环境设置
优先级顺序
export MODELSCOPE_CACHE=/wks/models/modelscope_cache
export MODELSCOPE_HOME=/wks/models/modelscope_cache
import os
from modelscope import snapshot_download
# 设置自定义缓存目录
os.environ['MODELSCOPE_CACHE'] = '/data/models' # Linux/macOS示例
# 对于Windows: os.environ['MODELSCOPE_CACHE'] = 'D:\\models'
# 现在下载的模型会存储到指定目录
model_dir = snapshot_download('thomas/text2vec-base-chinese')
print(f"模型已下载到: {model_dir}")
#模型下载
import os
from modelscope import snapshot_download
os.environ['MODELSCOPE_CACHE'] = '/wks/models/modelscope_cache/' # Linux/macOS示例
model_dir = snapshot_download('thomas/text2vec-base-chinese')
from modelscope.models import Model
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
pipeline_se = pipeline(Tasks.sentence_embedding,
model='thomas/text2vec-base-chinese', model_revision='v1.0.0')
inputs = {
"source_sentence": [
"不可以,早晨喝牛奶不科学",
"吃了海鲜后是不能再喝牛奶的,因为牛奶中含得有维生素C,如果海鲜喝牛奶一起服用会对人体造成一定的伤害",
"吃海鲜是不能同时喝牛奶吃水果,这个至少间隔6小时以上才可以。",
"吃海鲜是不可以吃柠檬的因为其中的维生素C会和海鲜中的矿物质形成砷"
]
}
result = pipeline_se(input=inputs)
print (result)
|
|
|
|
|
|
|
|
AutoModel
from transformers import AutoTokenizer, AutoModel from transformers import file_utils print(file_utils.TRANSFORMERS_CACHE) print(file_utils.default_cache_path) # 本地模型路径 (例如下载的bert-base-chinese) local_model_path = "/wks/models/text2vec-base-chinese" # 替换为你的实际路径 # 加载tokenizer和模型 tokenizer = AutoTokenizer.from_pretrained(local_model_path) model = AutoModel.from_pretrained(local_model_path) # 使用示例 text = "使用本地加载的模型进行文本编码" inputs = tokenizer(text, return_tensors="pt") outputs = model(**inputs) 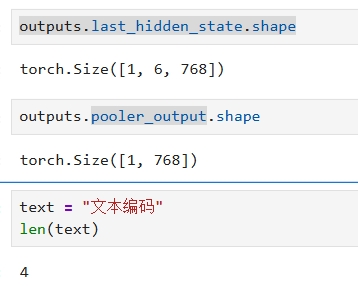
输出向量的长度永远比序列的长度多2,猜测是加了开始结束标记
|
|
last_hidden_state
last_hidden_state 是模型的最后一个隐藏层的输出。
它是一个三维张量,形状为 (batch_size, sequence_length, hidden_size),其中:
batch_size 是批量大小,表示一次处理的文本数量。
sequence_length 是序列长度,表示每个文本的长度(通常是词嵌入的长度)。
hidden_size 是隐藏层的维度,表示每个位置的特征向量的大小。
pooler_output
pooler_output 是模型的池化层输出。它是一个二维张量,形状为 (batch_size, hidden_size),其中:
batch_size 是批量大小,表示一次处理的文本数量。
hidden_size 是隐藏层的维度,表示每个文本的特征向量的大小。
作用
pooler_output 是对整个序列进行池化操作后的结果,通常用于表示整个序列的语义信息。
它是一个固定大小的特征向量,可以用于以下任务:
文本分类:直接使用 pooler_output 作为输入,进行分类任务。
相似度计算:可以使用 pooler_output 计算不同文本之间的相似度。
|
from transformers import AutoTokenizer, AutoModel
# 本地模型路径
local_model_path = "/wks/models/text2vec-base-chinese" # 替换为你的实际路径
# 加载tokenizer和模型
tokenizer = AutoTokenizer.from_pretrained(local_model_path)
model = AutoModel.from_pretrained(local_model_path)
# 多句话输入
sentences = [
"使用本地加载的模型进行文本编码",
"这是第二句话",
"这是第三句话",
"还可以处理更多句子"
]
# 批量编码
inputs = tokenizer(sentences,
return_tensors="pt",
padding=True, # 自动填充到最长句子的长度
truncation=True) # 自动截断到模型最大长度
outputs = model(**inputs)
# outputs现在包含所有句子的编码结果
outputs.pooler_output.shape # torch.Size([4, 768])
|
|
|
|
|
bart-large-chinese
bart-large-chinese 是一个基于 BART(Bidirectional and Auto-Regressive Transformers)架构、专门针对中文文本进行预训练和微调的大规模生成式语言模型。它通常用于中文文本摘要、机器翻译、问答、文本生成等任务。该模型由中国的一些研究团队或公司(如哈工大、智源、华为等)在原始 BART 架构基础上,使用大量中文语料继续预训练,并在中文摘要数据集(如 LCSTS、Weibo 等)上微调得到 - 架构:BART 是编码器-解码器结构,结合了双向编码(类似 BERT)与自回归解码(类似 GPT)。 - 中文适配:使用中文分词器(通常是基于字或 WordPiece),并在中文语料上预训练。 - 用途广泛:特别适合生成式任务,如摘要生成、对话生成、文本改写等。 - pip install transformers torch sentencepiece
https://modelscope.cn/models/fnlp/bart-large-chinese
git lfs install
git clone https://www.modelscope.cn/fnlp/bart-large-chinese.git
git clone https://www.modelscope.cn/fnlp/bart-base-chinese.git
|
```
from transformers import BertTokenizer, BartForConditionalGeneration, Text2TextGenerationPipeline
model_path = "/wks/models/bart-base-chinese"
tokenizer = BertTokenizer.from_pretrained(model_path)
model = BartForConditionalGeneration.from_pretrained(model_path)
text2text_generator = Text2TextGenerationPipeline(model, tokenizer)
text2text_generator("北京是[MASK]的首都", max_length=50, do_sample=False)
```
[{'generated_text': '北 京 是 中 国 的 首 都'}]
|
```
from transformers import BertTokenizer, BartForConditionalGeneration, Text2TextGenerationPipeline
import torch
model_path = "/wks/models/bart-base-chinese"
tokenizer = BertTokenizer.from_pretrained(model_path)
model = BartForConditionalGeneration.from_pretrained(model_path)
text2text_generator = Text2TextGenerationPipeline(model, tokenizer)
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Device set to use {device}")
model = model.to(device)
text="""
客户致电反馈自己有我行记卡,但卡片被我行冻结已经有一周多的时间,之前客户去了网点,要求我行出具具体的冻结说明,但我行告知客户无法出具,后来客户表示我行给其打了电话,态度特别不好,之前有反馈过,但是没有解决问题,现在客户要求继续投诉,不要协商,只要明确的解决方案,请协助处理,谢谢客户姓名:刘联系方式***0*8*6***涉及支行:大连分行营业部证件号和卡号2*028*********64**
"""
print(len(text))
pmt =f"""
请根据下面的文件生成摘要:
{text}
"""
# 编码输入并移动到设备
inputs = tokenizer(pmt, return_tensors="pt", max_length=1024, truncation=True)
inputs = {k: v.to(device) for k, v in inputs.items()}
# 生成摘要
summary_ids = model.generate(
inputs["input_ids"],
max_length=50,
min_length=10,
length_penalty=2.0,
num_beams=4,
early_stopping=True
)
# 解码输出
summary = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
summary = ''.join(summary.split())
print(len(summary),summary)
```
47 请根据下面的文件生成摘要:客户致电反馈自己有我行记卡,但卡片被我行冻结已经有一周多的时间,之前 - 这种摘要生成的效果并不好,更像是一种截断
```
from transformers import BertTokenizer, BartForConditionalGeneration, Text2TextGenerationPipeline
import torch
model_path = "/wks/models/bart-base-chinese"
tokenizer = BertTokenizer.from_pretrained(model_path)
model = BartForConditionalGeneration.from_pretrained(model_path)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# 使用pipeline
text2text_generator = Text2TextGenerationPipeline(model, tokenizer, device=0 if torch.cuda.is_available() else -1)
text = """
客户致电反馈自己有我行记卡,但卡片被我行冻结已经有一周多的时间,之前客户去了网点,要求我行出具具体的冻结说明,但我行告知客户无法出具,后来客户表示我行给其打了电话,态度特别不好,之前有反馈过,但是没有解决问题,现在客户要求继续投诉,不要协商,只要明确的解决方案,请协助处理,谢谢客户姓名:刘联系方式***0*8*6***涉及支行:大连分行营业部证件号和卡号2*028*********64**
"""
# 直接使用文本作为输入
result = text2text_generator(
text,
max_length=80,
min_length=20,
num_beams=4,
length_penalty=1.5,
early_stopping=True
)
print("生成的摘要:", result[0]['generated_text'])
```
```
生成的摘要: 客 户 致 电 反 馈 自 己 有 我 行 记 卡 , 但 卡 片 被 我 行 冻 结 已 经 有 一 周 多 的 时 间 , 之 前 客 户 去 了 网 点 , 要 求 我 行 出 具 具 体 的 冻 结 说 明 , 但 我 行 告 知 客 户 无 法 出 具 , 后 来 客 户 表 示 我 行 给 其 打 了 电 话 , 态 度 特 别 不 好 , 之 后 有 反 馈 过 , 但 是 没 有 解 决 问 题 , 现 在 客 户 要 求 继 续 投 诉 , 不 要 协 商 , 只 要 明 确 的 解 决 方 案 , 请 协 助 处 理 , 谢 谢 客 户 姓 名 : 刘 联 系 方 式 * * * 0 * 8 * 6 * * - 涉 及 支 行 : 大 连 分 行 营 业 部 证 件 号 和 卡 号 2 * 028 * * · * *× * * 64 * *
```
|
|
|
|
|
bert·chinese系列
|
下载模型到本地
git lfs install
git clone https://www.modelscope.cn/tiansz/bert-base-chinese.git
git clone https://www.modelscope.cn/chiakya/bert-chinese-summarization.git
一个标准的Hugging Face模型目录通常包含以下文件:
config.json
pytorch_model.bin # 或 model.safetensors
tokenizer_config.json
vocab.txt # 或 vocab.json, merges.txt (取决于tokenizer类型)
special_tokens_map.json
from transformers import AutoTokenizer, AutoModel
# 本地模型路径 (例如下载的bert-base-chinese)
local_model_path = "/wks/models/bert-base-chinese" # 替换为你的实际路径
# 加载tokenizer和模型
tokenizer = AutoTokenizer.from_pretrained(local_model_path)
model = AutoModel.from_pretrained(local_model_path)
# 使用示例
text = "使用本地加载的模型进行文本编码"
inputs = tokenizer(text, return_tensors="pt")
outputs = model(**inputs)
|
root@ii:/wks/models# mkdir huggingface root@ii:/wks/models# mkdir -p huggingface/cache root@ii:/wks/models# mkdir -p transformers/cache vim /etc/profile # 设置所有Hugging Face相关文件的根目录 export HF_HOME=/wks/models/huggingface # 专门设置Transformers模型缓存目录 export TRANSFORMERS_CACHE=/wks/models/transformers/cache # 设置Hugging Face Hub下载的缓存目录 export HUGGINGFACE_HUB_CACHE=/wks/models/huggingface/cache llm@ii:~$ vim .bashrc export HF_HOME=/wks/models/huggingface export TRANSFORMERS_CACHE=/wks/models/transformers/cache export HUGGINGFACE_HUB_CACHE=/wks/models/huggingface/cache
from transformers import AutoTokenizer, AutoModel
import torch
# 加载预训练模型和分词器
model_name = "bert-base-chinese"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
# 文本预处理和向量化
text = "这是一段需要向量化的中文文本"
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True)
# 获取向量表示
with torch.no_grad():
outputs = model(**inputs)
# 使用[CLS] token的表示作为整个句子的向量
sentence_embedding = outputs.last_hidden_state[:, 0, :].numpy()
Python代码中设置
import os
from transformers import AutoTokenizer
# 在代码中设置环境变量
os.environ["HF_HOME"] = "/path/to/your/custom/directory"
os.environ["TRANSFORMERS_CACHE"] = "/path/to/transformers/cache"
# 现在下载的模型会存储到指定目录
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
验证缓存位置
from transformers import file_utils
print(file_utils.TRANSFORMERS_CACHE)
print(file_utils.default_cache_path)
|
https://modelscope.cn/models/hfl/chinese-roberta-wwm-ext-large ``` git lfs install git clone https://www.modelscope.cn/hfl/chinese-roberta-wwm-ext-large.git ``` |
|
|
|
bge-base-zh
|
FlagEmbedding
```
FlagEmbedding 能够将任何文本映射到一个低维稠密向量,可用于检索、分类、聚类或语义搜索等任务。 它也可用于大语言模型的向量数据库中。
************* 🌟更新日志🌟 *************
2023年10月12日:发布 LLM-Embedder,一个统一的嵌入模型,以支持LLMs的多样化检索增强需求。论文 :fire:
2023年9月15日:BGE的技术报告已发布
2023年9月15日:BGE的大规模训练数据已发布
2023年9月12日:新模型发布:
新的重排序模型:发布了跨编码器模型 BAAI/bge-reranker-base 和 BAAI/bge-reranker-large,比嵌入模型更强大。我们建议使用/微调它们以重新排列由嵌入模型返回的前k个文档。
嵌入模型更新:发布 bge-*-v1.5 嵌入模型以缓解相似度分布问题,并在无指令的情况下增强其检索能力。
```
- 所有模型均已上传至Huggingface Hub,您可在此处查看它们:https://huggingface.co/BAAI。
- 如果无法访问Huggingface Hub,您也可以在https://model.baai.ac.cn/models下载这些模型。
- pip install -U FlagEmbedding
```
from FlagEmbedding import FlagModel
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = FlagModel('BAAI/bge-large-zh-v1.5',
query_instruction_for_retrieval="为这个句子生成表示以用于检索相关文章:",
use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
embeddings_1 = model.encode(sentences_1)
embeddings_2 = model.encode(sentences_2)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
# for s2p(short query to long passage) retrieval task, suggest to use encode_queries() which will automatically add the instruction to each query
# corpus in retrieval task can still use encode() or encode_corpus(), since they don't need instruction
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
q_embeddings = model.encode_queries(queries)
p_embeddings = model.encode(passages)
scores = q_embeddings @ p_embeddings.T
```
- https://modelscope.cn/models/BAAI/bge-base-zh-v1.5/summary
|
- pip install -U sentence-transformers
```
from sentence_transformers import SentenceTransformer
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
embeddings_1 = model.encode(sentences_1, normalize_embeddings=True)
embeddings_2 = model.encode(sentences_2, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
```
```
from sentence_transformers import SentenceTransformer
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
instruction = "为这个句子生成表示以用于检索相关文章:"
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
q_embeddings = model.encode([instruction+q for q in queries], normalize_embeddings=True)
p_embeddings = model.encode(passages, normalize_embeddings=True)
scores = q_embeddings @ p_embeddings.T
```
示例2
```
from sentence_transformers import SentenceTransformer, models
# 1. 加载本地 transformer 模型(你下载的 BAAI)
transformer = models.Transformer("/wks/models/bge-base-zh-v1.5")
# 2. 添加 Pooling 层(这一步必须!否则模型无法输出句向量)
pooling = models.Pooling(
word_embedding_dimension=transformer.get_word_embedding_dimension(),
pooling_mode_cls_token=True,
pooling_mode_mean_tokens=False,
pooling_mode_max_tokens=False,
)
# 3. 组合为 SentenceTransformer 模型
model = SentenceTransformer(modules=[transformer, pooling])
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
embeddings_1 = model.encode(sentences_1, normalize_embeddings=True)
embeddings_2 = model.encode(sentences_2, normalize_embeddings=True)
print(type(embeddings_1))
```
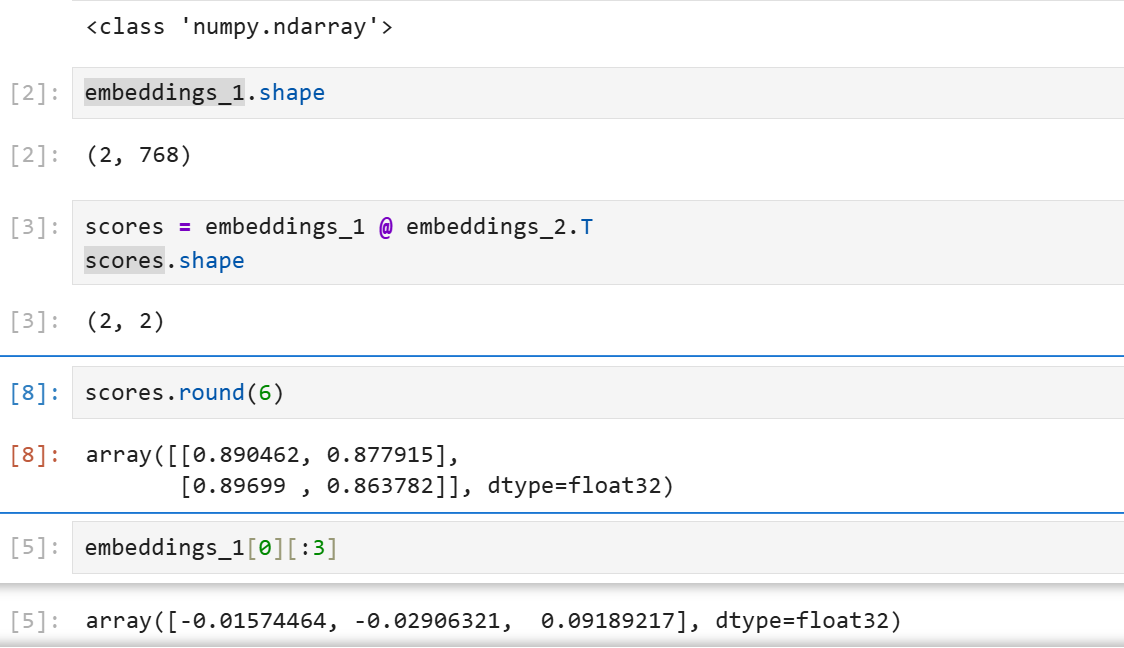
相同的句子会得到相同的向量,多次执行都是一样的结果
```
from sentence_transformers import SentenceTransformer
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = SentenceTransformer('/wks/models/bge-base-zh-v1.5')
embeddings_1 = model.encode(sentences_1, normalize_embeddings=True)
embeddings_2 = model.encode(sentences_2, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
similarity.round(6)
```
array([[0.890462, 0.877915],
[0.89699 , 0.863782]], dtype=float32)
|
```
from modelscope import AutoTokenizer, AutoModel
import torch
# Sentences we want sentence embeddings for
sentences = ["样例数据-1", "样例数据-2"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-base-zh-v1.5')
model = AutoModel.from_pretrained('BAAI/bge-base-zh-v1.5')
model.eval()
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# for s2p(short query to long passage) retrieval task, add an instruction to query (not add instruction for passages)
# encoded_input = tokenizer([instruction + q for q in queries], padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = model_output[0][:, 0]
# normalize embeddings
sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:", sentence_embeddings)
```
```
import torch
from modelscope import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-base-zh-v1.5')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-base-zh-v1.5')
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
print(scores)
```
|
``` export HF_HOME=/wks/models/huggingface #export TRANSFORMERS_CACHE=/wks/models/transformers/cache export HUGGINGFACE_HUB_CACHE=/wks/models/huggingface/cache export MODELSCOPE_CACHE=/wks/models/modelscope_cache export MODELSCOPE_HOME=/wks/models/modelscope_cache ``` - sudo apt-get install git-lfs ``` git lfs install git clone https://www.modelscope.cn/BAAI/bge-base-zh-v1.5.git ``` ``` git clone https://www.modelscope.cn/BAAI/bge-large-zh.git git clone https://www.modelscope.cn/BAAI/bge-large-zh-v1.5.git git clone https://www.modelscope.cn/BAAI/bge-reranker-large.git ``` 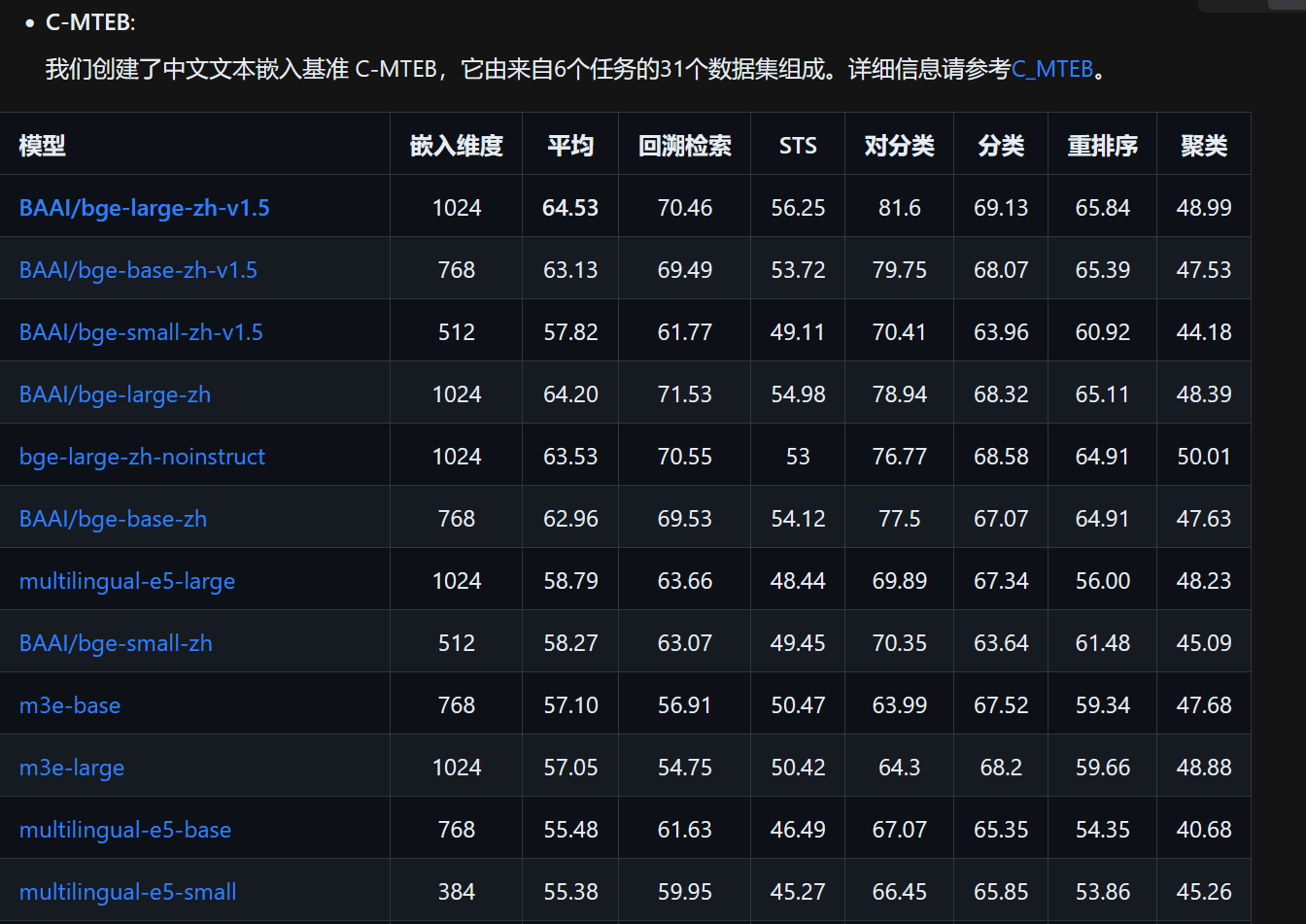
|
``` from tpf.nlp.bgm import TextEmbedding te = TextEmbedding() bge_model_path = "/wks/models/bge-base-zh-v1.5" te.init_bge(model_path=bge_model_path) ``` ``` sentences = ["样例数据-1", "样例数据-1"] sentence_embeddings= te.embedding_bge(texts=sentences) sim1 = sentence_embeddings[0] sim2 = sentence_embeddings[1] sim1@sim2 ``` tensor(1.) |
bge
|
BAAI/bge-reranker-large git clone https://www.modelscope.cn/BAAI/bge-reranker-large.git ``` ``` Xenova/bge-reranker-large
- Xenova/bge-reranker-large 提供了前端的用法
```
git clone https://www.modelscope.cn/Xenova/bge-reranker-large.git
```
- npm i @huggingface/transformers
```
import { pipeline } from '@huggingface/transformers';
const classifier = await pipeline('text-classification', 'Xenova/bge-reranker-large');
const output = await classifier('I love transformers!');
```
|
|
FlagEmbedding
-
```
from FlagEmbedding import FlagModel
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = FlagModel('BAAI/bge-large-zh-v1.5',
query_instruction_for_retrieval="为这个句子生成表示以用于检索相关文章:",
use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
embeddings_1 = model.encode(sentences_1)
embeddings_2 = model.encode(sentences_2)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
# for s2p(short query to long passage) retrieval task, suggest to use encode_queries() which will automatically add the instruction to each query
# corpus in retrieval task can still use encode() or encode_corpus(), since they don't need instruction
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
q_embeddings = model.encode_queries(queries)
p_embeddings = model.encode(passages)
scores = q_embeddings @ p_embeddings.T
```
sentence-transformers
- pip install -U sentence-transformers
```
from sentence_transformers import SentenceTransformer
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
embeddings_1 = model.encode(sentences_1, normalize_embeddings=True)
embeddings_2 = model.encode(sentences_2, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
```
|
|
相关性:值越大,相关性越高
```
import torch
from modelscope import AutoModelForSequenceClassification, AutoTokenizer
model_path = "/wks/models/bge-reranker-large"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForSequenceClassification.from_pretrained(model_path)
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
print(scores)
```
```
tensor([-5.6085, 5.7623])
```
与嵌入模型不同,重排序器以问题和文档作为输入,直接输出相似度而非嵌入。 您可以通过对查询和段落输入重排序器来获得相关性分数。 重排序器基于交叉熵损失进行优化,因此相关性分数不局限于特定范围。 FlagEmbedding
- pip install -U FlagEmbedding
- 获取相关性分数(分数越高表示越相关)
```
from FlagEmbedding import FlagReranker
reranker = FlagReranker('BAAI/bge-reranker-large', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
score = reranker.compute_score(['query', 'passage'])
print(score)
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])
print(scores)
```
Huggingface Transformers
```
import torch
from modelscope import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-large')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-large')
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
print(scores)
```
|
|
|
|
|
ChatGLM3-6B-32K
https://modelscope.cn/models/ZhipuAI/chatglm3-6b-32k
pip install protobuf 'transformers>=4.30.2' cpm_kernels 'torch>=2.0' gradio mdtex2html sentencepiece accelerate -i https://pypi.tuna.tsinghua.edu.cn/simple
```
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b-32k.git
```
ChatGLM3-6B-32K在ChatGLM3-6B的基础上进一步强化了对于长文本的理解能力,
能够更好的处理最多32K长度的上下文。
具体地,我们对位置编码进行了更新,并设计了更有针对性的长文本训练方法,
在对话阶段使用 32K 的上下文长度训练。
在实际的使用中,如果您面临的上下文长度基本在 8K 以内,我们推荐使用ChatGLM3-6B;
如果您需要处理超过 8K 的上下文长度,我们推荐使用ChatGLM3-6B-32K。
ChatGLM3-6B 是 ChatGLM 系列最新一代的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:
更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的预训练模型中最强的性能。
- 更完整的功能支持:
- ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。
- 同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
更全面的开源序列:
除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM-6B-Base、
长文本对话模型 ChatGLM3-6B-32K。
以上所有权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
|
|
对话生成
```
from modelscope import AutoTokenizer, AutoModel, snapshot_download
model_dir = snapshot_download("ZhipuAI/chatglm3-6b-32k", revision = "v1.0.0")
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModel.from_pretrained(model_dir, trust_remote_code=True).half().cuda()
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
print(response)
```
摘要生成
|
|
|
|
|
|
|
text2vec-base-chinese
git lfs install
git clone https://www.modelscope.cn/thomas/text2vec-base-chinese.git
from transformers import AutoTokenizer, AutoModel
from transformers import file_utils
print(file_utils.TRANSFORMERS_CACHE)
print(file_utils.default_cache_path)
# 本地模型路径 (例如下载的bert-base-chinese)
local_model_path = "/wks/models/text2vec-base-chinese" # 替换为你的实际路径
# 加载tokenizer和模型
tokenizer = AutoTokenizer.from_pretrained(local_model_path)
model = AutoModel.from_pretrained(local_model_path)
# 使用示例
text = "使用本地加载的模型进行文本编码"
inputs = tokenizer(text, return_tensors="pt")
outputs = model(**inputs)
outputs
|
|
|
|
|
|
|
|
摘要生成
|
T5 模型用于英文、俄文和中文的多语言文本摘要
```
该模型旨在执行在多任务模式下生成摘要文本内容的任务,并内置了针对以下语言的翻译功能:俄语、中文、英语。
这是一个 T5 多任务模型。它有条件地控制生成摘要文本内容的能力,并进行翻译。总共,它可以理解 12 条命令,根据设定的前缀:
"summary: " - 在源语言中生成简单的简洁内容
"summary brief: " - 在源语言中生成简短的摘要内容
"summary big: " - 在源语言中生成扩展的摘要内容
你可以通过添加“N words”来条件性地限制输出到给定的 N 个单词数。
"summary 20 words: " - 在源语言中生成简单的简洁内容
"summary brief 4 words: " - 在源语言中生成简短的摘要内容
"summary big 100 words: " - 在源语言中生成扩展的摘要内容
词级限制在小数值时比大数值时更有效。
该模型可以理解列表中的任何语言的文本:俄语、中文或英语。它还可以将结果翻译成列表中的任何语言:俄语、中文或英语。
为了翻译成目标语言,指定目标语言标识符作为前缀 "... to :"。其中 lang 可以取值:ru, en, zh。源语言可以不指定,此外,源文本可以是多语言的。
任务前缀:
"summary to en: " - 从多语言文本中生成英文摘要内容
"summary brief to en: " - 从多语言文本中生成英文简短摘要
"summary big to en: " - 从多语言文本中生成英文扩展摘要内容
"summary to ru: " - 从多语言文本中生成俄文摘要内容
"summary brief to ru: " - 从多语言文本中生成俄文简短摘要
"summary big to ru: " - 从多语言文本中生成俄文扩展摘要内容
"summary to zh: " - 从多语言文本中生成中文摘要内容
"summary brief to zh: " - 从多语言文本中生成中文简短摘要
"summary big to zh: " - 从多语言文本中生成中文扩展摘要内容
训练模型可以压缩 2048 个令牌的上下文,并在 big 任务中输出最多 200 个令牌的摘要,在 summary 任务中输出最多 50 个令牌,在 brief 任务中输出最多 20 个令牌。
```
```
from modelscope import T5ForConditionalGeneration, T5Tokenizer
device = 'cuda' #or 'cpu' for translate on cpu
model_name = 'utrobinmv/t5_summary_en_ru_zh_large_2048'
model = T5ForConditionalGeneration.from_pretrained(model_name)
model.eval()
model.to(device)
generation_config = model.generation_config
# for quality generation
generation_config.length_penalty = 0.6
generation_config.no_repeat_ngram_size = 2
generation_config.num_beams = 10
tokenizer = T5Tokenizer.from_pretrained(model_name)
text = """Videos that say approved vaccines are dangerous and cause autism, cancer or infertility are among those that will be taken down, the company said. The policy includes the termination of accounts of anti-vaccine influencers. Tech giants have been criticised for not doing more to counter false health information on their sites. In July, US President Joe Biden said social media platforms were largely responsible for people's scepticism in getting vaccinated by spreading misinformation, and appealed for them to address the issue. YouTube, which is owned by Google, said 130,000 videos were removed from its platform since last year, when it implemented a ban on content spreading misinformation about Covid vaccines. In a blog post, the company said it had seen false claims about Covid jabs "spill over into misinformation about vaccines in general". The new policy covers long-approved vaccines, such as those against measles or hepatitis B. "We're expanding our medical misinformation policies on YouTube with new guidelines on currently administered vaccines that are approved and confirmed to be safe and effective by local health authorities and the WHO," the post said, referring to the World Health Organization."""
# text summary generate
prefix = 'summary: '
src_text = prefix + text
input_ids = tokenizer(src_text, return_tensors="pt")
generated_tokens = model.generate(**input_ids.to(device), generation_config=generation_config)
result = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
print(result)
#YouTube to remove videos claiming approved COVID-19 vaccines cause harm, including autism, cancer, and infertility. It will terminate accounts of anti-vaccine influencers and expand its medical misinformation policies.
# text brief summary generate
prefix = 'summary brief: '
src_text = prefix + text
input_ids = tokenizer(src_text, return_tensors="pt")
generated_tokens = model.generate(**input_ids.to(device), generation_config=generation_config)
result = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
print(result)
#YouTube has announced a crackdown on misinformation about Covid-19 vaccines.
# generate a 4-word summary of the text
prefix = 'summary brief 4 words: '
src_text = prefix + text
input_ids = tokenizer(src_text, return_tensors="pt")
generated_tokens = model.generate(**input_ids.to(device), generation_config=generation_config)
result = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
print(result)
#YouTube removes vaccine misinformation.
# text big summary generate
prefix = 'summary big: '
src_text = prefix + text
input_ids = tokenizer(src_text, return_tensors="pt")
generated_tokens = model.generate(**input_ids.to(device), generation_config=generation_config)
result = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
print(result)
#YouTube, owned by Google, is removing videos claiming approved vaccines are dangerous and cause autism, cancer, or infertility. The company will terminate accounts of anti-vaccine influencers and expand its medical misinformation policies. This follows criticism of tech giants for not doing more to combat false health information on their sites. In July, US President Joe Biden called for social media platforms to address the issue of vaccine skepticism. Since implementing a ban on Covid vaccine content in 2021, 13 million videos have been removed. New policies cover long-approved vaccinations, such as those against measles or hepatitis B.
```
中文文本的英文摘要示例:
```
device = 'cuda' #or 'cpu' for translate on cpu
model_name = 'utrobinmv/t5_summary_en_ru_zh_large_2048'
model = T5ForConditionalGeneration.from_pretrained(model_name)
model.eval()
model.to(device)
generation_config = model.generation_config
# for quality generation
generation_config.length_penalty = 0.6
generation_config.no_repeat_ngram_size = 2
generation_config.num_beams = 10
tokenizer = T5Tokenizer.from_pretrained(model_name)
text = """在北京冬奥会自由式滑雪女子坡面障碍技巧决赛中,中国选手谷爱凌夺得银牌。祝贺谷爱凌!今天上午,自由式滑雪女子坡面障碍技巧决赛举行。决赛分三轮进行,取选手最佳成绩排名决出奖牌。第一跳,中国选手谷爱凌获得69.90分。在12位选手中排名第三。完成动作后,谷爱凌又扮了个鬼脸,甚是可爱。第二轮中,谷爱凌在道具区第三个障碍处失误,落地时摔倒。获得16.98分。网友:摔倒了也没关系,继续加油!在第二跳失误摔倒的情况下,谷爱凌顶住压力,第三跳稳稳发挥,流畅落地!获得86.23分!此轮比赛,共12位选手参赛,谷爱凌第10位出场。网友:看比赛时我比谷爱凌紧张,加油!"""
# text summary generate
prefix = 'summary to en: '
src_text = prefix + text
input_ids = tokenizer(src_text, return_tensors="pt")
generated_tokens = model.generate(**input_ids.to(device), generation_config=generation_config)
result = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
print(result)
#In the women's freestyle skiing final at the Beijing Winter Olympics, Chinese skater Gu Ailing won silver. She scored 69.90 in the first jump, ranked 3rd among 12 competitors. Despite a fall, she managed to land smoothly, earning 86.23 points.
# text brief summary generate
prefix = 'summary brief to en: '
src_text = prefix + text
input_ids = tokenizer(src_text, return_tensors="pt")
generated_tokens = model.generate(**input_ids.to(device), generation_config=generation_config)
result = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
print(result)
#"Chinese Skier Wins Silver in Beijing"
# generate a 4-word summary of the text
prefix = 'summary brief to en 4 words: '
src_text = prefix + text
input_ids = tokenizer(src_text, return_tensors="pt")
generated_tokens = model.generate(**input_ids.to(device), generation_config=generation_config)
result = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
print(result)
#"Chinese Skier Wins Silver"
# text big summary generate
prefix = 'summary big to en: '
src_text = prefix + text
input_ids = tokenizer(src_text, return_tensors="pt")
generated_tokens = model.generate(**input_ids.to(device), generation_config=generation_config)
result = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
print(result)
#In the women's freestyle ski slope obstacle technique final at the Beijing Winter Olympics, Chinese skater Gu Ailing won silver. She scored 69.90 in her first jump, placing third among the 12 competitors. Despite a fall in the second round, she managed to land smoothly, earning 86.23 points. The final was held in three rounds.
```
|
```
from modelscope import T5ForConditionalGeneration, T5Tokenizer
device = 'cuda' #or 'cpu' for translate on cpu
model_name = '/wks/models/t5_summary_en_ru_zh_base_2048'
model = T5ForConditionalGeneration.from_pretrained(model_name)
model.eval()
model.to(device)
```
```
generation_config = model.generation_config
# for quality generation
generation_config.length_penalty = 0.6
generation_config.no_repeat_ngram_size = 2
generation_config.num_beams = 10
tokenizer = T5Tokenizer.from_pretrained(model_name)
```
``` text=""" 客户致电反馈自己有我行记卡,但卡片被我行冻结已经有一周多的时间,之前客户去了网点,要求我行出具具体的冻结说明,但我行告知客户无法出具,后来客户表示我行给其打了电话,态度特别不好,之前有反馈过,但是没有解决问题,现在客户要求继续投诉,不要协商,只要明确的解决方案,请协助处理,谢谢客户姓名:刘联系方式***0*8*6***涉及支行:大连分行营业部证件号和卡号2*028*********64** """ # text summary generate prefix = 'summary to zh: ' src_text = prefix + text input_ids = tokenizer(src_text, return_tensors="pt") generated_tokens = model.generate(**input_ids.to(device), generation_config=generation_config) result = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True) print(result) ``` ``` ['客户致电反馈自己有行记卡,但卡片被我行冻结已经有一周多的时间,之前客户去网点,要求我提供具体的冻结说明。'] ```
|
- 结论: - 客户说了一大堆,这种不要求逻辑严谨的场景,t5总结的效果要远超于hanlp, - 即t5拥有hanlp所没有意义理解能力,即使话语本身逻辑混乱,t5也能按自然逻辑进行总结。 - 对于,新闻、博客、文档等,两者效果差不多,有时hanlp效果会好些
```
from pyhanlp import *
text="""
客户致电反馈自己有我行记卡,但卡片被我行冻结已经有一周多的时间,之前客户去了网点,要求我行出具具体的冻结说明,但我行告知客户无法出具,后来客户表示我行给其打了电话,态度特别不好,之前有反馈过,但是没有解决问题,现在客户要求继续投诉,不要协商,只要明确的解决方案,请协助处理,谢谢客户姓名:刘联系方式***0*8*6***涉及支行:大连分行营业部证件号和卡号2*028*********64**
"""
def summary(text,top_n=8):
summary_sentences = HanLP.extractSummary(text,top_n)
st =""
for sentence in summary_sentences:
st += sentence+","
st = st.removesuffix(",")
return st
st = summary(text,top_n=8)
st
```
- 客户致电反馈自己有我行记卡,
- 要求我行出具具体的冻结说明,
- 但我行告知客户无法出具,
- 之前客户去了网点,
- 之前有反馈过,
- 后来客户表示我行给其打了电话,
- 现在客户要求继续投诉,
- 但卡片被我行冻结已经有一周多的时间
- 对比
- t5 只能输出前3行,前两行一致,第3行区别在于,t5输出的是"但我告知客户无法出具",少了一个行字,
- 这里有这个行更合适,但这是t5自己理解后处理的结果
- 最大的差别,还是hanlp可以输出更多的行,而t5只能输出前3行,t5自行决断输出3行即可
``` text = """ 客户很着,请加急处理,谢谢客户致电反馈,咨询关于贷款放款问题,客户是房子卖方一直在等放款,*2月买方的贷款就申请过了,客户之后也一直再联系,在**号联系,得知放款审核已经通过但是卡在财务这里,客户致电财务这也未接听,客户一直等待至今依旧没有放款,客户很着急,希望尽快放款请协助处理并回复,谢谢客户姓名:张买方客户姓名:董明杰客户说应该是这个联系方式***8087***2贷款行:成都高升路支 """ st = summary(text,top_n=8) st ``` ``` '谢谢客户姓名,客户致电财务这也未接听,客户很着,客户很着急,客户一直等待至今依旧没有放款,董明杰客户说应该是这个联系方式***8087***2贷款行,*2月买方的贷款就申请过了,客户之后也一直再联系' ``` ``` from modelscope import T5ForConditionalGeneration, T5Tokenizer device = 'cuda' #or 'cpu' for translate on cpu model_name = '/wks/models/t5_summary_en_ru_zh_base_2048' model = T5ForConditionalGeneration.from_pretrained(model_name) model.eval() model.to(device) generation_config = model.generation_config # for quality generation generation_config.length_penalty = 0.6 generation_config.no_repeat_ngram_size = 2 generation_config.num_beams = 10 tokenizer = T5Tokenizer.from_pretrained(model_name) ``` ``` # text summary generate prefix = 'summary to zh: ' src_text = prefix + text input_ids = tokenizer(src_text, return_tensors="pt") generated_tokens = model.generate(**input_ids.to(device), generation_config=generation_config) result = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True) print(result) ``` - ['客户是房子供应商一直在等放款,2月的贷款就申请了,客户之后也一直联系,收到贷款审核已经通过但是卡在财务下面。'] 对于逻辑不严谨的场景,t5总结的效果要远超于hanlp |
|
|
|
|
参考