数据准备
|
|
|
交易流水
```
import pandas as pd
import numpy as np
import torch
pd.set_option('display.max_columns', None)
data_path = "/wks/datasets/ibm_aml/HI-Small_Trans.csv"
df=pd.read_csv(data_path)
df[:3]
```
|
|
|
|
|
|
|
数据观察
- 确认各个列的数据类型
- 二维数据表,观察不同列的数据分布:
- 是否存在空值
|
```
df.info()
class 'pandas.core.frame.DataFrame'
Index: 50000 entries, 4205263 to 1446591
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Timestamp 50000 non-null object
1 From Bank 50000 non-null int64
2 Account 50000 non-null object
3 To Bank 50000 non-null int64
4 Account.1 50000 non-null object
5 Amount Received 50000 non-null float64
6 Receiving Currency 50000 non-null object
7 Amount Paid 50000 non-null float64
8 Payment Currency 50000 non-null object
9 Payment Format 50000 non-null object
10 Is Laundering 50000 non-null int64
dtypes: float64(2), int64(3), object(6)
memory usage: 4.6+ MB
```
```
numeric_cols = df.select_dtypes(exclude="object").columns
numeric_cols
Index(['From Bank', 'To Bank', 'Amount Received', 'Amount Paid',
'Is Laundering'],
dtype='object')
```
```
categorical_cols = df.select_dtypes(include="object").columns
categorical_cols
Index(['Timestamp', 'Account', 'Account.1', 'Receiving Currency',
'Payment Currency', 'Payment Format'],
dtype='object')
```
参考代码 /opt/wks/kejian/zhunbei/dl_kejian/gnn/ibm-aml |
```
## Unique columns in df
unique_counts = df[categorical_cols].nunique()
print("Unique columns in the DataFrame: \n", unique_counts)
```
Unique columns in the DataFrame:
Timestamp 13001
Account 37434
Account.1 44321
Receiving Currency 15
Payment Currency 15
Payment Format 7
dtype: int64
|
```
import pandas as pd
import numpy as np
pd.set_option('display.max_columns', None)
data_path = "/wks/datasets/ibm_aml/HI-Small_Trans.csv"
data=pd.read_csv(data_path)
df = data
df[:3]
```
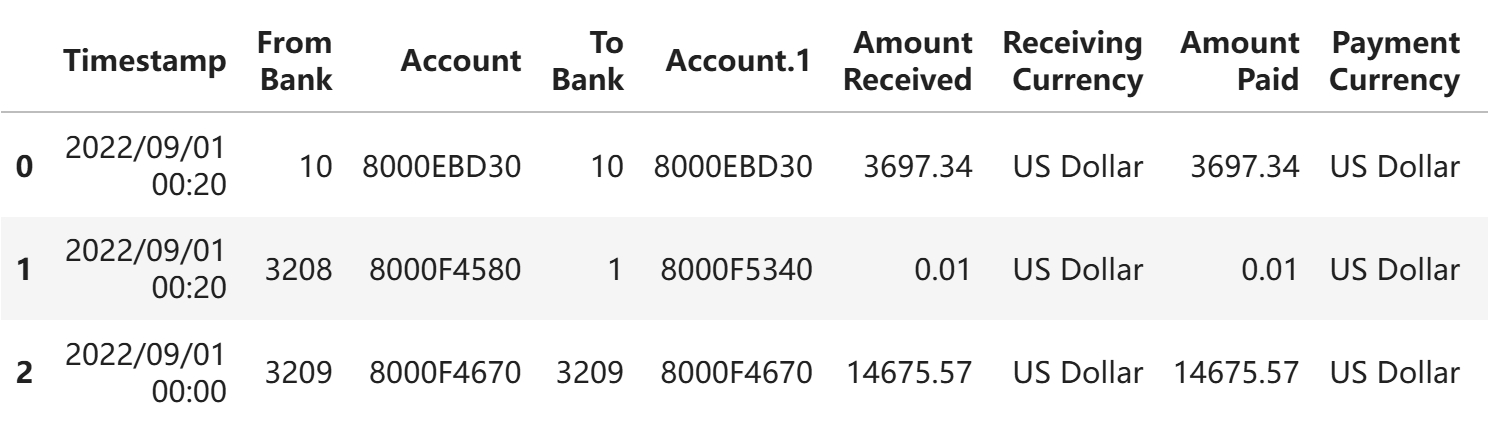
数字类型
```
df[['Amount Received', 'Amount Paid']].describe()
```
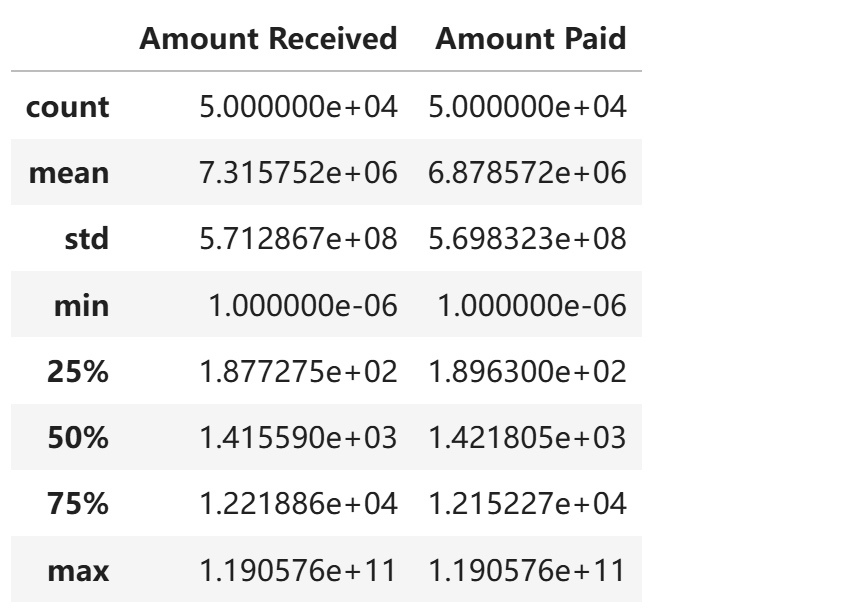
数字看大小分布
类别看频次分布
```
df[['Account', 'Account.1']].describe()
```
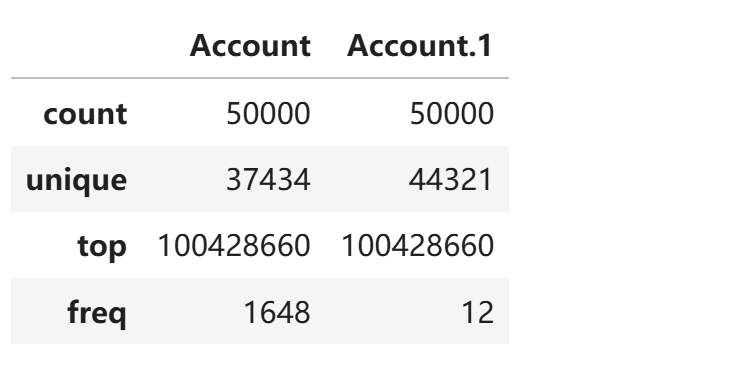
- 如果列是非数值类型(如字符串或分类类型), describe() 默认只会显示 - count - unique(唯一值数量) - top(出现频率最高的值) - freq(top 值的出现次数)
|
``` df['To Bank'].value_counts() ``` |
|
|
数据采样
```
import pandas as pd
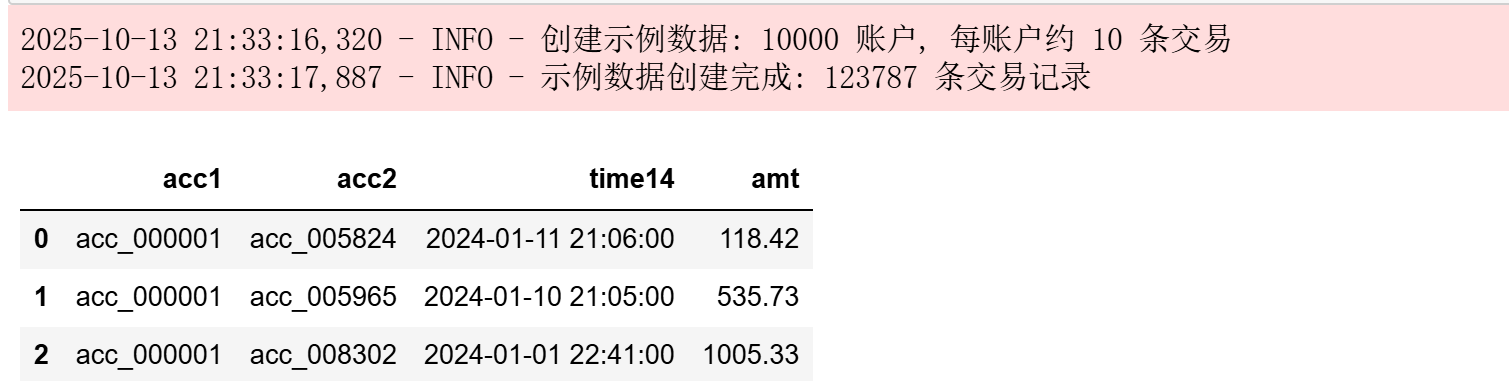
from tpf.data.make import JiaoYi as jy
df_tra = jy.make_trans12( num_accounts=10000,
transactions_per_account=10,
start_date='2024-01-01',
end_date='2024-02-01',acc1='acc1',time_col='time14',amt_col='amt')
df_tra[:3]
```
```
from tpf.data.sample import DataSampler
dsm = DataSampler(start_date='2024-01-01',
end_date='2024-02-01',
excluded_accounts=['acc1', 'acc2'],
sample_size=100,
records_per_account=10,
acc1='acc1',
acc2='acc2',
time_col='time14',
amt_col='amt')
```
2025-10-13 21:33:17,919 - INFO - 初始化交易采样器:
2025-10-13 21:33:17,920 - INFO - 时间范围: 2024-01-01 到 2024-02-01
2025-10-13 21:33:17,921 - INFO - 排除账户: ['acc1', 'acc2']
2025-10-13 21:33:17,921 - INFO - 采样账户数: 100
2025-10-13 21:33:17,921 - INFO - 每账户记录数: 10
```
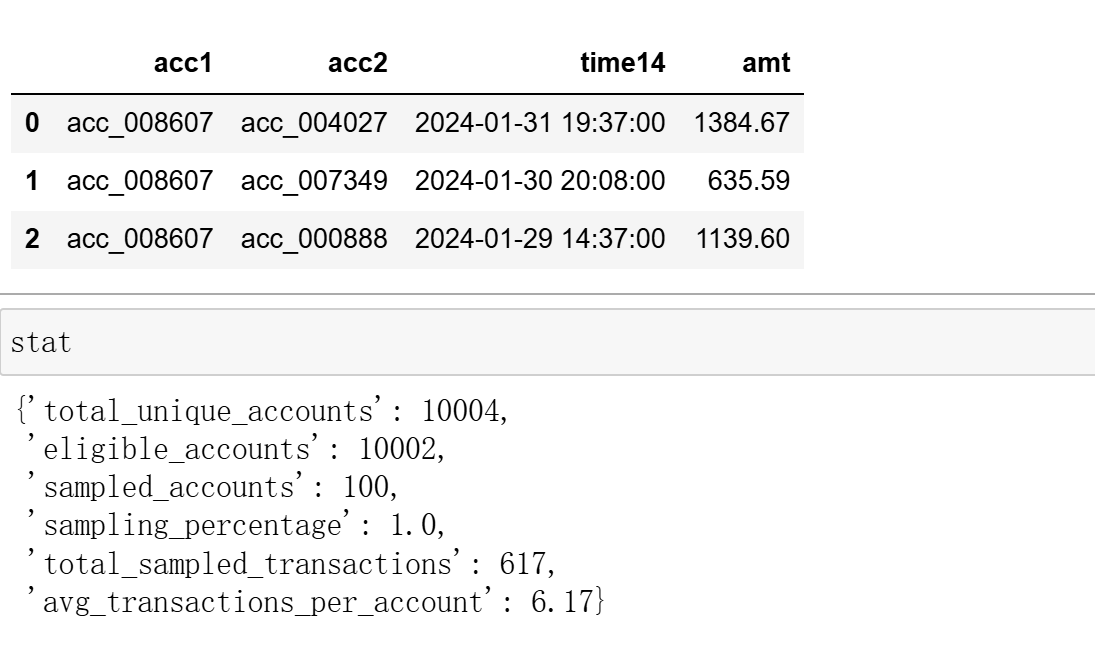
df,stat = dsm.sample(df_tra)
df[:3]
```
```
2025-10-13 21:33:17,931 - INFO - 开始交易数据采样流程
2025-10-13 21:33:17,982 - INFO - 加载数据完成:
2025-10-13 21:33:17,983 - INFO - 原始数据行数: 123787
2025-10-13 21:33:17,983 - INFO - 时间范围内行数: 123787
2025-10-13 21:33:17,984 - INFO - 数据列: ['acc1', 'acc2', 'time14', 'amt']
2025-10-13 21:33:17,984 - INFO - ============================================================
2025-10-13 21:33:17,985 - INFO - 步骤1:获取不重复账户
2025-10-13 21:33:18,020 - INFO - 发现 10004 个不重复账户
2025-10-13 21:33:18,021 - INFO - 账户交易统计:
2025-10-13 21:33:18,021 - INFO - 平均交易数: 12.4
2025-10-13 21:33:18,022 - INFO - 最少交易数: 1
2025-10-13 21:33:18,023 - INFO - 最多交易数: 71
2025-10-13 21:33:18,023 - INFO - ============================================================
2025-10-13 21:33:18,024 - INFO - 步骤2:排除指定账户并采样
2025-10-13 21:33:18,027 - INFO - 排除指定账户后剩余 10002 个账户
2025-10-13 21:33:18,027 - INFO - 排除的账户: {'acc1', 'acc2'}
2025-10-13 21:33:18,028 - INFO - 随机采样 100 个账户
2025-10-13 21:33:18,029 - INFO - ============================================================
2025-10-13 21:33:18,029 - INFO - 步骤3:获取每个账户的最近交易记录
2025-10-13 21:33:18,030 - INFO - 处理进度: 1/100
2025-10-13 21:33:18,466 - INFO - 采样完成:
2025-10-13 21:33:18,466 - INFO - 采样账户数: 100
2025-10-13 21:33:18,467 - INFO - 采样交易记录数: 617
2025-10-13 21:33:18,468 - INFO - 平均每账户记录数: 6.17
```
|
|
|
|
|
|
|
|
数据清洗
```
df.isnull().sum()
```
|
```
## Dropping some columns
cols_to_drop = ['Timestamp', 'Amount Paid', 'Payment Currency']
df.drop(cols_to_drop, axis=1, inplace=True)
df.head(2)
```
|
|
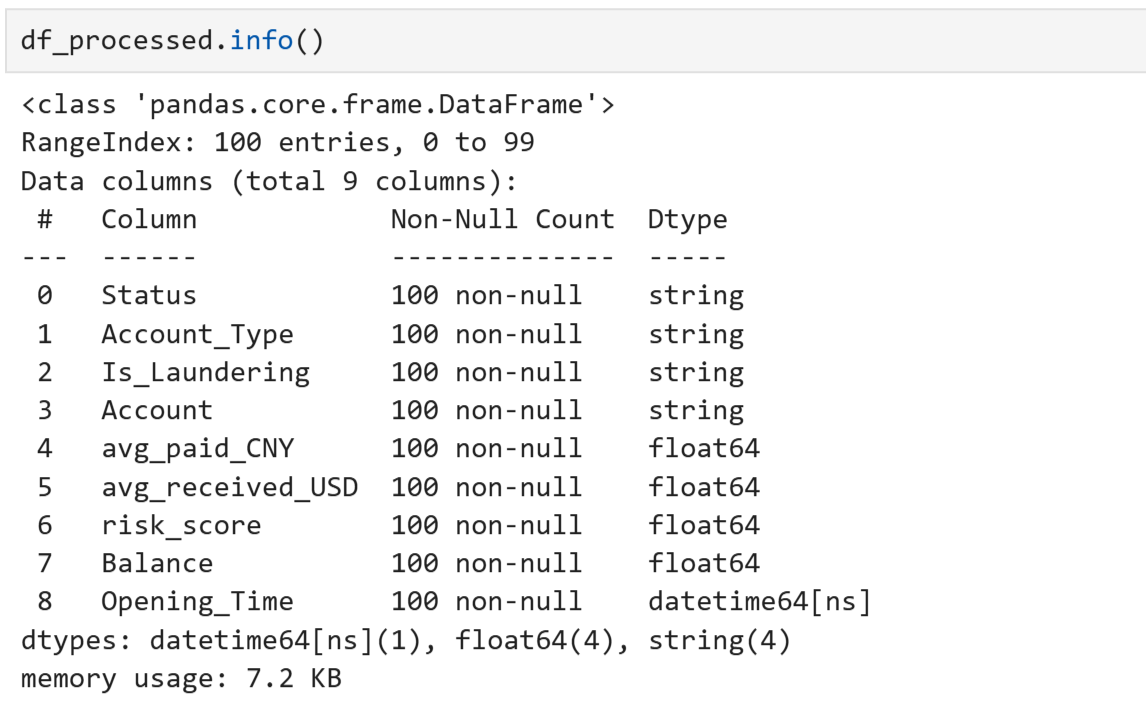
默认转换:只区分数字与字符串 ``` from tpf.data.deal import DataDeal as dtl df_processed = dtl.data_type_change(df_acc) df_processed.info() ``` 指定具体的列
```
from tpf.data.deal import DataDeal as dtl
# 执行类型转换
df_processed = dtl.data_type_change(
df_acc,
num_type=['avg_paid_CNY', 'avg_received_USD', 'risk_score', 'Balance'],
date_type=['Opening_Time']
)
```
```
df_acc.select_dtypes('number').columns.tolist()
#['avg_paid_CNY', 'avg_received_USD', 'risk_score', 'Is_Laundering', 'Balance']
```
|
```
from tpf.data.deal import Data2Feature as dtf
df = dtf.data_filter(df_tra,
data_dict={"From":['BOC_5000'],"To":['CCB_3141']},
type="remove")
df[:3]
```
- 此法可用于从全体数据中过滤掉出现过异常值的数据 - 比如,某个账户的交易金额异常,则从全体数据中过滤掉该账户的所有交易数据 - 剩下的数据,是从来没有发生过异常值的数据 |
|
|
类别编码
|
LabelEncoder
```
def df_label_encoder(df, columns):
le = preprocessing.LabelEncoder()
for i in columns:
df[i] = le.fit_transform(df[i].astype(str))
return df
```
``` df = df_label_encoder(df,['Payment Format', 'Payment Currency', 'Receiving Currency']) ``` 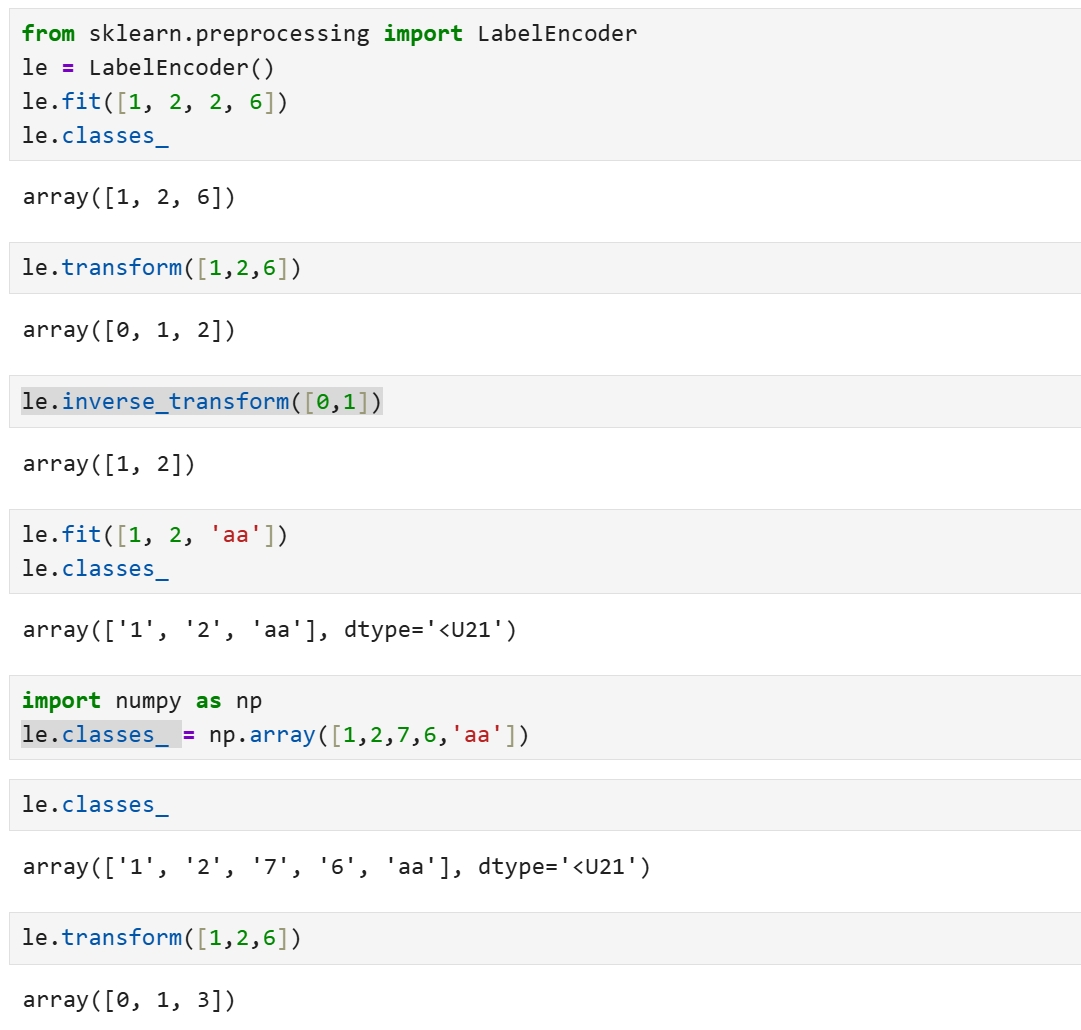
保存类别列表
```
from sklearn import preprocessing
from tpf import pkl_save,pkl_load
label_encoding_dict_path = "label_encoding_dict.pkl"
def df_label_encoder(df, columns,file_path):
if os.path.exists(file_path):
label_encoding_dict = pkl_load(file_path)
for i in columns:
le = preprocessing.LabelEncoder()
le.classes_ = label_encoding_dict[i]
df[i] = le.transform(df[i].astype(str))
else:
le = preprocessing.LabelEncoder()
label_encoding_dict = {}
for i in columns:
df[i] = le.fit_transform(df[i].astype(str))
label_encoding_dict[i] = le.classes_
pkl_save(label_encoding_dict,file_path=file_path)
return df
df = df_label_encoder(df,['Payment Format', 'Receiving Currency'],label_encoding_dict_path)
df[:3]
```
|
```
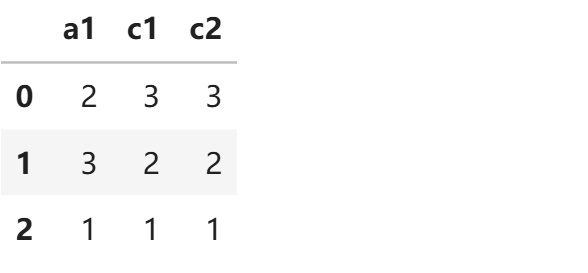
from tpf.data.deal import DataDeal as dtl
import pandas as pd
data = {
'a1':["a","b","c"],
"c1":["A","B","C"],
"c2":["A","D","E"]
}
df = pd.DataFrame(data)
print(df)
```
a1 c1 c2
0 a A A
1 b B D
2 c C E
各列独立编码
```
from tpf.data.deal import DataDeal as dtl
dtl.col2index(df,classify_type=['a1'],
dict_file="a1.dict",
is_pre=False)
df
```

```
from tpf.data.deal import DataDeal as dtl
dtl.col2index(df,classify_type=['a1','c1','c2'],
dict_file="a1.dict",
is_pre=False)
df
```
共享列编码
```
dtl.col2index(df,classify_type=['a1'],
classify_type2=[['c1','c2']],
dict_file="a1.dict",
is_pre=False,
word2id=None,)
df
```

预测
```
import pandas as pd
data = {
'a1':["a","b","c","a"],
"c1":["A","B","C","D"],
"c2":["A","D","E","F"]
}
df = pd.DataFrame(data)
```
- 预测时不需要再指定共享列, - 只是读取字典进行预测 - 指定了也没有关系,会自动合并 - 训练中未出现的列被编码为了 0
```
from tpf.data.deal import DataDeal as dtl
dtl.col2index(df,classify_type=['a1','c1','c2'],
dict_file="a1.dict",
is_pre=True)
df
```
|
|
训练
```
from tpf.data.deal import DataDeal as dtl
import pandas as pd
data = {
'a1':["a","b","c"],
"c1":["A","B","C"],
"c2":["A","D","E"]
}
df = pd.DataFrame(data)
```
```
from tpf.data.deal import DataDeal as dtl
dtl.col2index(df,classify_type=['a1','c1','c2'],
dict_file="a1.dict",
is_pre=False,start_index=1000)
df
```

预测
```
from tpf.data.deal import DataDeal as dtl
import pandas as pd
data = {
'a1':["a","b","c"],
"c1":["A","B","C"],
"c2":["A","D","E"]
}
df = pd.DataFrame(data)
```
预测主要使用的是字典
```
from tpf.data.deal import DataDeal as dtl
dtl.col2index(df,classify_type=['a1','c1','c2'],
dict_file="a1.dict",
is_pre=True,start_index=1000)
df
```

|
|
训练
```
from tpf.data.deal import DataDeal as dtl
import pandas as pd
data = {
'a1':["a","b","c"],
"c1":["A","B","C"],
"c2":["A","D","E"]
}
df = pd.DataFrame(data)
print(df)
```
```
from tpf.data.deal import Data2Feature as dtf
dtf.tonum_label_encoding(df,
file_path='ac1.dict',
is_pre=False,
force_rewrite=True)
```

预测
```
import pandas as pd
data = {
'a1':["a","b","c","a"],
"c1":["A","B","C","D"],
"c2":["A","D","E","F"]
}
df = pd.DataFrame(data)
```
```
dtf.tonum_label_encoding(df,
file_path='ac1.dict',
is_pre=True)
```

```
from tpf.data.make import JiaoYi as jy
df_accounts = jy.make_acc11()
df_acc= df_accounts.drop(columns=['Bank'])
df_acc[:3]
```
```
from tpf.data.deal import Data2Feature as dtf
df = dtf.data_type_change(df_acc)
```
tonum_label_encoding
```
Signature:
dtf.tonum_label_encoding(
df,
identity=[],
classify_type=[],
file_path=None,
is_pre=False,
force_rewrite=False,
)
Docstring:
对分类列进行LabelEncoder编码,支持训练和预测模式
Args:
df (pd.DataFrame): 输入的数据表
identity (list): 标识列列表,不参与编码,默认为空
classify_type (list): 需要编码的分类列名列表,如果为空或None则自动推断
file_path (str): 编码字典保存路径,如果为None则不保存/加载字典
is_pre (bool): 是否为预测模式,默认为False(训练模式)
force_rewrite (bool): 是否强制重新训练编码器,默认为False
```
```
dtf.tonum_label_encoding(df, identity=['Account'], file_path='acc.dict',
is_pre=False, force_rewrite=True)
```
```
dtf.tonum_label_encoding(df,
identity=['Account'],
file_path='acc.dict',
is_pre=True)
```
|
|
训练
```
from tpf.data.deal import Data2Feature as dtf
import pandas as pd
data = {
'a1':["a","b","c"],
"c1":["A","B","C"],
"c2":["A","D","E"]
}
df = pd.DataFrame(data)
```
```
dtf.tonum_col2index( df,
classify_type=['a1'],
classify_type2=[['c1','c2']],
dict_file='aa11.dict',
is_pre=False,
word2id=None,
start_index=1000,)
```

预测
```
import pandas as pd
data = {
'a1':["a","b","c","a"],
"c1":["A","B","C","D"],
"c2":["A","D","E","F"]
}
df = pd.DataFrame(data)
```
```
dtf.tonum_col2index( df,
classify_type=['a1','c1','c2'],
dict_file='aa11.dict',
is_pre=True)
```

```
from tpf.data.deal import Data2Feature as dtf
import pandas as pd
data = {
'a1':["a","b","c"],
"c1":["A","B","C"],
"c2":["A","D","E"]
}
df = pd.DataFrame(data)
print(df)
```
```
Signature:
dtf.tonum_col2index(
df,
identity=[],
classify_type=[],
classify_type2=[],
dict_file='dict_file.dict',
is_pre=False,
word2id=None,
start_index=1,
)
```
|
```
from tpf.data.deal import Data2Feature as dtf
import pandas as pd
data = {
'a1':["a","b","c"],
"c1":["A","B","C"],
"c2":["A","D","E"]
}
df = pd.DataFrame(data)
print(df)
```
使用identity指定标识列,默认/自动 对剩下的字符串列 进行编码
```
dtf.tonum_col2index(df,
identity=['a1'],
dict_file='dict_file22.dict',
is_pre=False,
start_index=1)
```
```
a1 c1 c2
0 a 3 2
1 b 1 1
2 c 2 3
```
```
import pandas as pd
data = {
'a1':["a","b","c","a"],
"c1":["A","B","C","D"],
"c2":["A","D","E","F"]
}
df = pd.DataFrame(data)
```
```
dtf.tonum_col2index(df,
identity=['a1'],
dict_file='dict_file22.dict',
is_pre=True,
start_index=1)
```
```
a1 c1 c2
0 a 3 2
1 b 1 1
2 c 2 3
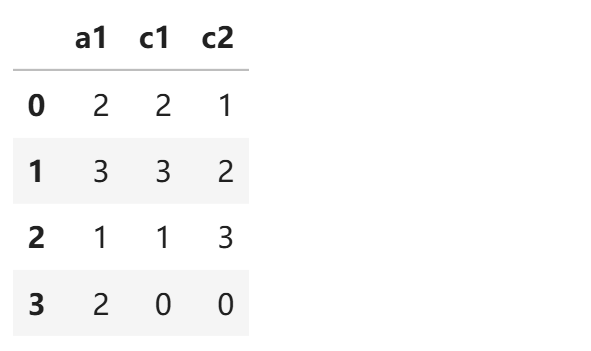
3 a 0 0
```
```
dtf.tonum_col2index( df,
classify_type=['c1','c2'],
dict_file='dict_file22.dict',
is_pre=True)
```
```
a1 c1 c2
0 a 3 2
1 b 1 1
2 c 2 3
3 a 0 0
```
|
|
类别编码:DataDeal
```
from tpf.data.deal import DataDeal as dtl
df_processed = dtl.col2index(df_processed,identity=['Account','Is_Laundering'],
dict_file="df_acc.dict",
is_pre=False,start_index=10000)
```

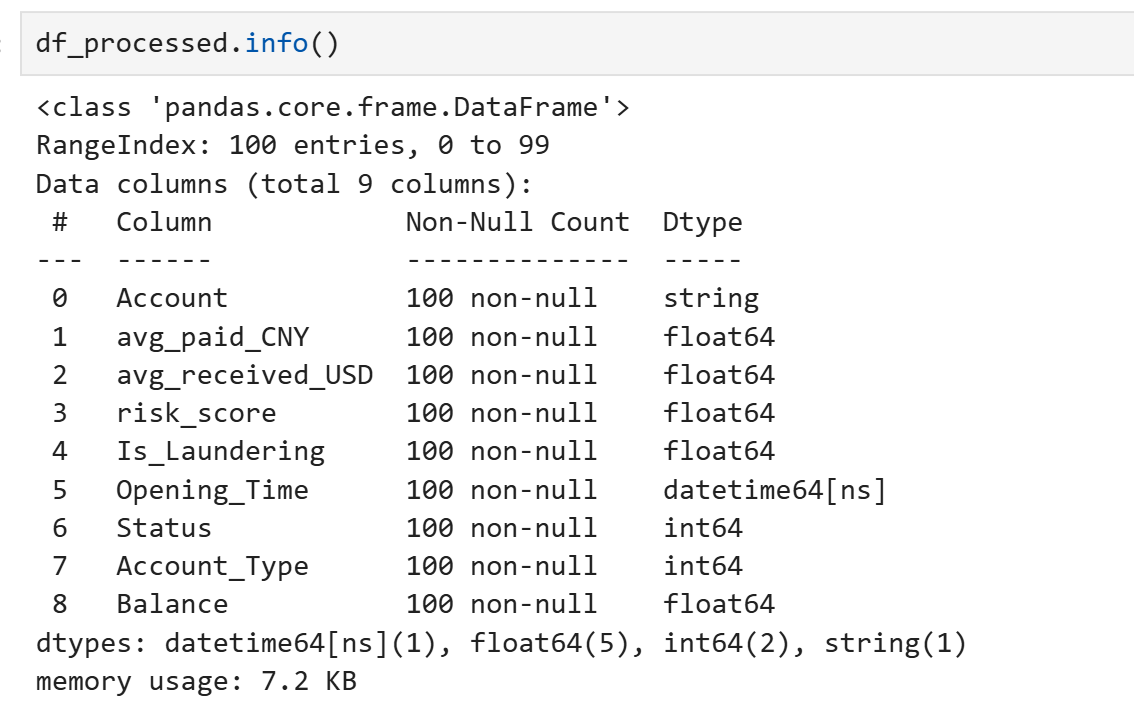
df_processed.info()
```
RangeIndex: 100 entries, 0 to 99
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Account 100 non-null string
1 avg_paid_CNY 100 non-null float64
2 avg_received_USD 100 non-null float64
3 risk_score 100 non-null float64
4 Is_Laundering 100 non-null float64
5 Opening_Time 100 non-null datetime64[ns]
6 Status 100 non-null int64
7 Account_Type 100 non-null int64
8 Balance 100 non-null float64
dtypes: datetime64[ns](1), float64(5), int64(2), string(1)
```
- 类型编码之后,除了日期就是数字
- identity标识列除外
|
|
|
数据聚合
|
按时间(天/小时)或类别 做聚合,可以减少数据量
```
from tpf.data.deal import DataDeal as dtl
identifys = [['From','time8'],['To','time8']]
num_type = ['Amount']
classify_type = ['Payment Format', 'Currency'],
col_time = 'dt_time'
# 一次提取一天的数据,滚动窗口处理
for s, e, df_sub in dtl.rolling_windows(
df=df,
col_time=col_time,
interval=interval,
win_len=win_len):
window_count += 1
print(f'\n处理第 {window_count} 个窗口: {s} ~ {e},记录数 {len(df_sub)}')
if len(df_sub) == 0:
# print(f" 窗口 {s} ~ {e} 没有数据,跳过")
continue
```
```
def data_agg_byday(df,
col_time='time8',
interval=1,
win_len=1,
identifys=[['From','time8'],['To','time8']],
num_type =['Amount'],
classify_type=['Payment Format', 'Currency'],
merge_del_cols=['From','To'],
new_col_name='key'):
"""
按天滚动窗口聚合交易数据
参数:
df: 输入的交易数据DataFrame
col_time: 时间列名,默认为'time8'
interval: 滚动间隔,默认为1天
win_len: 窗口长度,默认为1天
identifys: 分组标识列列表,默认为[['From','time8'],['To','time8']]
num_type: 数值类型列名列表,默认为['Amount']
classify_type: 分类类型列名列表,默认为['Payment Format', 'Currency']
merge_del_cols: 需要合并的列名列表,默认为['From','To']
new_col_name: 合并后的新列名,默认为'key'
返回:
df_final: 合并所有窗口结果的DataFrame
功能说明:
1. 使用滚动窗口按天处理交易数据
2. 对每个窗口的数据进行聚合统计(调用data_agg方法)
3. 将多个标识列合并为一个统一的关键列(调用cols_more2one方法)
4. 将所有窗口的结果合并为一个最终DataFrame返回
"""
# 创建空的DataFrame用于存储所有窗口的结果
df_final = pd.DataFrame()
print(f"开始按天滚动窗口聚合,时间列: {col_time}, 间隔: {interval}, 窗口长度: {win_len}")
# print(f"分组标识: {identifys}, 数值列: {num_type}, 分类列: {classify_type}")
window_count = 0
# 一次提取一天的数据,滚动窗口处理
for s, e, df_sub in dtl.rolling_windows(
df=df,
col_time=col_time,
interval=interval,
win_len=win_len):
window_count += 1
print(f'\n处理第 {window_count} 个窗口: {s} ~ {e},记录数 {len(df_sub)}')
if len(df_sub) == 0:
# print(f" 窗口 {s} ~ {e} 没有数据,跳过")
continue
# 1. 对当前窗口数据进行聚合统计
# print(f" 开始聚合统计...")
df_agg_by_day = data_agg(df_sub,
identifys=identifys,
num_type=num_type,
classify_type=classify_type)
# print(f" 聚合完成,结果形状: {df_agg_by_day.shape}")
# 2. 将多个标识列合并为一个关键列
if merge_del_cols and all(col in df_agg_by_day.columns for col in merge_del_cols):
# print(f" 合并列 {merge_del_cols} 为新列 '{new_col_name}'...")
df_agg_by_day = cols_more2one(df_agg_by_day,
cols=merge_del_cols,
new_col_name=new_col_name)
# print(f" 列合并完成,结果形状: {df_agg_by_day.shape}")
else:
print(f" 跳过列合并,检查列是否存在: {merge_del_cols}")
print(f" DataFrame列: {df_agg_by_day.columns.tolist()}")
# 3. 添加窗口时间信息
df_agg_by_day['window_start'] = s
df_agg_by_day['window_end'] = e
df_agg_by_day['window_seq'] = window_count
# 4. 将当前窗口结果合并到最终结果中
if df_final.empty:
df_final = df_agg_by_day.copy()
print(f" 初始化最终结果DataFrame,形状: {df_final.shape}")
else:
# 使用concat合并,保持列对齐
df_final = pd.concat([df_final, df_agg_by_day], ignore_index=True)
# print(f" 合并当前窗口结果,最终形状: {df_final.shape}")
# 可选:记录详细信息(如果需要调试)
# pc.lg(f"窗口 {s} ~ {e} 聚合完成,结果形状: {df_agg_by_day.shape}")
# pc.lg(f"窗口 {s} ~ {e} 聚合结果示例:\n{df_agg_by_day[:3]}")
print(f"\n所有窗口处理完成,共处理 {window_count} 个窗口")
print(f"最终结果形状: {df_final.shape}")
if not df_final.empty:
print(f"最终结果列: {df_final.columns.tolist()}")
print(f"窗口序列范围: {df_final['window_seq'].min()} ~ {df_final['window_seq'].max()}")
# 将窗口信息列移到最后
info_cols = ['window_start', 'window_end', 'window_seq']
other_cols = [col for col in df_final.columns if col not in info_cols]
df_final = df_final[other_cols]
# 将df_final中的NaN值替换为0
print(f"开始处理df_final中的NaN值...")
nan_before = df_final.isnull().sum().sum()
print(f"处理前NaN值总数: {nan_before}")
if nan_before > 0:
# 显示每列的NaN值数量
nan_by_col = df_final.isnull().sum()
cols_with_nan = nan_by_col[nan_by_col > 0]
if len(cols_with_nan) > 0:
# print("各列NaN值数量:")
for col, count in cols_with_nan.items():
print(f" {col}: {count}")
# 替换NaN值为0
df_final = df_final.fillna(0)
nan_after = df_final.isnull().sum().sum()
print(f"处理后NaN值总数: {nan_after}")
print("✓ 所有NaN值已替换为0")
else:
print("✓ df_final中没有NaN值")
return df_final
```
|
- 此处是交易,可以使用提取序列特征
|
|
|
|
|
|
|
归一化
|
reuse为True时,只要model_path存在就会直接加载模型进行预测,除非force_rewrite=True
```
from tpf.data.deal import DataDeal as dtl
df_processed = dtl.min_max_scaler(df_processed,
model_path='min_max_scaler.pkl',
reuse=True,
force_rewrite=True)
df_processed[:3]
```
force_rewrite=True则直接重新训练并保存,也就是覆盖了已有的模型文件
预测
```
df_processed = dtl.min_max_scaler(df_processed,
model_path='min_max_scaler.pkl',
reuse=True)
```
|
``` from tpf.data.make import JiaoYi as jy df_accounts = jy.make_acc11() df_acc= df_accounts.drop(columns=['Bank']) df_acc[:3] ``` 训练
```
dtf.norm_min_max_scaler(df_acc,
num_type=['avg_paid_CNY','avg_received_USD'],
model_path='min_max_scaler.pkl',
is_train=True,)
```
预测
```
dtf.norm_min_max_scaler(df_acc,
num_type=['avg_paid_CNY','avg_received_USD'],
model_path='min_max_scaler.pkl',
is_train=False,)
```
|
|
|
Data2Feature
数据读取
http://172.26.114.122:8888/lab/tree/fanxq/AIData/b17-min_max_update.ipynb
```
from tpf.data.make import JiaoYi as jy
df_accounts = jy.make_acc11()
df_acc= df_accounts.drop(columns=['Bank'])
df_acc[:3]
```

|
```
from tpf.data.deal import Data2Feature as dtf
dtf.show_col_type(df_acc)
```
```
Account object
avg_paid_CNY float64
avg_received_USD float64
risk_score float64
Is_Laundering int64
Opening_Time object
Status object
Account_Type object
Balance int64
dtype: object
```
```
dtf.show_unique_count(df_acc)
```
```
Account 100
avg_paid_CNY 100
avg_received_USD 96
risk_score 11
Is_Laundering 2
Opening_Time 100
Status 5
Account_Type 5
Balance 100
dtype: int64
```
```
dtf.show_describe(df_acc)
```
```
=== 数值列描述统计 ===
avg_paid_CNY avg_received_USD risk_score Is_Laundering Balance
count 100.000000 100.000000 100.000000 100.000000 100.000000
mean -0.007199 -0.057533 0.462000 0.320000 47608.440000
std 0.000015 0.000239 0.296369 0.468826 18866.497346
min -0.007231 -0.058140 0.000000 0.000000 1000.000000
25% -0.007207 -0.057672 0.200000 0.000000 36359.750000
50% -0.007199 -0.057535 0.500000 0.000000 49160.000000
75% -0.007190 -0.057372 0.700000 1.000000 60405.000000
max -0.007158 -0.056977 1.000000 1.000000 83742.000000
=== 数据基本信息 ===
总行数: 100
总列数: 9
缺失值总数: 0
内存使用: 0.04 MB
```
```
dtf.show_describe(df_acc,show_category=True)
```
```
=== 类别列描述统计 ===
列 'Account' 的统计信息:
唯一值数量: 100
缺失值数量: 0
前10个最频繁的值:
Account
PAB_7184 1
ICBC_6056 1
HXB_8721 1
CMB_7668 1
CCB_3693 1
BOC_2306 1
CCB_1663 1
PAB_8554 1
BOCOM_1854 1
BOC_9958 1
Name: count, dtype: int64
列 'Opening_Time' 的统计信息:
唯一值数量: 100
缺失值数量: 0
前10个最频繁的值:
Opening_Time
2025-10-09 14:36:54 1
2025-10-09 14:09:10 1
2025-10-09 04:34:58 1
2025-10-09 03:04:53 1
2025-10-09 00:30:27 1
2025-10-09 00:25:30 1
2025-10-08 20:21:57 1
2025-10-08 15:07:08 1
2025-10-08 13:28:08 1
2025-10-08 09:56:16 1
Name: count, dtype: int64
列 'Account_Type' 的统计信息:
唯一值数量: 5
缺失值数量: 0
前10个最频繁的值:
Account_Type
Investment 24
Savings 22
Business 19
Checking 18
Credit 17
Name: count, dtype: int64
列 'Status' 的统计信息:
唯一值数量: 5
缺失值数量: 0
前10个最频繁的值:
Status
Active 26
Frozen 22
Pending 20
Inactive 16
Closed 16
Name: count, dtype: int64
=== 数据基本信息 ===
总行数: 100
总列数: 9
缺失值总数: 0
内存使用: 0.04 MB
```
|
数据清洗 |
``` from tpf.data.make import JiaoYi as jy df_accounts = jy.make_acc11() df_acc= df_accounts.drop(columns=['Bank']) df_acc[:3] ``` 
指定num_type,date_type将剩下的做为字符串
```
from tpf.data.deal import Data2Feature as dtf
df = dtf.data_type_change(df,
num_type=['avg_paid_CNY', 'avg_received_USD', 'risk_score', 'Balance'],
date_type=['Opening_Time'])
```
自动识别
```
from tpf.data.deal import Data2Feature as dtf
df = dtf.data_type_change(df_acc)
df.info()
```
```
RangeIndex: 100 entries, 0 to 99
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Account 100 non-null string
1 avg_paid_CNY 100 non-null float64
2 avg_received_USD 100 non-null float64
3 risk_score 100 non-null float64
4 Is_Laundering 100 non-null float64
5 Opening_Time 100 non-null string
6 Status 100 non-null string
7 Account_Type 100 non-null string
8 Balance 100 non-null float64
dtypes: float64(5), string(4)
memory usage: 7.2 KB
```
DataDeal.data_type_change:指定数字与日期后,剩下的为字符串列
```
dtl.data_type_change(
data,
num_type=None,
classify_type=None,
date_type=None,
)
Docstring:
将pandas数表的类型转换为特定的类型
Args:
data: pandas DataFrame, 输入的数据表
num_type: list, 需要转换为数值类型的列名列表,如果为空或None则自动推断所有数值列
classify_type: list, 需要转换为类别类型的列名列表,如果为空或None则自动推断剩余非数值非日期列
date_type: list, 需要转换为日期类型的列名列表
```
示例 ``` from tpf.data.make import JiaoYi as jy df_accounts = jy.make_acc11() df_acc= df_accounts.drop(columns=['Bank']) ``` 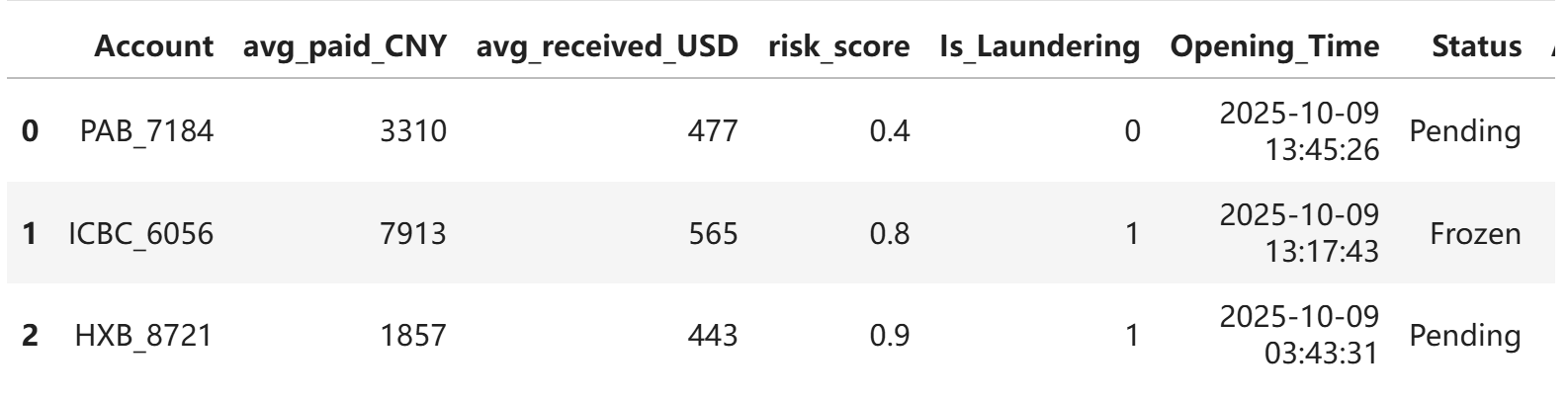
没有指定数字时,以默认的数字类型为num_type
```
from tpf.data.deal import DataDeal as dtl
# 执行类型转换
df_processed = dtl.data_type_change(
df_acc,
date_type=['Opening_Time']
)
df_processed.info()
```
|
http://172.26.114.122:8888/lab/tree/fanxq/AIData/b16.ipynb
```
from tpf.data.make import JiaoYi as jy
df_accounts = jy.make_acc11()
df_acc= df_accounts.drop(columns=['Bank'])
df_acc[:3]
```

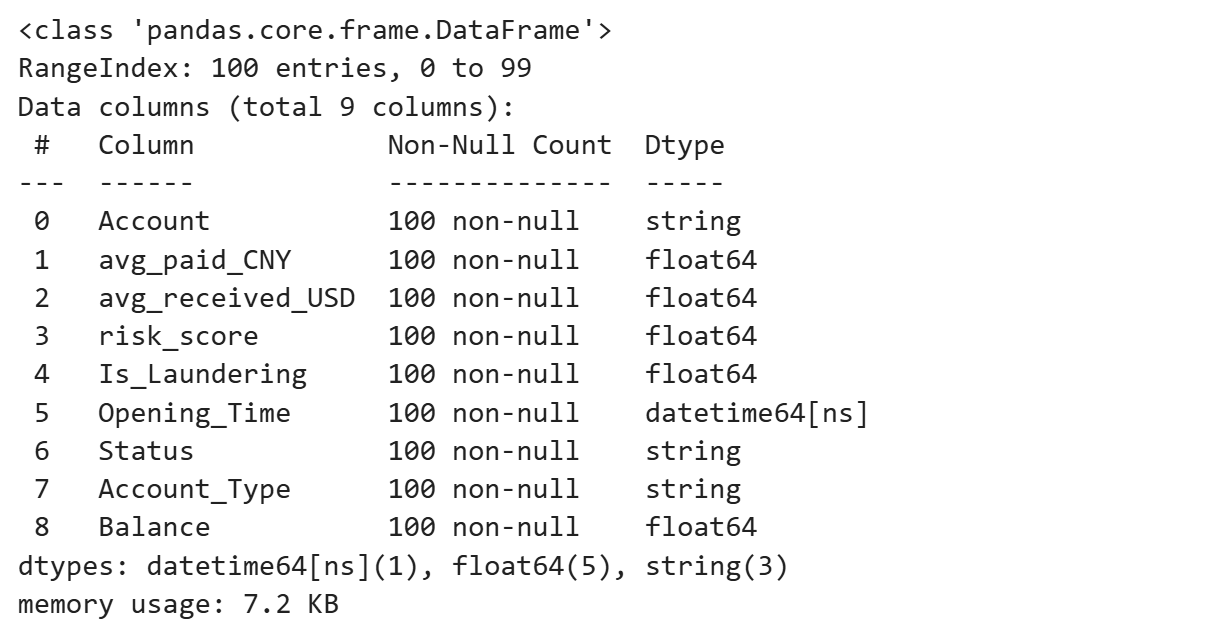
类型转换
```
from tpf.data.deal import DataDeal as dtl
# 执行类型转换
df_processed = dtl.data_type_change(
df_acc,
date_type=['Opening_Time']
)
df_processed.info()
```
类别编码
```
from tpf.data.deal import DataDeal as dtl
df_processed = dtl.col2index(df_processed,identity=['Account','Is_Laundering'],
dict_file="df_acc.dict",
is_pre=False,start_index=10000)
```

- 类别编码之后
- 标签列为string类型
- 日期为datetime64[ns]类型
- 剩下为数字类型
数字归一化
```
df_processed = dtl.min_max_scaler(df_processed,
model_path='min_max_scaler.pkl',
reuse=True,
force_rewrite=True)
df_processed[:3]
```

日期归一化
```
df = dtl.min_max_scaler_dt(df_processed,
date_type=['Opening_Time'],
scaler_file='min_max_scaler_dt.pkl',
max_date='2035-01-01',
adjust=True,)
df[:3]
```

|
``` from tpf.data.make import JiaoYi as jy df_tra = jy.make_trans11() df_tra[:3] ``` 
```
from tpf.data.deal import Data2Feature as dtf
df = dtf.data_filter(df_tra,
data_dict={"From":['BOC_5000'],"To":['CCB_3141']},
type="remove")
df[:3]
```

|
|
数字归一化
```
from tpf.data.deal import DataDeal as dtl
df_processed = dtl.min_max_scaler(df_processed,
model_path='min_max_scaler.pkl',
reuse=True,
force_rewrite=True)
df_processed[:3]
```

日期归一化
```
df = dtl.min_max_scaler_dt(df_processed,
date_type=['Opening_Time'],
scaler_file='min_max_scaler_dt.pkl',
max_date='2035-01-01',
adjust=True,)
df[:3]
```

|
``` from tpf.data.make import JiaoYi as jy df_tra = jy.make_trans11() df_tra[:3] ``` 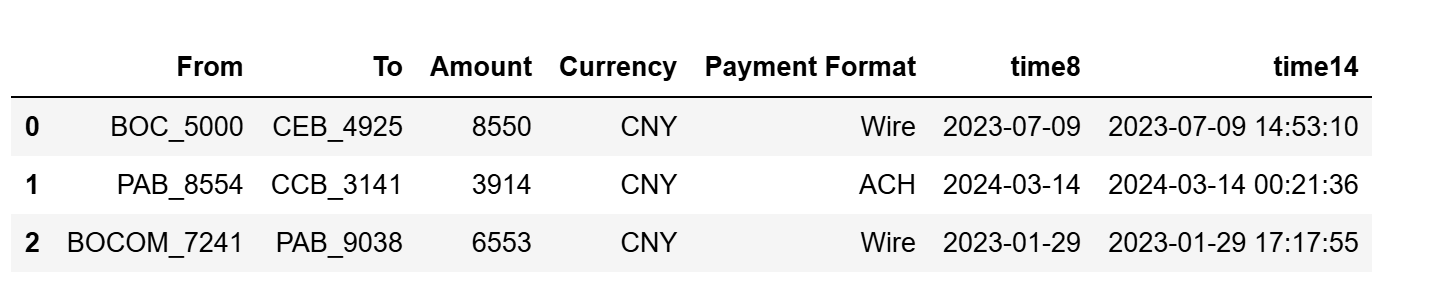
```
from tpf.data.deal import Data2Feature as dtf
df = dtf.data_filter(df_tra,
data_dict={"From":['BOC_5000'],"To":['CCB_3141']},
type="remove")
df[:3]
```

- 此法可用于从全体数据中过滤掉出现过异常值的数据 - 比如,某个账户的交易金额异常,则从全体数据中过滤掉该账户的所有交易数据 - 剩下的数据,是从来没有发生过异常值的数据 |
```
from tpf.data.deal import Data2Feature as dtf
dtf.data_make(
data_type={
'numf': 'float32',
'num': 'int32',
'date': 'yyyy-mm-dd',
'classify': 'string'},
num_rows=100,)
```
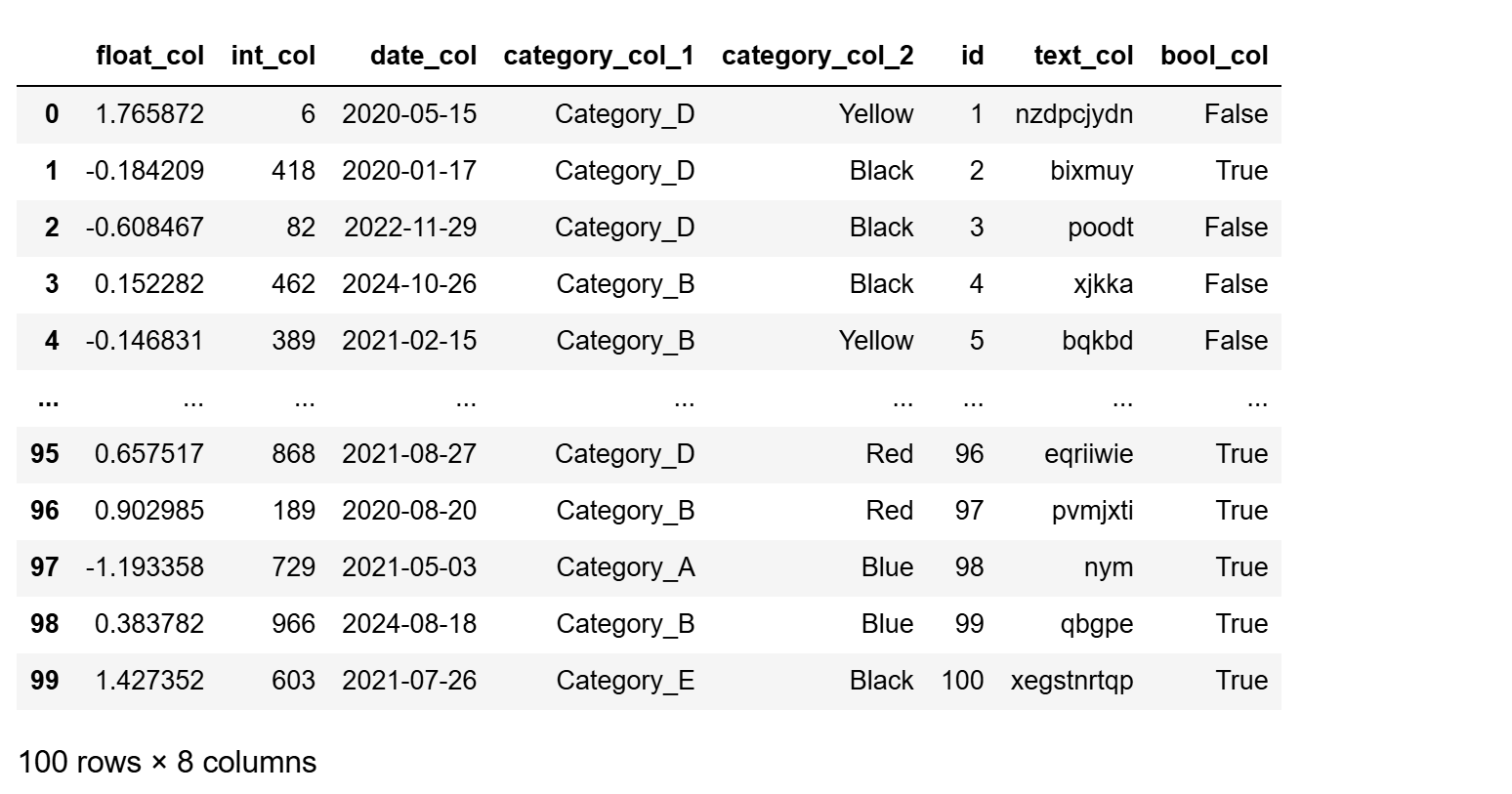
|
```
from tpf.data.deal import Data2Feature as dtf
df = dtf.data_make(
data_type={'numf': 'float32',
'num': 'int32',
'date': 'datetime64[ns]',
'classify': 'string' },
num_rows=1000)
df[:3]
```
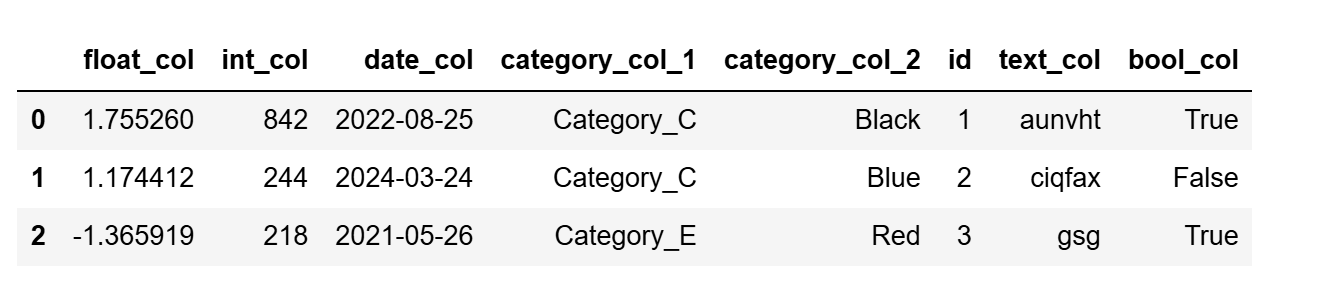
按类别采样,每个类别都采样一定的数据
```
df_sub = dtf.data_sample_cat(df,
n=10,
indetify=['id'],
cat_cols=['category_col_1','category_col_2'],
time_col='date_col',)
df_sub[:3]
```


|
``` from tpf.data.make import JiaoYi as jy df_tra = jy.make_trans11() df_tra[:3] ```
```
# 调用按天聚合方法
print("开始调用data_agg_byday方法进行按天聚合...")
df_final_result = dtf.data_agg_byday(
df=df_tra,
col_time='time8',
interval=1,
win_len=1,
identifys=[['From','time8'],['To','time8']],
num_type=['Amount'],
classify_type=['Payment Format', 'Currency'],
merge_del_cols=['From','To'],
new_col_name='key'
)
```
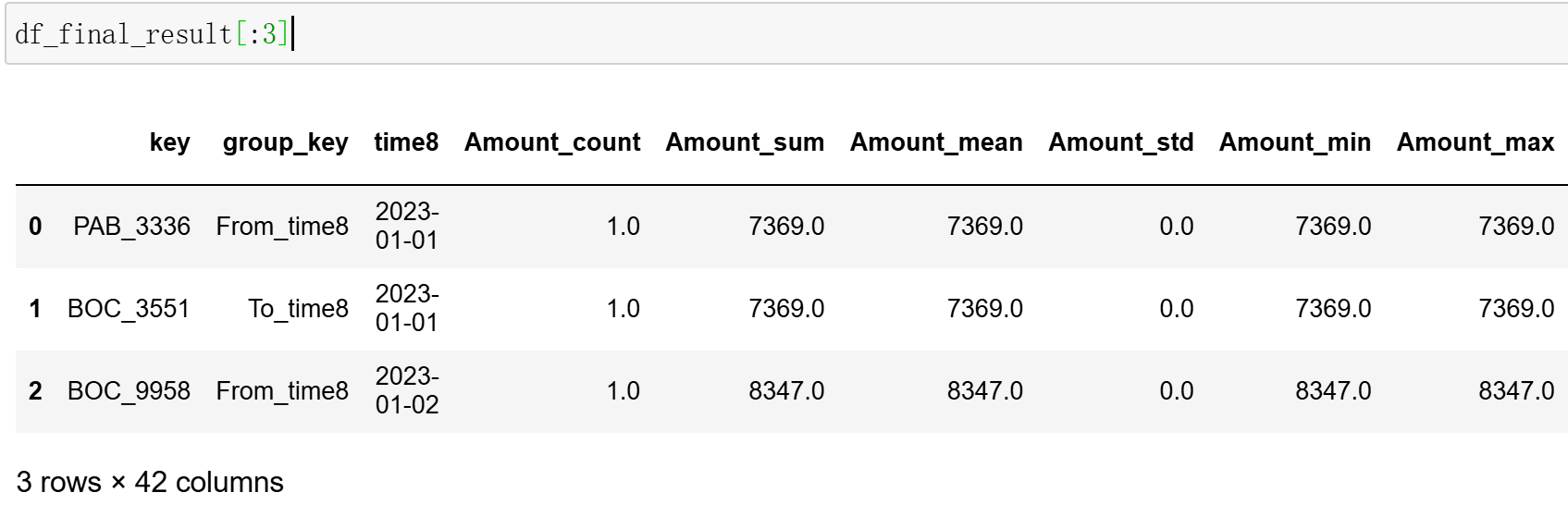
- 每个类别聚合的统计指针不多,还需要详细看一下原因 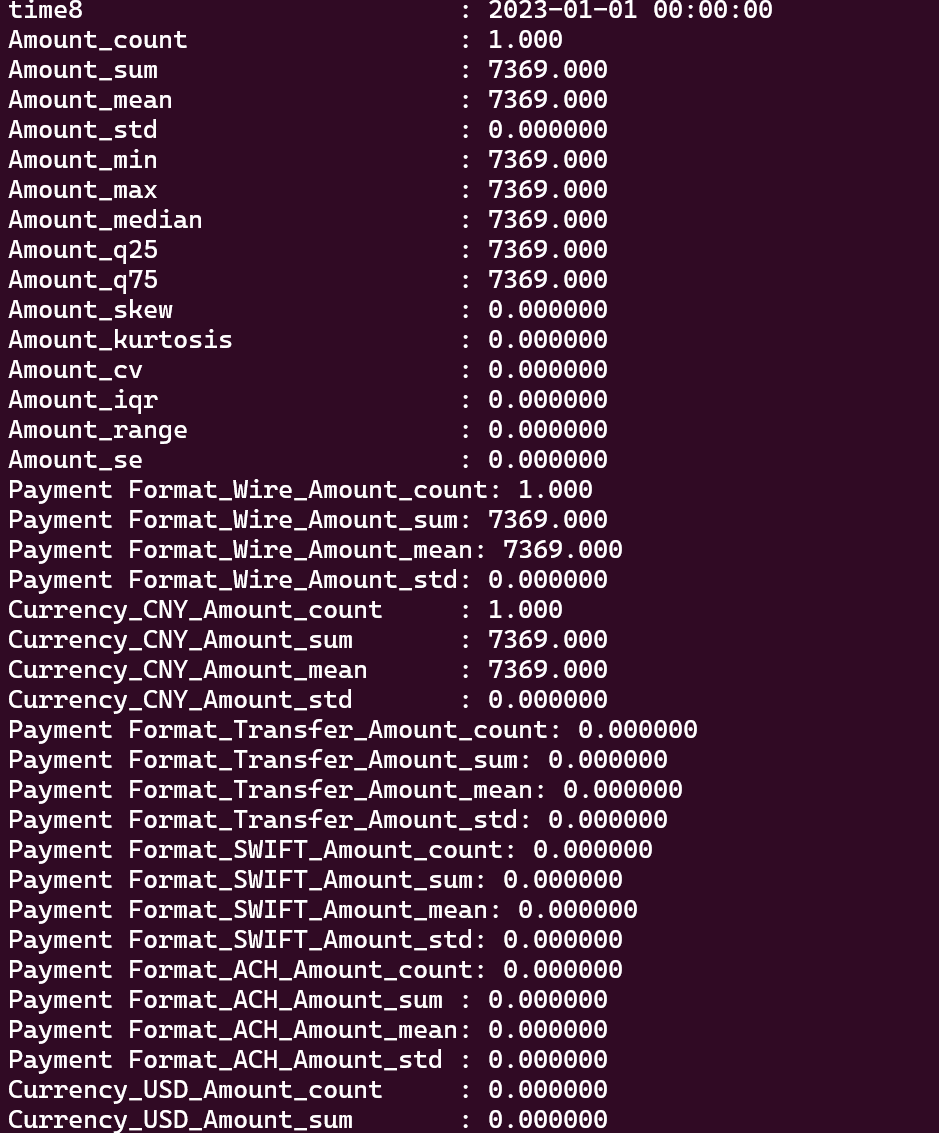
```
from tpf.data.deal import Data2Feature as dtf
dtf.data_agg(df_tra,
identifys=[['From', 'time8'], ['To', 'time8']],
num_type=['Amount'],
classify_type=['Payment Format', 'Currency'],
stat_lable=['count', 'median', 'q25', 'q75', 'skew', 'kurtosis', 'cv', 'iqr', 'range', 'se'],
)
```
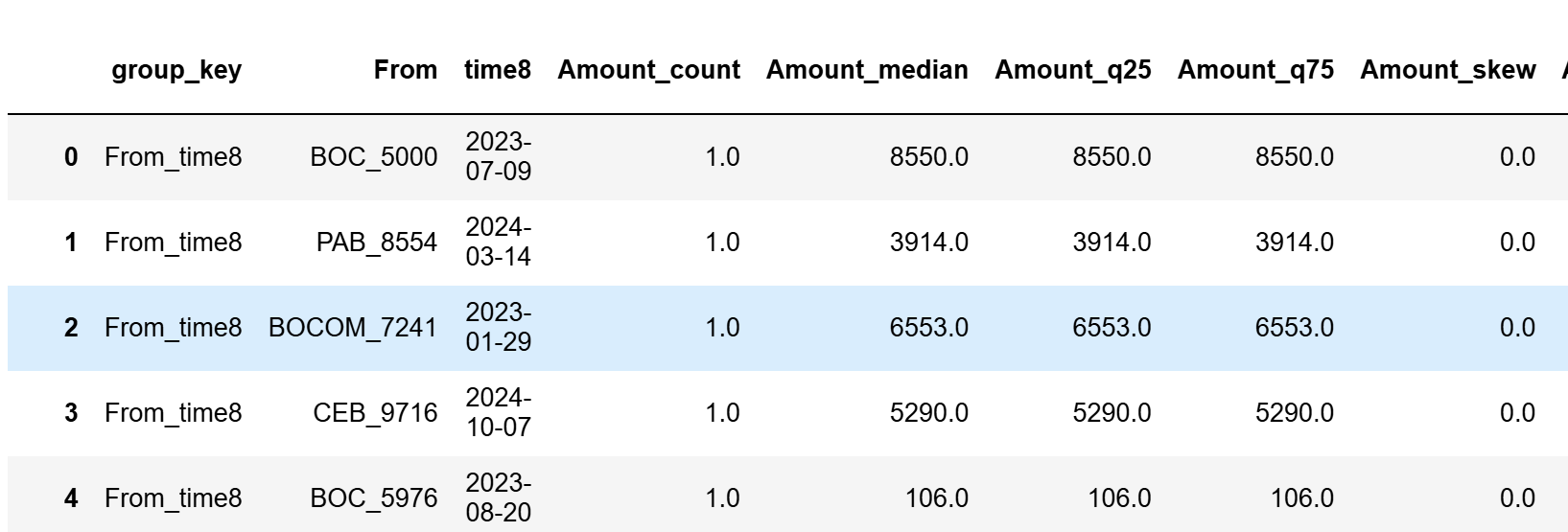
|
|
|
参考