链接列表等。 github代码 claude mcp add -s user -t http zread https://open.bigmodel.cn/api/mcp/zread/mcp --header "Authorization: Bearer $your_api_key" - search_doc - 搜索 GitHub 仓库的对应的知识文档,快速了解仓库知识,新闻,最近的 issue pr 和贡献者等。 - get_repo_structure - 获取 GitHub 仓库的目录结构和文件列表,了解项目模块拆分和目录组织方式。 - read_file - 读取 GitHub 仓库中指定文件的完整代码内容,深入文件代码的实现细节。 |
|
手工配置
vim ~/.claude/settings.json
{
"env": {
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.5-air",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.7",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-4.7"
}
}
命令选择 在对话框中输入:/ 从提示中选择Switch model ~/.claude/settings.json配置的优先级要高于接口的模型,接口只供转发,是一个代理的作用 另外,settings.json配置也只是个文件接口,实际上后台智谱转到了哪个模型就是哪个模型 |
|
|
|
|
OAI
- 在 VS Code 中通过 OAI Compatible Provider for Copilot 插件,接入 智谱AI 的 GLM-4.6 或 GLM-5 大模型 - 在 VS Code 的扩展商店中搜索并安装 OAI Compatible Provider for Copilot - 安装完成后,点击 插件右边的齿轮设置图标,选择settings,进入插件设置界面 - Base Url: https://open.bigmodel.cn/api/anthropic - Commit Language: 选择 简体中文 - 配置完插件后,点击chat图标,展开对话框,Auto -- Manage Models -- Add Models - 选择 Anthropic ,API Key,完成模型添加 - 智谱AI官方平台 https://open.bigmodel.cn/, API Key 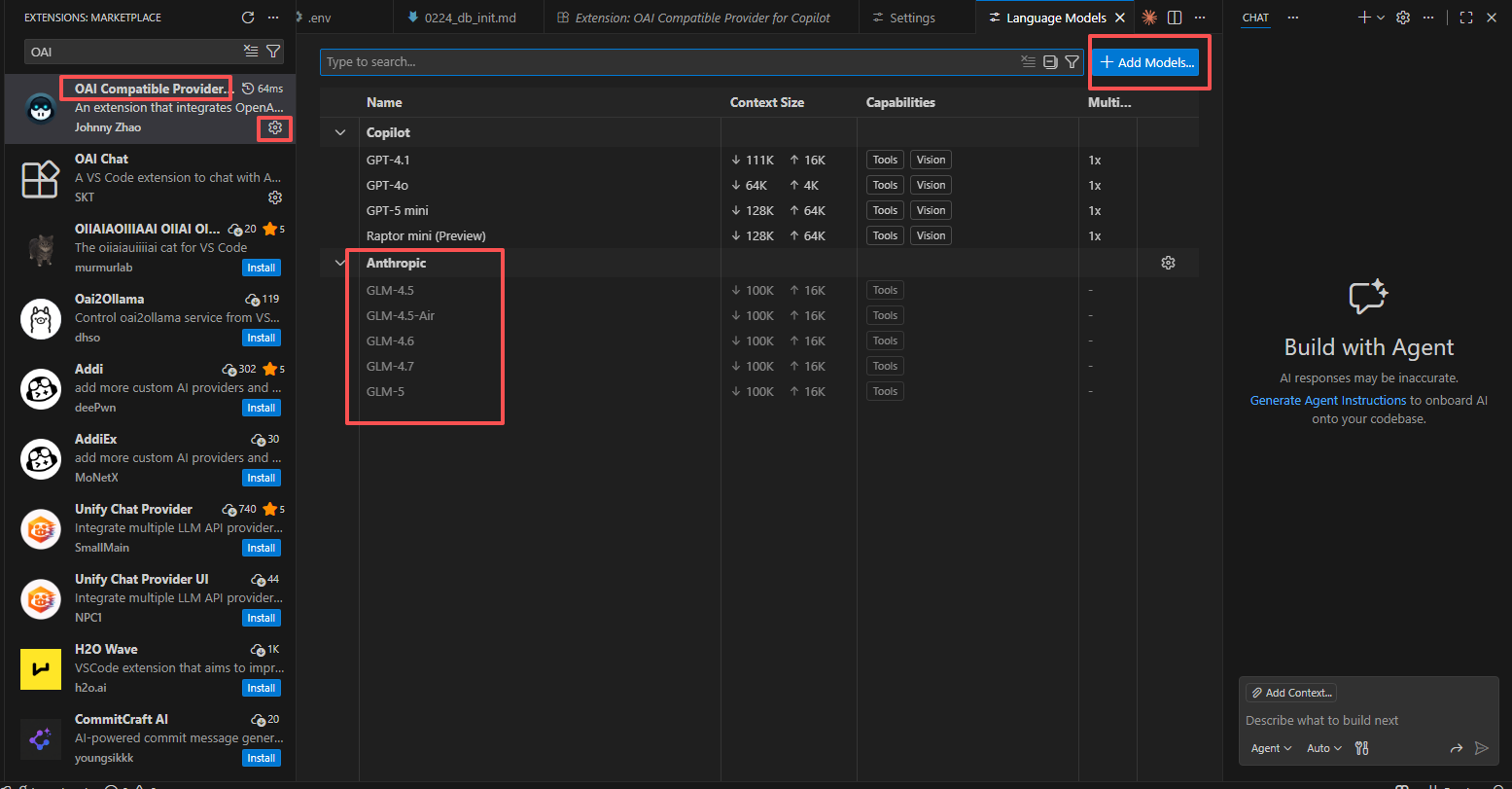
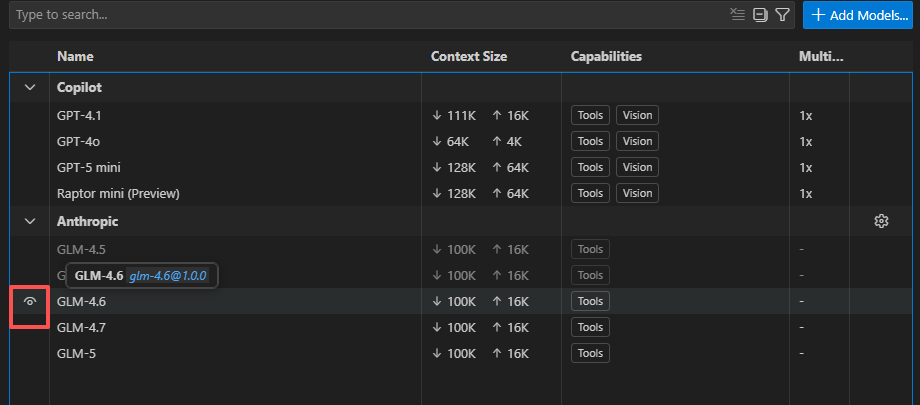
``` export ANTHROPIC_BASE_URL="https://open.bigmodel.cn/api/anthropic" export ANTHROPIC_AUTH_TOKEN="777...8Itj" ``` - 没买智谱包月计划的,按tokens消耗扣费: 填写具体模型的base url
|
|
|
|
|
|
|
|
|
|
|
|
|
|
vscode·llm插件
|
- 无需登录
- Continue - open-source AI code agent
- 小齿轮 -- settings --
- Continue: Remote Config Server Url
- https://api.deepseek.com/v1
- Continue: User Token
- 填写token
- 点击右下角 Continue(NE)
-
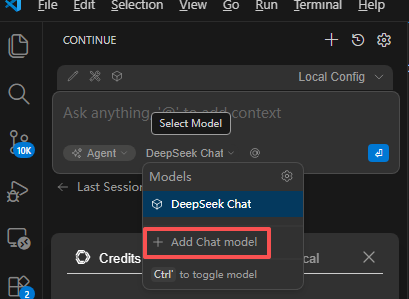
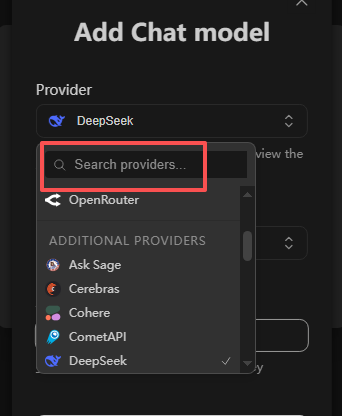
- 输入相关的模型,可以搜索
|
|
- 点击 Continue(NE) 小图标 -- Open Settings
- Configs -- Local Config -- Edit in settings.json
如果出现下面的内容,则将左侧栏拉宽一下 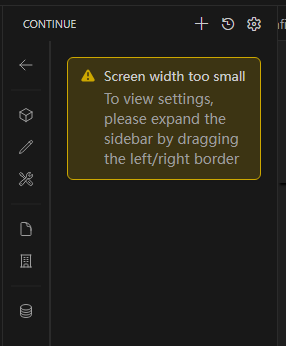
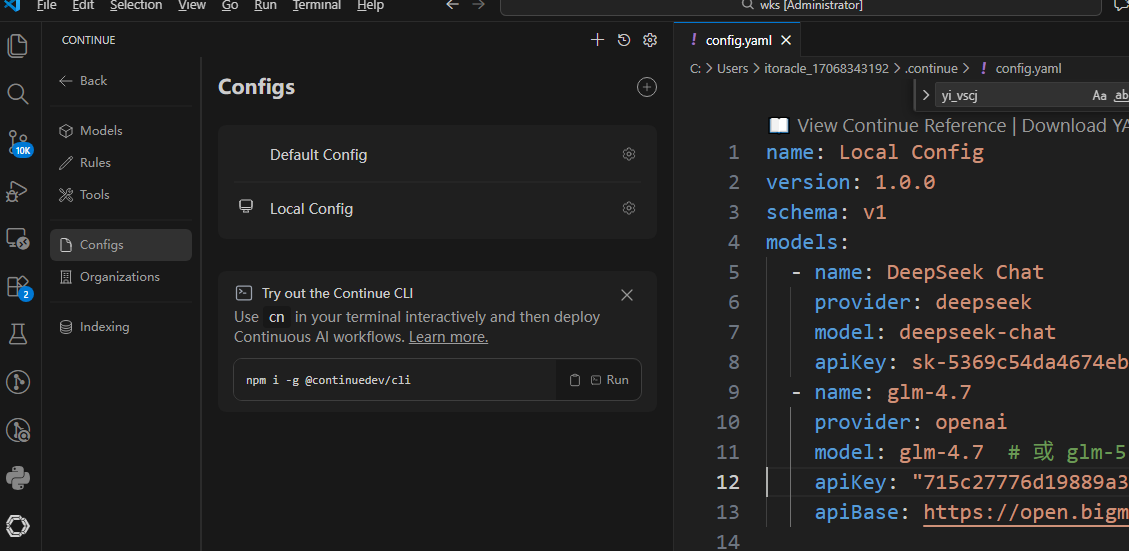
```
- name: glm-4.7
provider: openai
model: glm-4.7 # 或 glm-5,具体名称请参考你的服务说明
apiKey: "715c9a...8Itjc3"
apiBase: https://open.bigmodel.cn/api/coding/paas/v4/
```
|
|
|
|
|
|
|
|
|
|
|
|
|
通义千问
https://bailian.console.aliyun.com/cn-beijing/#/home itoracle@aliyun.com Name_deptno |
https://bailian.console.aliyun.com/cn-beijing/?tab=api#/api/?type=model&url=2975126
支持多样化的艺术风格,尤其擅长在图像中渲染复杂文字,可实现图文混合的布局设计。
qwen-image-plus-2026-01-09推荐
qwen-image
同步接口(推荐)
HTTP调用
通义千问Qwen-image模型支持同步接口,一次请求即可获得结果,调用流程简单,推荐用于多数场景。
北京地域:POST
https://dashscope.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation
```
curl --location 'https://dashscope.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation' \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer $DASHSCOPE_API_KEY" \
--data '{
"model": "qwen-image-max",
"input": {
"messages": [
{
"role": "user",
"content": [
{
"text": "一副典雅庄重的对联悬挂于厅堂之中,房间是个安静古典的中式布置,桌子上放着一些青花瓷,对联上左书“义本生知人机同道善思新”,右书“通云赋智乾坤启数高志远”, 横批“智启通义”,字体飘逸,在中间挂着一幅中国风的画作,内容是岳阳楼。"
}
]
}
]
},
"parameters": {
"negative_prompt": "低分辨率,低画质,肢体畸形,手指畸形,画面过饱和,蜡像感,人脸无细节,过度光滑,画面具有AI感。构图混乱。文字模糊,扭曲。",
"prompt_extend": true,
"watermark": false,
"size": "1664*928"
}
}'
```
|
|
- https://qwen.ai/qwencode
- vscode 插件:
- Qwen Code Companion
|
|
|
|
|
|
|
|
|
|
|
文心一言的使用
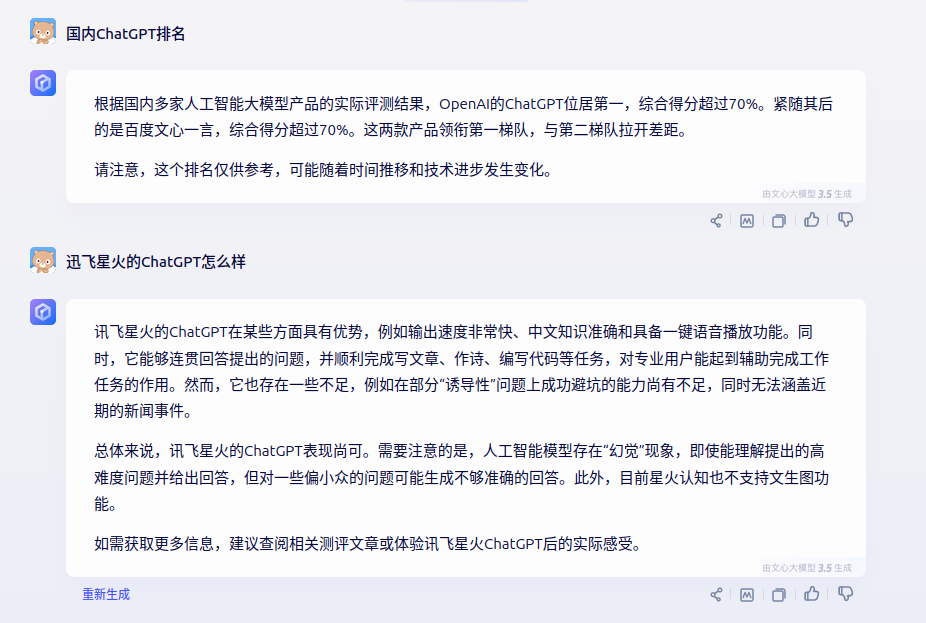
https://yiyan.baidu.com/?from=baidu_pc_index 点击链接,或者在百度的右上角点击“文心一言” 在打开的页面,点击左上角的“新建对话”,然后在最下面的对话框中输入要问的问题 回车就出结果了
文心一言开发者
https://yiyan.baidu.com/developer https://yiyan.baidu.com/developer/doc 百度智能云千帆ModelBuilder https://cloud.baidu.com/doc/WENXINWORKSHOP/index.html
API接入指南
https://developer.baidu.com/article/detail.html?id=1089328 应用创建 https://console.bce.baidu.com/qianfan/ais/console/applicationConsole/application 获取token https://cloud.baidu.com/doc/WENXINWORKSHOP/s/Ilkkrb0i5 https://console.bce.baidu.com/tools/?u=qfdc#/api?product=QIANFAN&project=%E5%8D%83%E5%B8%86%E5%A4%A7%E6%A8%A1%E5%9E%8B%E5%B9%B3%E5%8F%B0&parent=%E9%89%B4%E6%9D%83%E8%AE%A4%E8%AF%81%E6%9C%BA%E5%88%B6&api=oauth/2.0/token&method=post |
import requests
import json
def main():
url = "https://aip.baidubce.com/oauth/2.0/token?client_id=OU3TC25XAVAJmirZjo463KhA&client_secret=cMG5XHzFHop4t3A3wX5U9TU5vstSLtF0&grant_type=client_credentials"
payload = json.dumps("")
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
if __name__ == '__main__':
main()
# 获取access_token,替换下列示例中的API Key与Secret Key curl -X POST 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=[API Key]&client_secret=[Secret Key]' -H 'Content-Type: application/json' |
|
|
|
|
|
|
langchain调用千帆
import os os.environ["qianfan_ak"] = "JYAUgr51d...." os.environ["qianfan_sk"] = "Gnq0lyCq6...."
# 其它模型分装在 langchain_community 底包中
from langchain_community.chat_models import QianfanChatEndpoint
from langchain_core.messages import HumanMessage
import os
# 需要开通一个模型服务
# https://console.bce.baidu.com/qianfan/ais/console/applicationConsole/application
llm = QianfanChatEndpoint(
qianfan_ak=os.getenv('qianfan_ak'),
qianfan_sk=os.getenv('qianfan_sk')
)
messages = [
HumanMessage(content="你是谁")
]
ret = llm.invoke(messages)
print(ret.content)
您好,我是百度研发的知识增强大语言模型,中文名是文心一言,英文名是ERNIE Bot。
我能够与人对话互动,回答问题,协助创作,高效便捷地帮助人们获取信息、知识和灵感。
|
|
|
|
|
|
|
|
ZeeLin
|
- https://desearch.cn/
- http://www.knover.cn
-

|
|
|
|
|
|
|
|
|
|
|
|
|
|
参考