pandas简介
pandas 官方 api pandas中文网 针对2维数据,也叫面板数据,类似于数据库中的二维关系表, 针对数据分析领域, 擅长列处理,处理行也没问题, 如果你熟悉SQL,那么SQL能做的,pandas都能做, 常用数据处理需要的功能,pandas中都已经提供了 |
#最大显示行数
pd.set_option('display.max_rows',200)
------------------------------------------------------------------------- |
|
|
|
|
|
|
pandas 包含
list_max_tid=["11","12"] a[a["交易ID"].isin(list_max_tid)] 取反 # 使用 ~ 操作符结合 isin 方法 df_filtered = df[~df['A'].isin([2, 4])] print(df_filtered) |
|
正则表达式 判断Pandas中的某一列的值,是否包含keys=['数学','文化']中的某个或多个元素?
import pandas as pd
# 假设你有一个DataFrame df
data = {
'student_name': ['张三', '李四', '王五'],
'college_major': ['数学与应用数学', '文化艺术', '计算机科学']
}
df = pd.DataFrame(data)
# 指定要检查的关键词列表
keys = ['数学', '文化']
# 使用apply和lambda函数,结合any和str.contains来检查每一行
# 注意:这里使用'|'.join(keys)来构建一个正则表达式,表示匹配任何一个关键词
df['contains_keyword'] = df['college_major'].apply(lambda x: any(key in x for key in keys))
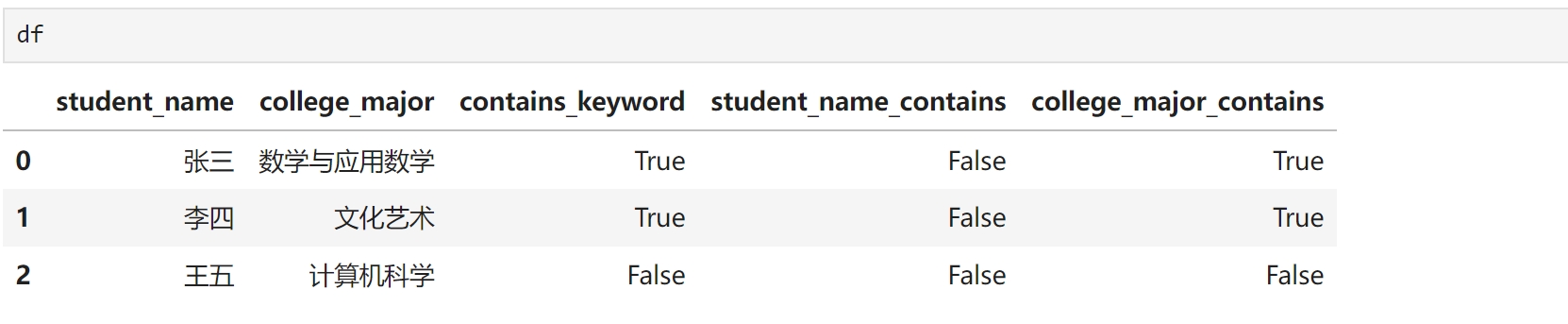
选取指定列 df[df["contains_keyword"]][["student_name","college_major"]] 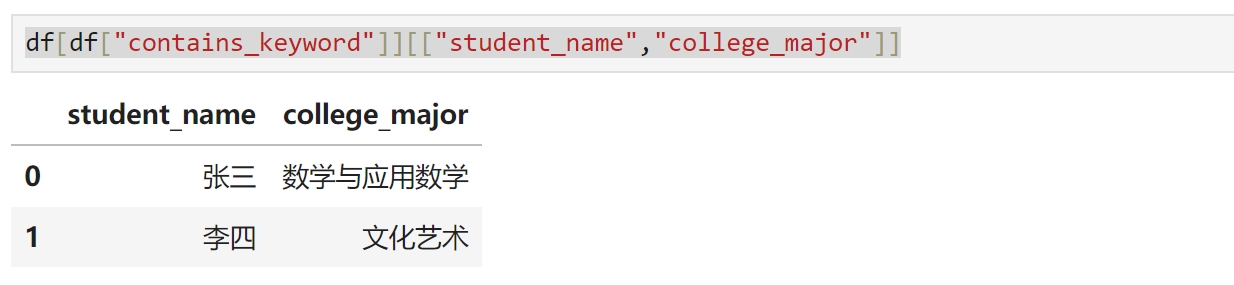
# 检查多个列是否包含关键词
df[['student_name_contains', 'college_major_contains']] = df[['student_name', 'college_major']].apply(lambda x: x.str.contains('|'.join(keys), na=False)).astype(bool)
df

df[df["contains_keyword"] & df["college_major_contains"]][["student_name","college_major"]] 
|
import pandas as pd
# 示例数据
data = {
'column_name': ['apple', 'banana', 'apricot', 'blueberry', 'apricot pie', 'avocado']
}
# 创建DataFrame
df = pd.DataFrame(data)
# 定义要查找的前缀
prefix = 'ap'
# 使用str.startswith方法和sum来统计个数
count = df[df['column_name'].str.startswith(prefix)].shape[0]
print(f"以'{prefix}'开头的字符串个数: {count}")
以'ap'开头的字符串个数: 3 |
|
|
|
|
pandas Index
import pandas as pd data = pd.DataFrame([[1,2,3],[1,2,3],[1,2,3]],columns=["a","b","c"]) data.columns Index(['a', 'b', 'c'], dtype='object') data.columns[[2,0]] Index(['c', 'a'], dtype='object') |
reset_index(drop=True):重置索引,索引重新从0开始编号 。 reset_index():将原来的Index作为一个新列,然后添加一个新的从0开始编号的index drop=True删除原索引,否则将原索引添加为新列
import pandas as pd
# 创建一个示例DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35]}
df = pd.DataFrame(data, index=[2, 3, 4])
print("原始DataFrame:")
print(df)
# 重置索引
df_reset = df.reset_index(drop=True)
print("\n重置索引后的DataFrame:")
print(df_reset)
import pandas as pd
# 创建一个示例DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35]}
df = pd.DataFrame(data)
# 将索引设置为某一列的值(例如'Name'),然后删除该列
df.set_index('Name', inplace=True)
print("Before reset_index:")
print(df)
重置为默认的整数索引
df.reset_index(inplace=True)
print("After reset_index:")
print(df)
重置索引的同时保留原来的索引列,可以使用 drop=False 参数
df.reset_index(drop=False, inplace=True)
print("After reset_index (dropping=False):")
print(df)
|
import pandas as pd
# 创建一个示例Series
data = {'a': 1, 'b': 2, 'c': 3}
s = pd.Series(data)
# 获取索引
index = s.index
print("Index:", index)
# 获取值
values = s.values
print("Values:", values)
Index: Index(['a', 'b', 'c'], dtype='object') Values: [1 2 3] tolist()
index_list = s.index.tolist()
values_list = s.values.tolist()
print("Index as list:", index_list)
print("Values as list:", values_list)
Index as list: ['a', 'b', 'c'] Values as list: [1, 2, 3] |
import pandas as pd
# 创建一个示例 DataFrame
df = pd.DataFrame({
'A': [1, 2, 3, 4],
'B': [5, 6, 7, 8]
}, index=[0, 1, 2, 3])
# 使用 drop 方法删除索引为 2 的行
df_dropped = df.drop(2) # 默认 axis=0,表示删除行
# 如果想要原地修改 DataFrame,可以使用 inplace=True
# df.drop(2, inplace=True)
print(df_dropped)
indices_to_drop = [2] # 要删除的索引列表 df_dropped = df.drop(indices_to_drop) print(df_dropped) |
import pandas as pd
# 创建一个示例 DataFrame
df = pd.DataFrame({
'A': [1, 2, 3, 4, 5],
'B': [5, 6, 7, 8, 9]
}, index=['a', 'b', 'c', 'd', 'e'])
# 定义一个索引列表,表示我们想要检索的行
index_list = ['a', 'c', 'e']
# 使用 .loc[] 方法按索引列表检索数据
selected_rows = df.loc[index_list]
print(selected_rows)
A B
a 1 5
c 3 7
e 5 9
如果你只想要检索特定的列,你可以在.loc[]方法中同时指定行索引和列标签,例如: # 检索特定索引和列的数据 selected_data = df.loc[index_list, ['A']] # 注意这里列标签需要放在一个列表中 print(selected_data) |
|
差集操作(difference) import pandas as pd # 创建两个示例索引 index1 = pd.Index(['a', 'b', 'c', 'd']) index2 = pd.Index(['b', 'd', 'e']) # 使用difference方法获取差集 result_index = index1.difference(index2) print(result_index) Index(['a', 'c'], dtype='object') 布尔索引 # 使用~运算符和isin方法获取不在index2中的index1元素 result_index = index1[~index1.isin(index2)] print(result_index) Index(['a', 'c'], dtype='object') |
|
union import pandas as pd index1 = pd.Index(['a', 'b', 'c']) index2 = pd.Index(['c', 'd', 'e']) result_index = index1.union(index2) print(result_index) # Index(['a', 'b', 'c', 'd', 'e'], dtype='object') concatenate或+运算符 # 使用pd.concat() result_index = pd.concat([index1, index2]) print(result_index) # 或者(但请注意,这种方式可能在未来的Pandas版本中不再受支持) # result_index = index1 + index2 # print(result_index) 输出将是(包含重复项): Index(['a', 'b', 'c', 'c', 'd', 'e'], dtype='object') intersection方法 虽然这不是合并,但提到索引的合并时,有时人们也会考虑交集。 intersection方法返回两个索引中共有的元素。 result_index = index1.intersection(index2) print(result_index) # Index(['c'], dtype='object') |
import pandas as pd
# 创建一个示例Index
original_index = pd.Index(['a', 'b', 'c', 'd'])
# 创建original_index的一个副本
copied_index = original_index.copy()
# 输出原始索引和副本以验证它们是不同的对象
print("Original Index:", original_index)
print("Copied Index:", copied_index)
# 修改副本中的一个元素(这不会影响原始索引)
copied_index[0] = 'z'
# 再次输出原始索引和副本以查看修改效果
print("\nAfter Modification:")
print("Original Index (unchanged):", original_index)
print("Copied Index (modified):", copied_index)
Original Index: Index(['a', 'b', 'c', 'd'], dtype='object') Copied Index: Index(['a', 'b', 'c', 'd'], dtype='object') After Modification: Original Index (unchanged): Index(['a', 'b', 'c', 'd'], dtype='object') Copied Index (modified): Index(['z', 'b', 'c', 'd'], dtype='object') 如你所见,修改副本中的元素并没有影响到原始索引, 这证明了copy()方法确实创建了一个新的、独立的Index对象。 请注意,虽然在这个简单的例子中我们直接修改了索引的一个元素 (这通常不是推荐的做法,因为索引应该是不可变的), 但在实际应用中,你更可能会通过对副本进行其他操作(如添加、删除元素或重新排序)来利用这个副本。 在这些情况下,确保原始索引保持不变是非常重要的。 |
|
Examples
--------
>>> df = pd.DataFrame({'month': [1, 4, 7, 10],
... 'year': [2012, 2014, 2013, 2014],
... 'sale': [55, 40, 84, 31]})
>>> df
month year sale
0 1 2012 55
1 4 2014 40
2 7 2013 84
3 10 2014 31
Set the index to become the 'month' column:
>>> df.set_index('month')
year sale
month
1 2012 55
4 2014 40
7 2013 84
10 2014 31
Create a MultiIndex using columns 'year' and 'month':
>>> df.set_index(['year', 'month'])
sale
year month
2012 1 55
2014 4 40
2013 7 84
2014 10 31
Create a MultiIndex using an Index and a column:
>>> df.set_index([pd.Index([1, 2, 3, 4]), 'year'])
month sale
year
1 2012 1 55
2 2014 4 40
3 2013 7 84
4 2014 10 31
Create a MultiIndex using two Series:
>>> s = pd.Series([1, 2, 3, 4])
>>> df.set_index([s, s**2])
month year sale
1 1 1 2012 55
2 4 4 2014 40
3 9 7 2013 84
4 16 10 2014 31
df = df.reset_index() - 恢复索引 ------------------------------------------------------------------------------ |
pandas Series
|
可以将Series看作一个列表/数组,只是它针对数据分析且功能强大
import pandas as pd
a=pd.Series(data=[1,2,3,3,2,1])
print(a[0])
print(a[5])
for v in a:
print(v)
与列表/数组不同的是,Series打印出来是带索引的,意在强调每个值都是一行 0 1 1 2 2 3 3 3 4 2 5 1 dtype: int64 |
import pandas as pd data_pd = pd.DataFrame([["湘灵",23],["白居易",27],["王阳明",27]],columns=["name","age"]) data_pd 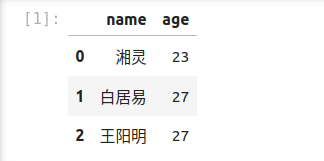
data_pd["name"]
0 湘灵
1 白居易
2 王阳明
Name: name, dtype: object
type(data_pd["name"])
pandas.core.series.Series
#多列是DataFrame
data_pd[data_pd["name"].eq("王阳明")]
name age
2 王阳明 27
type(data_pd[data_pd["name"].eq("王阳明")])
pandas.core.frame.DataFrame
#单列才是Series
type(data_pd[data_pd["name"].eq("王阳明")]["name"])
pandas.core.series.Series
重点是,这里只有一个数据,但index为2,且为它在原DataFrame中的index一致
#重点是,这里只有一个数据,但index为2,且为它在原DataFrame中的index一致
data_pd[data_pd["name"].eq("王阳明")]["name"]
2 王阳明
Name: name, dtype: object
若不需要所要的数值处于原DataFrame的第几行,转化为列表再取值
data_pd[data_pd["name"].eq("王阳明")]["name"][2]
'王阳明'
data_pd[data_pd["name"].eq("王阳明")]["name"].tolist()
['王阳明']
|
|
将Series作为新列添加到DataFrame
import pandas as pd
# 创建一个示例DataFrame
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6]
})
# 创建一个与DataFrame索引相匹配的Series
new_column = pd.Series([7, 8, 9], index=df.index)
# 将Series作为新列添加到DataFrame
df['C'] = new_column
print(df)
A B C
0 1 4 7
1 2 5 8
2 3 6 9
将Series作为新行添加到DataFrame # 假设我们想要添加一行,其值对应于新的Series # 但是,我们首先需要确保Series的索引是列名 new_row_index = ['A', 'B', 'C'] # 这应该是DataFrame的列名 new_row_values = [10, 11, 12] # 这是新行的值 # 创建一个新的Series,其索引是列名 new_row = pd.Series(new_row_values, index=new_row_index) # 为了将Series作为行添加到DataFrame,我们需要将其转置为DataFrame,然后合并 new_row_df = new_row.to_frame().T # 使用concat来合并DataFrame和新的行(作为DataFrame) df = pd.concat([df, new_row_df], ignore_index=True) # ignore_index=True用于重置索引 # 注意:上面的方法会改变原有的索引,如果你想要保持原有的索引并添加一个新行, # 你可能需要手动设置索引,或者使用其他方法(如loc,但loc通常用于更新现有索引的行)。 # 在这个例子中,我们简单地重置了索引。 print(df)
A B C
0 1 4 7
1 2 5 8
2 3 6 9
3 10 11 12
|
s3 = s2[columns_to_add] df3 = s3.to_frame().T df = pd.concat([df, df3], axis=1) df[:3] ------------------------------------------------------------------------------- |
|
|
pandas列处理
列的数据类型
pandas的 每一列的类型 都是 pd.Series类型
Series直译就是序列,一个功能强大的列表
pd.DataFrame的data可以是:
列表(Python的list,numpy.ndarray,pd.Series等),
字典,
数据类
```python
>>> df2 = pd.DataFrame(np.array(
[
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]), columns=['a', 'b', 'c'])
>>> df2
a b c
0 1 2 3
1 4 5 6
2 7 8 9
```
```python
>>> d = {'col1': [0, 1, 2, 3], 'col2': pd.Series([2, 3], index=[2, 3])}
>>> pd.DataFrame(data=d, index=[0, 1, 2, 3])
col1 col2
0 0 NaN
1 1 NaN
2 2 2.0
3 3 3.0
```
drop删除一行或一列
```python # 方法1:axis=1表示列维度,也是第2维,因为第1维为行 dfDropCol = df.drop(['id'], axis=1) # 方法2: dfDropCol = df.drop(columns=['id']) ``` 删除索引为 [0,1]的行 ``` dfDropRow = df.drop([0, 1]) ```
列读取列遍历
```python
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.rand(2,3),columns=list("ABC"))
print(df["A"])
print(df.A)
```
```
0 0.146550
1 0.420485
Name: A, dtype: float64
0 0.146550
1 0.420485
Name: A, dtype: float64
```
### 列遍历
print(df2.columns.to_list())
for colname in df2:
print(df2[colname])
列的添加与合并
### 列添加
```python
import pandas as pd
import numpy as np
a = np.random.normal(5,1,[5,2])
b = pd.DataFrame(a,columns=list("AB"))
print(b)
b[1] = 5.0
b["C"] = 8.0
print(b)
```
```
A B
0 4.653300 6.522095
1 6.675067 4.827522
2 5.166797 6.521645
3 4.232393 3.549264
4 4.234110 5.204987
A B 1 C
0 4.653300 6.522095 5.0 8.0
1 6.675067 4.827522 5.0 8.0
2 5.166797 6.521645 5.0 8.0
3 4.232393 3.549264 5.0 8.0
4 4.234110 5.204987 5.0 8.0
```
### 列合并
```python
# way1: 将两列合并成新的列
df["new_col"] = df["col1"] + df["col2"]
# way2: 将两列合并成新的列,并在中间插入间隔符
df["new_col"] = df["col1"] + "-" + df["col2"]
```
按顺序插入列
```python
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.rand(2,3),columns=list("ABC"))
cl = df.columns.to_list()
print(cl)
c_new = ["A","a","B","b","C"]
df2 = pd.DataFrame(columns=c_new)
for col in c_new:
if col in cl:
df2[col] = df[col]
else:
df2[col] = 0
print(df2)
```
```
['A', 'B', 'C']
A a B b C
0 0.963692 0 0.835339 0 0.405929
1 0.133619 0 0.559981 0 0.507644
```
读取指定的列
import pandas as pd
import numpy as np
a = np.random.normal(2,1,[2,3])
b = pd.DataFrame(a,columns=list("ABC"))
b.to_csv("a.csv")
data = pd.read_csv("a.csv",usecols=["A","C"])
data
A C
0 1.206238 3.579832
1 1.972719 1.071630
# 按索引读,虽然最初指定只有ABC三列,但写入 CSV后,pandas自动添加一个索引列,所以就多了一列
data = pd.read_csv("a.csv",usecols=[0,2])
data
Unnamed: 0 B
0 0 2.716156
1 1 1.730993
pandas行处理
|
取前2行
import pandas as pd
import numpy as np
df2 = pd.DataFrame(np.array(
[
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]), columns=['a', 'b', 'c'])
df2[:2]
a b c
0 1 2 3
1 4 5 6
|
|
取一行数据 iloc[]只能按数字索引取一行 loc[]可以按字符串索引取一行 df2 = pd.DataFrame( [ [1, 2, 3], [4, 5, 6], [7, 8, 9] ], columns=['a', 'b', 'c']) print(type(df2.iloc[0])) # class 'pandas.core.series.Series' print(df2.iloc[0]) """ a 1 b 2 c 3 Name: 0, dtype: int64 """ 每一行也是一个Series类型 第一行的第一列 data_pd.iloc[0][0] |
|
取切片
import pandas as pd
import math
df2 = pd.DataFrame(
[
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
], columns=['a', 'b', 'c'])
df2[1:2]
a b c
1 4 5 6
df2[1:1] 为空
df2[1:5]
a b c
1 4 5 6
2 7 8 9
import pandas as pd
import math
df2 = pd.DataFrame(
[
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
], columns=['a', 'b', 'c'])
shape=df2.shape
rownum = shape[0]
interval = 2
epoch1 = math.ceil(rownum / interval)
start_index = 0
for i in range(epoch1):
end_index = start_index + interval
row = df2[start_index:end_index]
start_index = end_index
print(row)
|
|
行遍历
shape=df2.shape
rownum = shape[0]
colnum = shape[1]
for i in range(rownum):
row = df2.iloc[i]
print(row)
|
|
行拼接pd.concat,1维
import pandas as pd
a = pd.DataFrame()
b = pd.DataFrame(data=[1,2,3])
c = pd.DataFrame(data=[4,5,6])
a = pd.concat([a,b],axis=0)
a
0
----------
0 1
1 2
2 3
a = pd.concat([a,c],axis=0)
a
0
----------
0 1
1 2
2 3
0 4
1 5
2 6
行拼接pd.concat,2 维
import pandas as pd
a = pd.DataFrame()
b = pd.DataFrame(data=[[1,2,3,4]],columns=["tid","cardno","ids","times"])
a = pd.concat([a,b],axis=0)
a
tid cardno ids times
0 1 2 3 4
a = pd.concat([a,b],axis=0)
a
tid cardno ids times
0 1 2 3 4
0 1 2 3 4
行拼接pd.concat:不存在的列自动为NaN
import pandas as pd
a = {"aa":1,"bb":2}
b = {"bb":20,"aa":10,"cc":30}
df1 = pd.DataFrame(data=a,index=[0])
df2 = pd.DataFrame(data=b,index=[1])
print(pd.concat([df1,df2]))
"""
aa bb cc
0 1 2 NaN
1 10 20 30.0
"""
|
import pandas as pd
# 假设 corr_matrix 是已经存在的 DataFrame
# 这里只是一个示例,你需要用实际的 corr_matrix 替换
corr_matrix = pd.DataFrame({
'A': [0.1, 0.2, 0.3],
'B': [0.4, 0.5, 0.6],
'C': [0.7, 0.8, 0.9]
}, index=['A', 'B', 'C'])
# 初始化空的 DataFrame
corr_pairs = pd.DataFrame(columns=['col1', 'col2', 'correlation'])
# 示例:添加一行数据
new_row = pd.DataFrame({
'col1': corr_matrix.columns[0],
'col2': corr_matrix.columns[1],
'correlation': corr_matrix.iloc[0, 1]
}, index=[0],columns=['col1', 'col2', 'correlation']) # 必须指定索引,因为 pd.concat 默认按索引合并
# 使用 pd.concat 添加新行
if corr_pairs.shape[0] == 0:
corr_pairs = new_row
else:
corr_pairs = pd.concat([corr_pairs, new_row], ignore_index=True)
|
|
使用 loc[] 按标签选取行
import pandas as pd
# 创建示例DataFrame
df = pd.DataFrame({
'A': [1, 2, 3],
'B': ['x', 'y', 'z']
}, index=['row1', 'row2', 'row3'])
# 选取单个行
row1_data = df.loc['row1'] # 返回Series
print(row1_data)
# 选取多行(通过列表)
rows_data = df.loc[['row1', 'row3']] # 返回DataFrame
print(rows_data)
# 使用切片(按标签范围)
sliced_rows = df.loc['row1':'row3'] # 包含起始和结束标签
print(sliced_rows)
A 1
B x
Name: row1, dtype: object
A B
row1 1 x
row3 3 z
A B
row1 1 x
row2 2 y
row3 3 z
使用 iloc[] 按位置选取行 # 选取第一行(位置0) first_row = df.iloc[0] # Series # 选取多行(位置0和2) selected_rows = df.iloc[[0, 2]] # DataFrame # 使用切片(位置范围) sliced_rows = df.iloc[0:2] # 不包含结束位置(左闭右开) 使用布尔索引
# 选取索引包含'1'的行
mask = df.index.str.contains('1')
filtered_rows = df[mask]
直接通过 index 查询 # 精确匹配单个索引 row2_data = df[df.index == 'row2'] # 匹配多个索引 rows_data = df[df.index.isin(['row1', 'row3'])] |
|
iterrows(最常用,但慢) for idx, row in df.iterrows(): # row 是一个 Series,列名即键 print(row['colA'], row['colB']) - 修改 row 不会 写回原表,需要回写请用 df.loc[idx, 'colA'] = new_val。 - 大数据量时速度明显下降。 itertuples(更快,只读场景首选)
```
for tup in df.itertuples(index=True): # index=True 把索引也带出来
print(tup.Index, tup.colA, tup.colB) # 列名自动变成属性
```
```
返回的是 namedtuple,访问比 Series 快 5~10 倍。
列名里如果有空格或中文,属性访问会失败,可用 getattr(tup, '列 名')。
真·不要循环:向量化才是正统
只要计算能改成整列操作,就别写 for:
```
```
# 坏
for idx, row in df.iterrows():
df.loc[idx, 'new'] = row['a'] + row['b']
# 好
df['new'] = df['a'] + df['b']
```
|
```
data_len = len(data)
for i in range(data_len):
row = data.iloc[i]
vec = row['vec']
label = row['label']
others = data.drop(i)
```
```
data = self.df.copy()
data_len = len(self.tokenized_texts)
pc.lg(f"data.columns: {data.columns.tolist()}")
for i in range(data_len):
new_query = data.iloc[i][self.text_name]
label = data.iloc[i][self.label_name]
others = data.drop(data.index[i])
```
如果用列表实现
```
data = self.df.copy()
data_len = len(self.tokenized_texts)
pc.lg(f"data.columns: {data.columns.tolist()}")
for i in range(data_len):
new_query = data.iloc[i][self.text_name]
label = data.iloc[i][self.label_name]
others = data.drop(data.index[i])
tokenized_query = self.tokenized_texts[i]
tokenized_texts = [doc for j, doc in enumerate(self.tokenized_texts) if j != i]
```
|
import pandas as pd
df = pd.read_csv('data.csv')
# 按单列去重
df_uni = df.drop_duplicates(subset=['colA'])
# 按多列组合去重
df_uni = df.drop_duplicates(subset=['colA', 'colB'])
# 保留最后一条重复记录
df_uni = df.drop_duplicates(subset=['colA'], keep='last')
# 直接覆盖原表
df.drop_duplicates(subset=['colA'], inplace=True)
df_uni = df.drop_duplicates(subset=['colA']).reset_index(drop=True) cols = ['colA', 'colB'] df_mini = df[cols].drop_duplicates() 易踩坑提醒 空值(NaN)会被当成「相同」,即 NaN == NaN 视为 True; 如果希望把 NaN 当不同值,先 df.fillna(...) 或者用 df.groupby().first() 自己控制。 如果数据量极大(千万行以上),drop_duplicates 会先排序,内存可能爆炸; 可分批处理或先 df.sort_values(...) 再手动滑动窗口。 字符串前后有空格会导致“肉眼看不出的重复”,先去空格: df['colA'] = df['colA'].str.strip() |
|
|
pandas读写CSV
|
默认列名:不指定列名时,默认0为表头,覆盖式写入
import pandas as pd
a=pd.DataFrame([1,2,3])
a.to_csv("a.csv",index=False)
a.csv文件中的内容为
0
1
2
3
这个0是默认的列名,并且读取csv时,会默认将第一行当作表头,就是列
import pandas as pd
a=pd.DataFrame([1])
a.to_csv("a.csv",index=False)
0
1
|
|
不保存索引
通常存储时不保存索引,DataFrame读取csv时会自动为其封装索引
df = pd.DataFrame(np.random.randn(6,4))
df.to_csv("a.csv",index=False)
读大CSV文件,要把 low_memory 关掉
df = pd.read_csv('somefile.csv', low_memory=False)
pandas读csv前缀0的问题
如果数字字符串有前缀0,可以100%确认pandas在写入csv时是带有前缀0的;
那为什么打开csv看不到0?
这是csv的问题,
csv默认在显示时将数字型的字符串转为数字,并以科学记数法显示
但csv保留着最初的带有0的数字型字符串,看到的并不是真实存储的样子
比如,你看的是3E+6,实际上将csv文件以txt格式文本工具打开,
你看到的将是0003000000,仍是那个有前缀0的数字型字符串
pandas读取这样的csv时,加上converters可以重新读入带前缀0的数字型字符串
data=pd.read_csv('test.csv',converters={u'ID':str})
|
|
无表头:pandas读取没有表头的csv
设置header=None会认为第一行也是数据
df2.to_csv("a.csv", header=None)
|
|
分块读取:pandas分块读取csv
import pandas as pd
df2 = pd.DataFrame(
[
[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
[1, 2, -4],
[4, 5, 0],
[7, -9, 9],
], columns=['a', 'b', 'c'])
df2.to_csv("a.csv",index=False)
data = pd.read_csv("a.csv",usecols=['a','b'],iterator=True)
it = data.get_chunk(2) # 读2行
it
a b
0 1 2
1 4 5
it = data.get_chunk(3) # 读3行
it
a b
2 7 8
3 1 2
4 4 5
try:
while True:
it = data.get_chunk(20)
print(it)
except Exception as e:
print('over')
指定chunksize
import pandas as pd
df2 = pd.DataFrame(
[
[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
[1, 2, -4],
[4, 5, 0],
[7, -9, 9],
], columns=['a', 'b', 'c'])
df2.to_csv("a.csv",index=False)
data = pd.read_csv("a.csv",usecols=['a','b'], chunksize=5)
type(data)
pandas.io.parsers.readers.TextFileReader
for rows in data:
print(rows)
a b
0 1 2
1 4 5
2 7 8
3 1 2
4 4 5
a b
5 7 -9
|
|
覆盖写:如果被写文件有内容,会被清除重写
import pandas as pd
df2 = pd.DataFrame(
[
[1, 2, 3],
[4, 5, 6]
], columns=['a', 'b', 'c'])
df2.to_csv("a.csv",index=False)
!cat a.csv
a,b,c
1,2,3
4,5,6
|
|
无表头转str
import pandas as pd
# 假设没有表头,文件有两列数据
# 使用read_csv读取文件,并将所有列强制转换为字符串类型
df = pd.read_csv('data.csv', header=None, dtype=str)
print(df)
print(df.dtypes)
|
|
NA等缺失值
import pandas as pd
data_pd = pd.DataFrame([["NA"]],columns=["aa"])
data_pd.to_csv("a.csv",index=False)
!cat a.csv
aa
NA
print(pd.read_csv("a.csv"))
aa
0 NaN
读入的是NA,读出来却是NaN
import pandas as pd
data_pd = pd.read_csv('a.csv', keep_default_na=False, na_values=[])
data_pd
aa
0 NA
在使用Pandas读取数据时,比如从CSV、Excel或TXT文件中读取数据,经常需要处理缺失值问题。 Pandas默认会将空值(如CSV中的空白单元格)解读为NaN(Not a Number)。 如果你希望Pandas读取空值时不将其转换为NaN,而是保留为空字符串或其他特定值, 可以通过调整读取函数的参数来实现。
CSV文件
使用pandas.read_csv()时,可以通过设置
keep_default_na=False和na_values=[]来改变空值处理方式。
这样,Pandas就不会将任何默认的字符串(如'NaN', 'NA', ''等)视为缺失值。
import pandas as pd
df = pd.read_csv('your_file.csv', keep_default_na=False, na_values=[])
Excel文件
类似地,使用pandas.read_excel()时,可以同样设置keep_default_na=False来避免将空字符串识别为NaN。
df = pd.read_excel('your_file.xlsx', keep_default_na=False)
TXT/其他分隔符文件
对于文本文件,确保正确设置了分隔符,并且可以使用与CSV相同的方法处理空值。
df = pd.read_csv('your_file.txt', sep='\t', keep_default_na=False, na_values=[])
# 如果是制表符分隔的文件,可以使用'\t'作为sep
当你将keep_default_na设置为False时,Pandas将不会把任何默认的空值标记(如'NaN', 'NA')自动识别为缺失值。 na_values=[]表示不额外指定任何值为缺失值, 如果你想自定义哪些值应该被识别为NaN,可以在这里提供一个列表。 保留空字符串可能会对后续数据分析造成影响,特别是在进行数值计算或者统计时, 因此在决定是否保留空字符串前,请考虑你的具体分析需求。 |
|
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x87 in position 10: invalid start byte
pd.read_csv("aa.csv",encoding='gbk')
|
|
以空格为分隔符
import pandas as pd
df = pd.read_csv('untitled.txt', sep='\s+', header=None)
import pandas as pd
y = pd.DataFrame([[1,2,3],[1,2,3]],columns=['a','b','c'])
y.to_csv("a.csv",index=False,sep='~')
------------------------------------------------------------------------------------ |
import pandas as pd
def append_csv(new_data, file_path):
"""追加写csv文件,适合小数据量
"""
if os.path.exists(file_path):
# 读取现有的 CSV 文件
existing_df = pd.read_csv(file_path)
# 将新数据追加到现有的 DataFrame
updated_df = pd.concat([existing_df, new_data], ignore_index=True)
else:
updated_df = new_data
# 将更新后的 DataFrame 写回到 CSV 文件
updated_df.to_csv(file_path, index=False)
|
df = df.rename(columns=lambda x: x.lower()) |
|
读取部分列:usecols 技术上可以混合使用列名和列索引,但出于可读性和一致性的考虑,通常不建议这样做。
# 这里 'name' 是列名,2 是列索引
df = pd.read_csv('data.csv', usecols=['name', 2])
print(df)
这种方法可能会导致混淆,因此最好坚持使用一种方法(列名或列索引)。 |
|
单sheet
pip install openpyxl
```
df.to_excel('结果.xlsx', index=False) # index=False 表示不写入行索引
```
多sheet
```
with pd.ExcelWriter('结果.xlsx') as w:
df1.to_excel(w, sheet_name='表1', index=False)
df2.to_excel(w, sheet_name='表2', index=False)
```
|
|
|
pandas分批操作
import pandas as pd
# 从CSV文件分批读取
chunk_size = 10000 # 每批的行数
chunks = pd.read_csv('large_file.csv', chunksize=chunk_size)
for chunk in chunks:
# 处理每个chunk
process(chunk) # 替换为你的处理函数
|
batch_size = 5000 # 每批的行数
total_rows = len(df)
for i in range(0, total_rows, batch_size):
batch = df.iloc[i:i+batch_size]
process(batch) # 处理当前批次
|
import numpy as np
# 将DataFrame分成4个批次
batches = np.array_split(df, 4)
for batch in batches:
process(batch)
|
def batch_generator(df, batch_size):
for i in range(0, len(df), batch_size):
yield df.iloc[i:i+batch_size]
# 使用生成器
for batch in batch_generator(df, 10000):
process(batch)
|
import dask.dataframe as dd
# 从多个文件创建Dask DataFrame
ddf = dd.read_csv('large_data/*.csv')
# 像Pandas一样操作,但处理是分批进行的
result = ddf.groupby('column').mean().compute()
|
pandas 时间
python的时间数据转化到pandas中后,可直接做差,其格式显示为 0 days 00:01:13 t = data.iloc[i+1]['time'] - data.iloc[i]['time'] t.seconds # 时间差转化为秒 |
for t in pc.col_type.date_type:
df[t] = df[t].dt.strftime('%Y-%m-%d %H:%M:%S')
|
|
|
|
|
|
|
pandas 排序
# 将数据按 卡号,时间 从小到大 排序 data.sort_values(by=['cardno','ctime'], inplace=True)
pandas 空值处理
|
NaN处理
import pandas as pd
a = {"aa":1,"bb":2}
b = {"bb":20,"aa":10,"cc":30}
df1 = pd.DataFrame(data=a,index=[0])
df2 = pd.DataFrame(data=b,index=[1])
data = pd.concat([df1,df2])
# print(data)
"""
aa bb cc
0 1 2 NaN
1 10 20 30.0
"""
# print(data.isnull())
"""
aa bb cc
0 False False True
1 False False False
"""
data.fillna(0,inplace=True) # 把空值填充成 0
# print(data)
"""
aa bb cc
0 1 2 0.0
1 10 20 30.0
"""
a = {"aa":3,"bb":4}
b = {"bb":3,"aa":3,"cc":3}
df1 = pd.DataFrame(data=a,index=[2])
df2 = pd.DataFrame(data=b,index=[3])
data = pd.concat([data,df1,df2])
# print(data)
"""
aa bb cc
0 1 2 0.0
1 10 20 30.0
2 3 4 NaN
3 3 3 3.0
"""
# follow fill
# print(data.fillna(method="ffill"))
"""
aa bb cc
0 1 2 0.0
1 10 20 30.0
2 3 4 30.0
3 3 3 3.0
"""
# bfill向下填充
# print(data.fillna(method="bfill"))
"""
aa bb cc
0 1 2 0.0
1 10 20 30.0
2 3 4 3.0
3 3 3 3.0
"""
输出所有包含空值的行
# 输出所有包含空值的行
# print(data[data.isnull().T.any()])
"""
aa bb cc
2 3 4 NaN
"""
import numpy as np
data.iloc[0,2] = np.nan
print(data)
"""
aa bb cc
0 1 2 NaN
1 10 20 30.0
2 3 4 NaN
3 3 3 3.0
"""
print(data.isnull())
"""
aa bb cc
0 False False True
1 False False False
2 False False True
3 False False False
"""
# pandas默认按列处理,一列有一个True, any就是True
print(data.isnull().any())
"""
aa False
bb False
cc True
dtype: boo
"""
print(data.isnull().any().sum()) # 1 ,总共有一列包含空值
print(data.isnull().T.any().sum()) # 2, 总共有两行包含空值
删除空行或空列 # dropna(axis,how,subset)方法会删除有空值的行或列, # axis为0是行,axis为1是列, # how为any时该行或列只要有一个空值就会删除,all是全都是空值才删除 # subset是一个列表,指定某些列 data.dropna(axis=0, how="any", subset=["cc"],inplace=True) data |
import pandas as pd
a = {"aa":1,"bb":2}
b = {"bb":20,"aa":10,"cc":30}
df1 = pd.DataFrame(data=a,index=[0])
df2 = pd.DataFrame(data=b,index=[1])
data = pd.concat([df1,df2])
print(data)
aa bb cc
0 1 2 NaN
1 10 20 30.0
data_nan = data[data.isnull().T.any()]
print(data_nan)
aa bb cc
0 1 2 NaN
data_nan = data[data["cc"].isnull()]
print(data_nan)
aa bb cc
0 1 2 NaN
# subset是一个列表,指定某些列
data.dropna(axis=0, how="any", subset=["cc"],inplace=True)
print(data)
aa bb cc
1 10 20 30.0
|
data_pd.fillna("",inplace=True)
indices = np.nan_to_num(indices, nan=-1) # 替换 NaN 为 -1
indices_array = np.array(indices, dtype=np.int64)
-----------------------------------------------------------------------
|
import pandas as pd # 假设 df 是你的 DataFrame df_filtered = df.dropna(subset=['指标编码', '类别']) 使用 notnull()(与 notna() 相同) df_filtered = df[df['指标编码'].notna() & df['类别'].notna()] df_filtered = df[df['指标编码'].notnull() & df['类别'].notnull()]
import pandas as pd
import numpy as np
# 示例数据
data = {
'指标编码': [1, np.nan, 3, np.nan, 5],
'类别': ['A', 'B', np.nan, 'D', 'E'],
'特征算法名': ['alg1', 'alg2', 'alg3', 'alg4', 'alg5']
}
df = pd.DataFrame(data)
df
指标编码 类别 特征算法名
0 1.0 A alg1
1 NaN B alg2
2 3.0 NaN alg3
3 NaN D alg4
4 5.0 E alg5
# 筛选指标编码和类别都不为 NaN 的行 df_filtered = df.dropna(subset=['指标编码', '类别']) print(df_filtered) 指标编码 类别 特征算法名 0 1.0 A alg1 4 5.0 E alg5 dropna(subset=['指标编码', '类别']) 会删除 指标编码 或 类别 列中任意一个为 NaN 的行。 notna() 或 notnull() 用于检查非 NaN 值,& 表示逻辑与操作。 |
|
|
pandas 空白处理
首尾空格
strip()方法,去除字符串开头和者结尾的空格, lstrip()及rstrip()分别是去除字符串开头或者结尾的空格,即可去掉B列中所有单元格首尾空格,如下: a['B'] = a['B'].str.strip() print(a.values)
去掉全部空格
replace()可以去掉字符串中包括夹在中间的所有空格,如下,对整张pandas表a进行去空格操作:
a.replace('\s+','',regex=True,inplace=True)
print(a.values)
pandas 字符串转数字空值填充
import pandas as pd
a = {"aa":"aa","bb":""}
b = {"bb":"20","aa":"10","cc":"30"}
df1 = pd.DataFrame(data=a,index=[0])
df2 = pd.DataFrame(data=b,index=[1])
data = pd.concat([df1,df2])
# print(data)
"""
aa bb cc
0 aa bb NaN
1 10 20 30
"""
for col in data:
data[col] = data[col].apply(pd.to_numeric, errors='coerce').fillna(method="bfill")
print(data)
"""
aa bb cc
0 10.0 20.0 30.0
1 10.0 20.0 30.0
"""
pandas 不重复值处理
import pandas as pd
import numpy as np
a = np.array([
["aa", "bb"],
["a1", "bb "],
["a1", "bb"],
["a2", "bb"]])
df = pd.DataFrame(a,columns=list("AB"))
print(df["A"].unique(),df["A"].nunique()) # ['aa' 'a1' 'a2'] 3
# nunique: 不重复元素个数
print(df["B"].unique(),df["B"].nunique()) # ['bb' 'bb '] 2
print(df["A"].value_counts())
"""
a1 2
aa 1
a2 1
"""
pandas 数值
# 二值编码
fat_content_dict = {'Low Fat':0, 'Regular':1, 'LF':0, 'reg':1, 'low fat':0}
combi['Item_Fat_Content'] = combi['Item_Fat_Content'].map(fat_content_dict)
pd.Series(map(lambda x: dict(Y=1, N=0)[x],
df2['c'].values.tolist()), df2['c'].index)
0 0
1 0
2 1
dtype: int64
pd.Series(np.searchsorted(['N', 'Y'], df2['c'].values), df2['c'].index) 0 0 1 0 2 1 dtype: int64 |
将所有为1的值替换为2 data = data.replace(1,2) |
|
python原生实现
import pandas as pd
import math
# 自定义函数,保留4位有效数字
def round_to_effective_digits(value, digits=4):
if value == 0:
return 0
else:
return round(value, -int(math.floor(math.log10(abs(value)))) + digits - 1)
# 示例DataFrame
data = {'A': [123.456789, 0.00012345, 987654321, -12345.6789]}
df = pd.DataFrame(data)
# 应用函数到列'A'
df['A_rounded'] = df['A'].apply(round_to_effective_digits)
print(df)
np.around
import pandas as pd
import math
# 自定义函数,保留4位有效数字
def round_to_effective_digits(value, digits=4):
if value == 0:
return 0
else:
return np.around(value,decimals=4)
# 示例DataFrame
data = {'A': [123.456789, 0.00012345, 987654321, -12345.6789]}
df = pd.DataFrame(data)
# 应用函数到列'A'
df['A'] = df['A'].apply(round_to_effective_digits)
df
简易实现 import numpy as np score = np.array([0.456789, 0.00012345, 0.987654321, 0.6789]) df["B"] = np.around(score, decimals=4) |
|
|
|
|
pandas Yes/No转0/1
import pandas as pd
import numpy as np
df2 = pd.DataFrame(np.array(
[
[1, 2, 'N'],
[4, 5, 'N'],
[7, 8, 'Y']
]), columns=['a', 'b', 'c'])
df2
a b c
0 1 2 N
1 4 5 N
2 7 8 Y
df2['c'].eq('Y').mul(1)
0 0
1 0
2 1
Name: c, dtype: int32
df2['c'].map(dict(Y=1, N=0)) 0 0 1 0 2 1 Name: c, dtype: int64
pd.Series(np.where(df2['c'].values == 'Y', 1, 0),
df2['c'].index)
0 0
1 0
2 1
dtype: int32
pandas 取对数
import numpy as np # 取log前处理一下0值 data = data.replace(0,1.0001) data1 = np.log(data.dropna()) data2 = np.log2(data.dropna()) data3 = np.log10(data.dropna())
pandas join
join 按索引连接两个数表
import pandas as pd
# 相识的年龄
data1={"name":["湘灵","白居易"],"age1":[7,11]}
df1 = pd.DataFrame(data1)
# 相爱的年龄
data2={"name":["湘灵","白居易"],"age2":[15,19]}
df2 = pd.DataFrame(data2)
data = df1.join(df2.set_index(keys=['name']), on='name')
print(data)
name age1 age2
0 湘灵 7 15
1 白居易 11 19
pandas merge
|
merge按列连接两个数表
import pandas as pd
# 相离的年龄,“798年,27岁的白居易辞别初恋湘灵:“待我高中,定回来娶你。”
data3={"name":["湘灵","白居易"],"age3":[23,27]}
df3 = pd.DataFrame(data3)
# 永别的年龄,白居易53岁时找过湘灵一次,可惜她已离开...古人寿命本就不长...
data4={"name":["湘灵","白居易"],"age4":[49,53]}
df4 = pd.DataFrame(data4)
data = df3.merge(df4)
print(data)
name age3 age4
0 湘灵 23 49
1 白居易 27 53
on='name' 可指定具体连接的列名,默认为None,表示使用相同名称的列进行连接
参数 说明
right 第一个参数:右表, DataFrame, Series, or list of DataFrame
how 拼接方式,默认inner,还有'left', 'right', 'outer'
on 默认None,自动根据 相同列 拼接
sort 是否数据排序,默认为Flase
两个表列名同但含义不同,pandas合并时会重命名它们 import pandas as pd data1_pd = pd.DataFrame([["湘灵",23,"aaa"],["白居易",27,"bbb"]],columns=["name1","age1","other"]) data2_pd = pd.DataFrame([["湘灵",23,"aaa"],["王阳明",27,"bbb"]],columns=["name2","age2","other"]) data_pd = pd.merge(data1_pd,data2_pd,left_on="name1",right_on="name2") data_pd 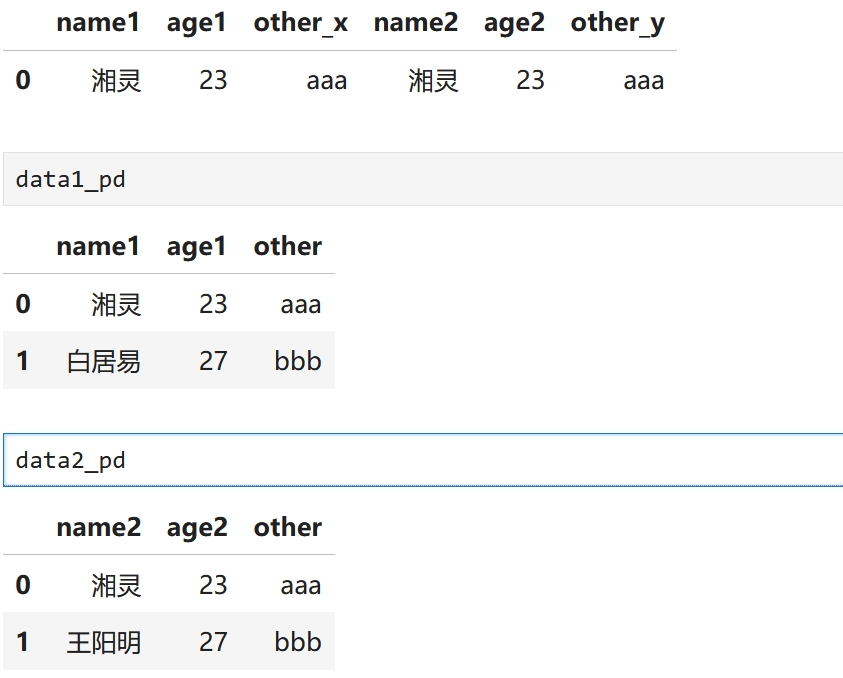
|
|
merge left join
import pandas as pd
data3={"name":["湘灵","白居易","李白"],"age3":[23,27,88]}
df3 = pd.DataFrame(data3)
data4={"name":["湘灵","白居易"],"age4":[49,53]}
df4 = pd.DataFrame(data4)
data = df3.merge(df4,how="left")
data
name age3 age4
0 湘灵 23 49.0
1 白居易 27 53.0
2 李白 88 NaN
data.fillna(0,inplace=True)
data
name age3 age4
0 湘灵 23 49.0
1 白居易 27 53.0
2 李白 88 0.0
|
|
merge相连两列要求类型相同
float转int
data = data.fillna('0').astype('int32' , errors='ignore' )
object转int
多类型时,类型为object,
pd.to_numeric(s, errors='coerce').fillna('0').astype('int64')
类型转换参考
https://blog.csdn.net/Ghjkku/article/details/123277462
|
|
不同的列名 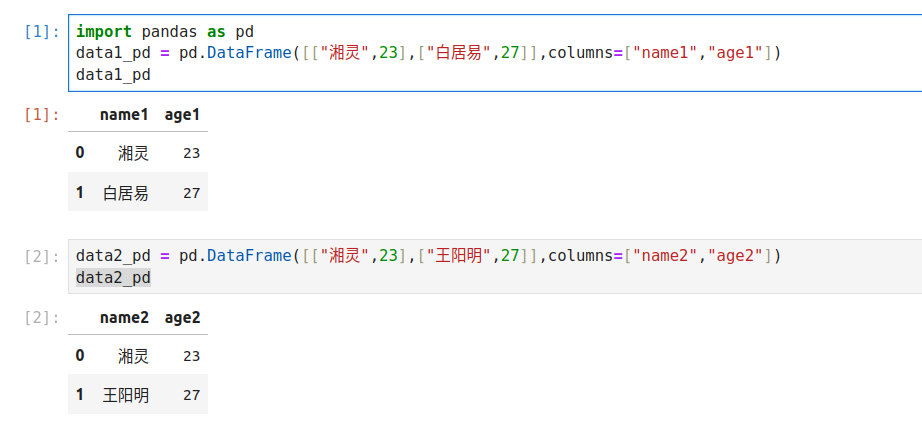
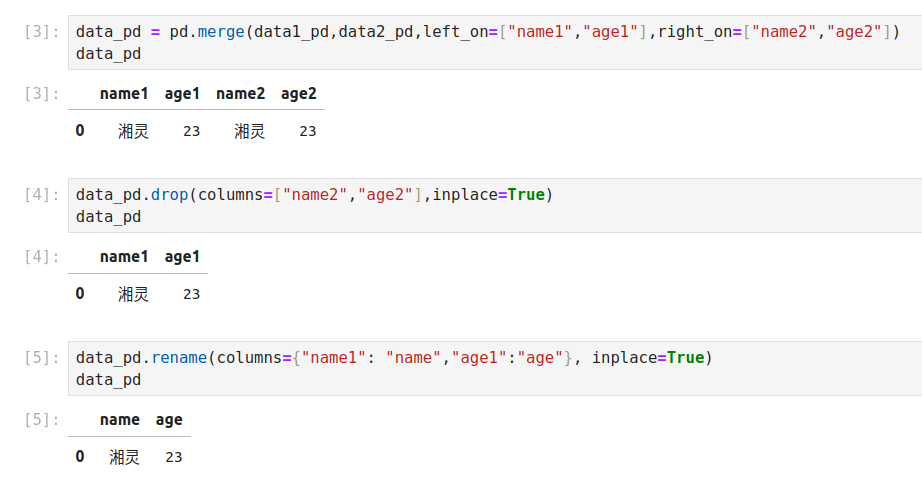
import pandas as pd
data1_pd = pd.DataFrame([["湘灵",23],["白居易",27]],columns=["name1","age1"])
data2_pd = pd.DataFrame([["湘灵",23],["王阳明",27]],columns=["name2","age2"])
data_pd = pd.merge(data1_pd,data2_pd,left_on=["name1","age1"],right_on=["name2","age2"])
data_pd.drop(columns=["name2","age2"],inplace=True)
data_pd.rename(columns={"name1": "name","age1":"age"}, inplace=True)
data_pd
相同的列名
import pandas as pd
# 示例DataFrame
df1 = pd.DataFrame({'key1': ['A', 'B', 'C', 'D'], 'key2': [1, 2, 3, 4], 'value1': [10, 20, 30, 40]})
df2 = pd.DataFrame({'key1': ['B', 'D', 'E', 'F'], 'key2': [2, 4, 5, 6], 'value2': [50, 60, 70, 80]})
df1
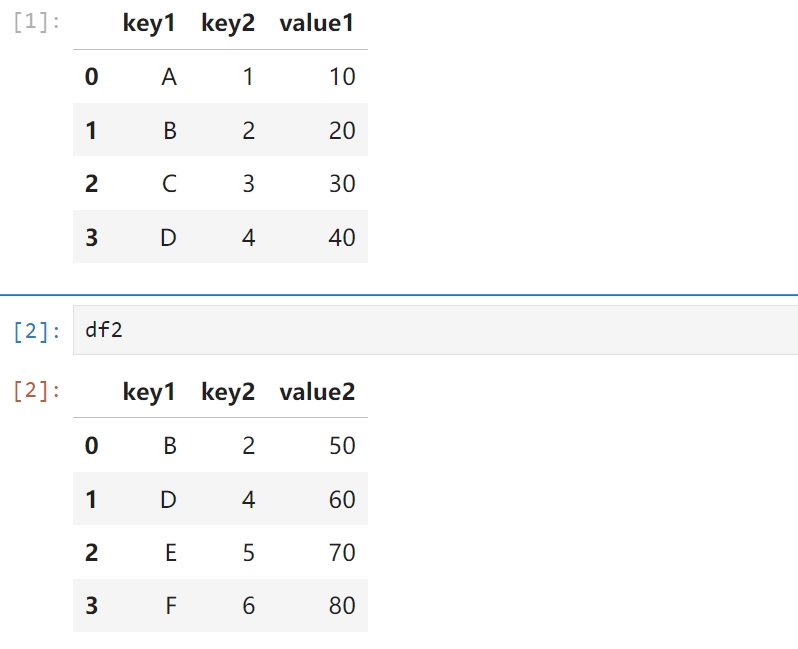
# 使用merge函数基于key1和key2合并两个DataFrame,但只保留df1的列 # 可以通过设置indicator=True来添加一个额外的列来指示每一行来自哪个DataFrame(这不是必需的) merged_df = pd.merge(df1, df2, on=['key1', 'key2'], how='inner', indicator=True) # 选择只保留df1的列 # 如果设置了indicator=True,还需要排除额外的_merge列 selected_columns = [col for col in df1.columns if col not in ['_merge']] # 排除_merge列(如果设置了) result_df = merged_df[selected_columns] print(result_df) 
在Pandas的merge函数中,indicator参数是一个布尔值(默认为False),用于在合并后的DataFrame中添加一个额外的列来标识每一行数据来自哪个DataFrame或者是否两个DataFrame中都有匹配的行。 当indicator=True时,合并后的DataFrame会包含一个名为_merge的额外列,该列包含以下三个可能的值之一: 'left_only': 只存在于左DataFrame(即第一个被合并的DataFrame)中的行。 'right_only': 只存在于右DataFrame(即第二个被合并的DataFrame)中的行。 'both': 在两个DataFrame中都存在的匹配行。 left_only: 该行指定连接的列的值(这里是key1,key2),只存在于左表 right_only:该行指定连接的列的值(这里是key1,key2),只存在于右表 |
|
单列连接 import pandas as pd data1_pd = pd.DataFrame([["湘灵",23],["白居易",27]],columns=["name1","age1"]) data2_pd = pd.DataFrame([["湘灵",23],["王阳明",27]],columns=["name2","age2"]) data_pd = pd.merge(data1_pd,data2_pd,left_on="name1",right_on="name2") data_pd name1 age1 name2 age2 0 湘灵 23 湘灵 23
data_pd.drop(columns=["name2","age2"],inplace=True)
data_pd.rename(columns={"name1": "name","age1":"age"}, inplace=True)
data_pd
name age
0 湘灵 23
|
|
两个表列名同但含义不同,pandas合并时会重命名它们 import pandas as pd data1_pd = pd.DataFrame([["湘灵",23,"aaa"],["白居易",27,"bbb"]],columns=["name1","age1","other"]) data2_pd = pd.DataFrame([["湘灵",23,"aaa"],["王阳明",27,"bbb"]],columns=["name2","age2","other"]) data_pd = pd.merge(data1_pd,data2_pd,left_on="name1",right_on="name2") data_pd
|
pandas plot
import pandas as pd import numpy as np ds = pd.Series(data=10*np.arange(10)) ds.plot()
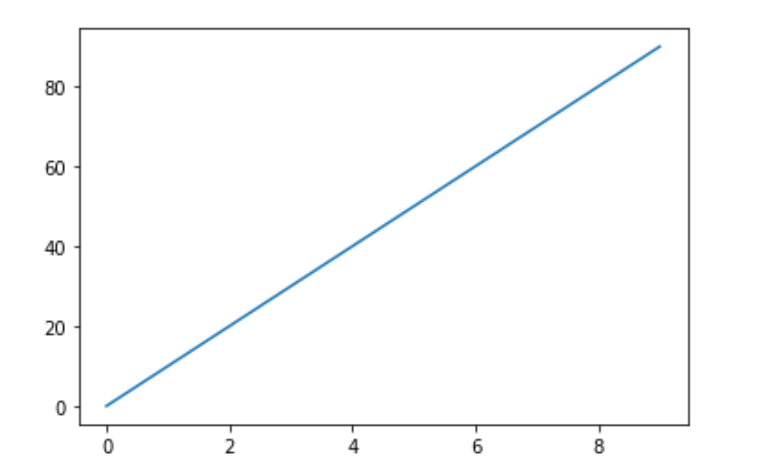
ds = pd.DataFrame(data=np.arange(10).reshape(5,2),columns=["A","B"]) ds.plot(y=["A","B"])
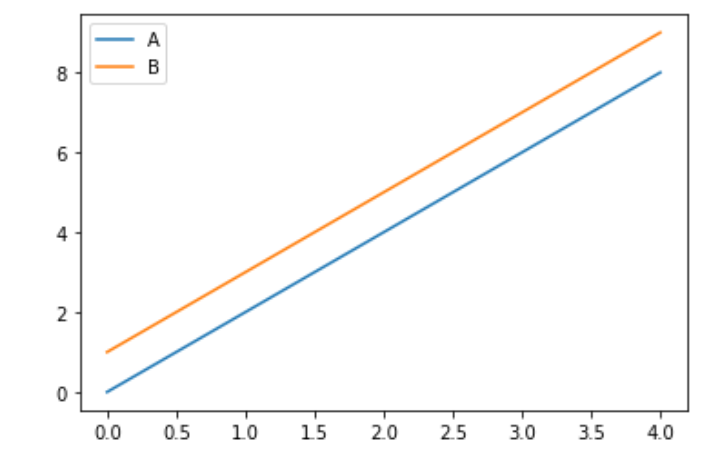
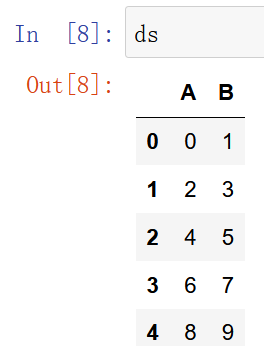
pandas 随机抽取
import torch import pandas as pd a=torch.linspace(start=1,end=120,steps=120).reshape(30,4) a = pd.DataFrame(a,columns=["A","B","C","D"]) print(a) # 读取数据集 df = a # 随机抽取10行 df.sample(n=10) # 随机抽取20%的行 df.sample(frac=0.2) # 允许重复抽取 df.sample(n=10, replace=True) # 为每个行设置不同的权重 weights = torch.rand(30) df.sample(n=10, weights=weights) # 设置随机数种子 df.sample(n=10, random_state=73)
浅谈数据处理的性能问题
交互介质 数据处理性能从高到低依次为内存,磁盘,数据库 正常情况下数据要先读到内存才能处理, 内存与内存交互是最快的,其次内存与磁盘,再次是内存与数据库 数据量小的时候不明显,一旦过万,差异将非常明显 所以,能提前在内存做的,比如排序,分组,拆分/合并等,在内存做完后再存盘或入库 单行与批次 批次操作的性能要远大于一行行处理 能一次按列方式处理的,也远大于一行行处理 一行行处理就是for循环遍历,一次处理一行,这种方式是最低效的,除非不得不如此 如果你非得如此,请不要用python这么做,除非你不在乎性能 语言框架的性能 python效率不如C,因此,能调用numpy实现的功能,最好不要自己用python写 就单论for循环而言,python的性能也低于C,GO,RUST等语言的性能 但这并不是说,你只要用了python,写的程序性能就必定低,因为很多包的底层也是C等语言写的,
参考