SVM 支持向量机
|
### 一句话理解SVM
想象你在操场上,男生站左边,女生站右边,中间有一条线把他们分开。
SVM就是要找到这样一条线,让这条线离两边最近的人越远越好。
离线最近的那几个人,就叫"支持向量"。
### 生活中的例子
比如银行要判断一个客户会不会违约:
- 客户的特征有:年龄、收入、负债比、信用分等
- 历史数据中,有些客户违约了,有些没有
- SVM就是在这些特征空间中画一条线(或超平面),把"违约"和"不违约"两类人分开
关键是:这条线要离两边的边界客户都尽量远,这样判断新客户时才更准。
### SVM主要分为三类
**线性可分支持向量机(硬间隔)**:
当训练数据线性可分时,可通过硬间隔最大化,学习一个线性的分类器。
存在一个唯一的超平面,能够将所有样本点完全正确地分开,且使得间隔最大化。
**线性支持向量机(软间隔)**:
当训练数据近似线性可分时,可通过软间隔最大化,学习一个线性的分类器。
允许少量样本点被错误分类,以换取更大的间隔,从而提高分类器的鲁棒性。
**非线性支持向量机**:
当训练数据线性不可分时,通过使用核函数技巧及软间隔最大化,学习一个非线性的支持向量机。
核函数将原始数据映射到高维空间,使得在高维空间中数据变得线性可分。
### 优缺点
**优点**:
- 使用核函数可以向高维空间进行映射,解决非线性分类问题
- 分类思想简单,即将样本与决策面的间隔最大化
- 分类效果较好,特别是在高维空间中
**缺点**:
- 对大规模训练样本难以实施,计算复杂度较高
- 解决多分类问题存在困难,通常需要通过组合多个二分类器来实现
- 对缺失数据敏感,对参数和核函数的选择敏感
|
|
### 基本原理
机器学习算法支持向量机(Support Vector Machine,简称SVM)的原理
SVM是一种监督式学习的方法,广泛应用于统计分类以及回归分析。
其基本原理是找到一个超平面,将不同类别的样本数据分开,并使得间隔最大化。
间隔是指超平面与两个最近的样本点之间的距离,通过最大化间隔,可以提高分类器的鲁棒性和泛化能力。
### 超平面与间隔的数学表达
**超平面方程**:
在 $n$ 维空间中,分类超平面可以表示为:
$$w^T x + b = 0$$
其中 $w$ 是法向量(权重),$b$ 是偏置项。
**分类决策函数**:
$$f(x) = \text{sign}(w^T x + b)$$
当 $f(x) = +1$ 时为一类,$f(x) = -1$ 时为另一类。
**函数间隔**:
对于样本点 $(x_i, y_i)$,函数间隔定义为:
$$\hat{\gamma}_i = y_i (w^T x_i + b)$$
**几何间隔**:
$$\gamma_i = \frac{y_i (w^T x_i + b)}{\|w\|}$$
### SVM的优化目标
**硬间隔最大化**(线性可分时):
$$\max_{w,b} \quad \gamma = \frac{2}{\|w\|}$$
等价于:
$$\min_{w,b} \quad \frac{1}{2} \|w\|^2$$
$$\text{s.t.} \quad y_i(w^T x_i + b) \geq 1, \quad i = 1,2,...,N$$
**软间隔最大化**(近似线性可分时),引入松弛变量 $\xi_i$:
$$\min_{w,b,\xi} \quad \frac{1}{2}\|w\|^2 + C \sum_{i=1}^{N}\xi_i$$
$$\text{s.t.} \quad y_i(w^T x_i + b) \geq 1 - \xi_i, \quad \xi_i \geq 0$$
其中 $C$ 是惩罚系数,$C$ 越大对误分类惩罚越大。
### 关键概念
**间隔和边界**:
SVM的目标是找到一个超平面,能够将不同类别的样本数据分开,并且使得间隔最大化。
间隔是指超平面与两个最近的样本点之间的距离,
而边界是指超平面两侧的样本点构成的区域。
**支持向量**:
在SVM中,只有位于边界上的样本点才对分类决策起作用,这些样本点被称为支持向量。
支持向量是决定超平面位置的关键因素,因为它们确定了分类边界的位置和姿态。
**核函数**:
对于非线性可分的数据,SVM引入了核函数的概念。
核函数能够将原始的特征空间映射到一个更高维度的特征空间,
使得原本线性不可分的样本在该高维空间中线性可分。
核函数的数学定义为:
$$K(x_i, x_j) = \phi(x_i)^T \phi(x_j)$$
常见的核函数有:
| 核函数 | 公式 |
|--------|------|
| 线性核 | $K(x_i, x_j) = x_i^T x_j$ |
| 多项式核 | $K(x_i, x_j) = (\gamma x_i^T x_j + r)^d$ |
| 高斯核(RBF) | $K(x_i, x_j) = \exp(-\gamma \|x_i - x_j\|^2)$ |
| Sigmoid核 | $K(x_i, x_j) = \tanh(\gamma x_i^T x_j + r)$ |
### 算法步骤
1. 导入数据
2. 数据归一化(可选,但通常有助于算法的稳定性和性能)
3. 执行SVM算法,寻找最优的超平面
4. 绘制分类超平面和支持向量(可选,用于可视化)
5. 对于非线性问题,选择合适的核函数,执行非线性SVM
|
|
### SVC概述
SVC(Support Vector Classification,支持向量分类)算法是SVM中的分类算法,
主要用于解决二分类或多分类问题。
以2维平面为例,数据投影到2维平面上后,
相同类别的数据会相互靠近,不同类别的数据间隔会远一些,就是物以类聚。
SVM会在平面上画一条曲线,根据不同类别边缘的样本画线,这样的曲线可以将不同类别的样本划分开。
如果2维平面分不开,SVM会将数据投影到更高的维度上,此时这样的线称为超平面。
边缘样本中被SVM使用的样本向量,就是支持向量。
### SVC背后的数学原理
基于线性可分的支持向量机(SVM),
当数据不是线性可分时,
可以通过引入松弛变量和使用核技巧将数据映射到更高维的空间,
使原本线性不可分的数据在高维空间中变得线性可分。
### 代码示例
```python
from sklearn.datasets import load_breast_cancer
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import numpy as np
# 加载乳腺癌数据集
data = load_breast_cancer()
X = data.data
y = data.target
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 分割数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X_scaled, y, test_size=0.2, random_state=42
)
# 训练SVC模型,并设置probability=True以生成预测概率
svc = SVC(kernel='rbf', gamma='auto', C=1.0, probability=True)
svc.fit(X_train, y_train)
# 输出测试集的预测概率
y_probs = svc.predict_proba(X_test)
print(y_probs.shape)
```
### SVC常用参数
**C**:惩罚系数,用于控制误分类点的影响
- C越大,分类的准确性通常越高,但也可能导致过拟合,模型会仔细区分边缘,精细挑选支持向量
- C越小,模型越简单,但可能欠拟合,从边缘向量中大致选一批支持向量
**kernel**:核函数
- 用于将非线性可分的训练样本转换成线性可分的样本
- 常用的核函数包括线性核函数(linear)、多项式核函数(polynomial)、高斯核函数(rbf)等
**gamma**:核函数的系数
- 主要影响支持向量的形成
- gamma的值设置得合适时,能够最大化支持向量的训练效果
**degree**:多项式核函数的参数
- 用于改变模型的复杂度
- degree的值越大,模型的复杂度越高,但也可能导致过拟合
|
|
### 合页损失函数(Hinge Loss)
合页损失函数是SVM中用于分类任务的一种损失函数。
**定义**:合页损失函数是一种用于二分类问题的损失函数,其目的是使分类间隔最大化。
对于给定的样本点 $(x, y)$,其中 $x$ 是特征向量,$y$ 是目标标签(通常为 $+1$ 或 $-1$)。
**公式**:
$$L(y, t) = \max(0, 1 - t \cdot y)$$
其中 $t$ 是分类器的预测值,$y$ 是真实标签。
**含义解读**:
- 当 $t \cdot y \geq 1$ 时(分类正确且间隔足够大):$L = 0$,损失为0
- 当 $0 < t \cdot y < 1$ 时(分类正确但间隔不够):$L = 1 - ty$,有损失
- 当 $t \cdot y \leq 0$ 时(分类错误):$L = 1 - ty$,损失较大
**与其他损失函数对比**:
| 损失函数 | 公式 | 特点 |
|---------|------|------|
| 0-1损失 | $L = \mathbb{1}[y \neq \hat{y}]$ | 不可导,不实用 |
| 平方损失 | $L = (y - \hat{y})^2$ | 对异常值敏感 |
| 合页损失 | $L = \max(0, 1 - ty)$ | 体现间隔概念,对异常值鲁棒 |
### SVM与合页损失函数的关系
SVM的优化目标等价于最小化合页损失:
$$\min_{w,b} \quad \frac{1}{2}\|w\|^2 + C \sum_{i=1}^{N} \max(0, 1 - y_i(w^T x_i + b))$$
合页损失函数能够直接体现分类间隔的概念,并且对异常点(噪声或离群点)的鲁棒性较好。
|
|
### SVM重要参数总览
**一、C参数**
$C$ 是正则化参数,用于控制模型的复杂度。它相当于惩罚松弛变量的强度。
$$\min_{w,b,\xi} \quad \frac{1}{2}\|w\|^2 + C \sum_{i=1}^{N}\xi_i$$
- $C$ 值越小,模型越简单,对误分类的惩罚越小,允许一定的容错,泛化能力较强,但可能导致欠拟合
- $C$ 值越大,模型越复杂,对误分类的惩罚越大,追求更高的分类准确率,但可能导致过拟合
**二、kernel参数**
核函数,用于将原始特征映射到高维空间:
| 取值 | 说明 |
|------|------|
| linear | 线性核,$K(x_i,x_j) = x_i^T x_j$ |
| poly | 多项式核,$K(x_i,x_j) = (\gamma x_i^T x_j + r)^d$ |
| rbf | 高斯核,$K(x_i,x_j) = e^{-\gamma\|x_i-x_j\|^2}$ |
| sigmoid | $K(x_i,x_j) = \tanh(\gamma x_i^T x_j + r)$ |
**三、degree参数**
多项式核函数的次数 $d$,仅对多项式核函数有效。
**四、gamma参数**($\gamma$)
控制高斯核/多项式核的影响范围:
$$K(x_i, x_j) = \exp\left(-\gamma \|x_i - x_j\|^2\right)$$
- $\gamma$ 越小,决策边界更平滑,泛化能力更强,但可能欠拟合
- $\gamma$ 越大,决策边界更复杂,可能过拟合
- 默认值 `"scale"`:$\gamma = \frac{1}{n_{\text{features}} \cdot \text{Var}(X)}$
**五、coef0参数**($r$)
多项式核和Sigmoid核中的常数项。仅对 `'poly'` 和 `'sigmoid'` 有效。
- $r$ 较小时,核函数形状平滑,泛化能力好
- $r$ 较大时,核函数形状尖锐,可能过拟合
**六、其他参数**
- `probability`:是否计算每个类别的概率,默认为False
- `shrinking`:是否使用启发式的shrinking算法,默认为True
- `tol`:终止条件中的容限值
- `cache_size`:内存大小,用于缓存核函数计算的结果
- `class_weight`:类别权重,处理类别不平衡问题。`balanced` 自动调整,或如 `{0:1, 1:10}`
- `max_iter`:最大迭代次数
- `decision_function_shape`:`ovo`(一对一,$k(k-1)/2$个分类器)或 `ovr`(一对多,$k$个分类器)
|
|
```python
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import classification_report, accuracy_score
# 加载乳腺癌数据集
data = datasets.load_breast_cancer()
X = data.data
y = data.target
# 数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# 特征缩放
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 设置SVC的参数
svc = SVC(
kernel='rbf', gamma='scale', C=1.0,
class_weight='balanced', max_iter=10000,
decision_function_shape='ovr'
)
# 训练模型
svc.fit(X_train, y_train)
# 预测
y_pred = svc.predict(X_test)
# 评估模型
print("Accuracy:", accuracy_score(y_test, y_pred))
print("Classification Report:\n", classification_report(y_test, y_pred))
```
|
HMM 隐马尔可夫模型
|
### 一句话理解HMM
想象你在隔壁房间,只能听到里面传出的声音(观察到的),
但看不到里面的人在做什么(隐藏的状态)。
你通过听到的声音,来推测里面的人正在做什么。
这就是HMM——通过"看得见的观测"来推测"看不见的状态"。
### 生活中的例子
**天气与衣着**:
- 你每天能看到朋友穿什么衣服(观测序列)
- 但你不知道那天的天气(隐藏状态)
- 晴天→穿短袖的概率高,雨天→穿外套的概率高
- 天气之间也有关系:晴天之后大概率还是晴天
通过连续几天看到朋友穿的衣服,你可以推测这几天的天气变化。
这就是HMM做的事:通过观测序列推测隐藏状态序列。
### HMM的适用场景
隐马尔可夫模型(HMM):是结构最简单的动态贝叶斯网络,是一种尤其著名的有向图结构,
主要用于时序数据的建模,在语音识别、自然语言处理等领域有广泛应用,
在分词算法中,隐马尔可夫经常用作能够发现新词的算法,
通过海量的数据学习,能够将人名、地名、互联网上的新词等一一识别出来,具有广泛的应用场景。
|
|
### HMM是什么
双序列事件:
- 序列1相互独立
- 序列2存在前后依赖关系
- 序列1的每个事件的发生由序列2对应的事件决定
HMM是双重随机过程形成的两个序列:一个叫**观测序列**,一个叫**隐藏序列**,满足以下三个条件:
1. 观测序列的事件相互独立
2. 隐藏序列的事件(这里叫状态)仅前后存在依赖关系
3. 观测序列事件发生的概率由隐藏序列对应的状态决定,观测序列与隐藏序列事件一一对应
- **观测**:已有统计数据,观察到的统计数据,容易得到或已知数据
- **隐藏**:有了部分数据,不那么容易直接拿到,需要训练个模型预测的数据
### HMM五元组
HMM由以下五个要素完整描述,记为 $\lambda = (A, B, \pi)$:
| 符号 | 名称 | 说明 |
|------|------|------|
| $O$ | 观测序列 | 已观测到的数据序列 $O = (o_1, o_2, ..., o_T)$ |
| $I$ | 隐藏状态序列 | 需要推测的状态序列 $I = (i_1, i_2, ..., i_T)$ |
| $\pi$ | 初始状态概率 | $\pi_i = P(i_1 = s_i)$,初始时刻各状态的概率 |
| $A$ | 状态转移矩阵 | $a_{ij} = P(i_{t+1} = s_j \mid i_t = s_i)$,状态间的转移概率 |
| $B$ | 观测概率矩阵 | $b_j(k) = P(o_t = v_k \mid i_t = s_j)$,某状态下观测值的概率 |
### 两个基本假设
**1. 齐次马尔科夫性假设**:在 $t$ 时刻的状态只依赖于 $t-1$ 时刻的状态
$$P(i_t \mid i_{t-1}, i_{t-2}, ..., i_1) = P(i_t \mid i_{t-1})$$
**2. 观测独立性假设**:在任一时刻的观测只依赖于该时刻的状态
$$P(o_t \mid i_T, i_{T-1}, ..., i_1, o_T, ..., o_1) = P(o_t \mid i_t)$$
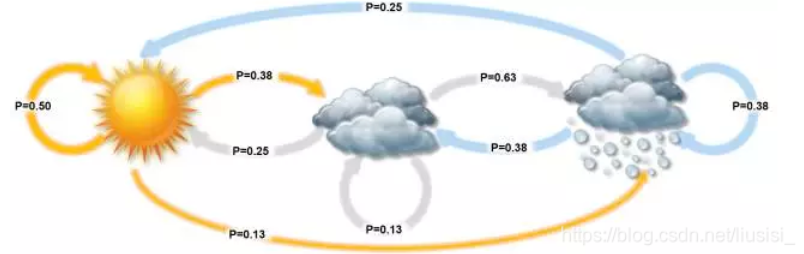
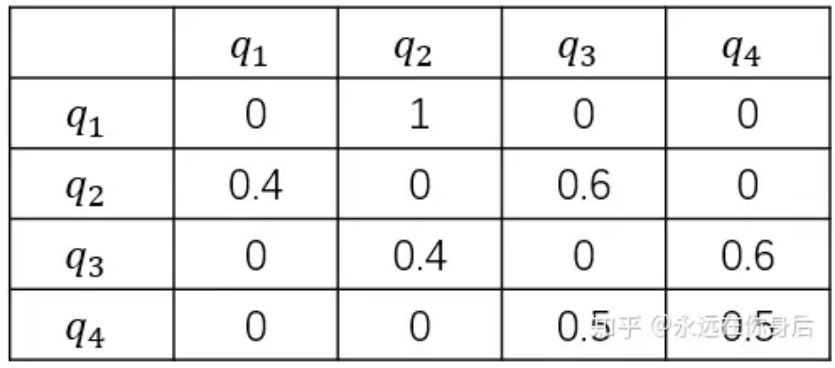
### 状态转移矩阵 A
状态转移矩阵必是方阵,每个元素 $a_{ij}$ 表示从状态 $s_i$ 转移到状态 $s_j$ 的概率:
$$A = \begin{bmatrix} a_{11} & a_{12} & \cdots & a_{1N} \\ a_{21} & a_{22} & \cdots & a_{2N} \\ \vdots & \vdots & \ddots & \vdots \\ a_{N1} & a_{N2} & \cdots & a_{NN} \end{bmatrix}$$
约束条件:$a_{ij} \geq 0$,且 $\sum_{j=1}^{N} a_{ij} = 1$
状态 $s_1$ 永远都不可能转移到状态 $s_3$,则 $a_{13} = 0$。
每个状态转移到的状态可以是自己,也可以是其他状态。

 ### HMM解决三类问题
| 问题 | 描述 | 算法 |
|------|------|------|
| 解码问题 | 给定 $\lambda$ 和 $O$,求最优隐藏状态序列 $I^*$ | **Viterbi算法** |
| 评估问题 | 给定 $\lambda$ 和 $O$,计算 $P(O \mid \lambda)$ | **前向/后向算法** |
| 学习问题 | 仅给定 $O$,估计模型参数 $\lambda$ | **EM算法(Baum-Welch)** |
**Viterbi算法**的目标:
$$I^* = \arg\max_I P(I \mid O, \lambda)$$
**前向概率** $\alpha_t(i)$:
$$\alpha_t(i) = P(o_1, o_2, ..., o_t, i_t = s_i \mid \lambda)$$
递推公式:
$$\alpha_{t+1}(j) = \left[\sum_{i=1}^{N} \alpha_t(i) \cdot a_{ij}\right] \cdot b_j(o_{t+1})$$
### HMM解决三类问题
| 问题 | 描述 | 算法 |
|------|------|------|
| 解码问题 | 给定 $\lambda$ 和 $O$,求最优隐藏状态序列 $I^*$ | **Viterbi算法** |
| 评估问题 | 给定 $\lambda$ 和 $O$,计算 $P(O \mid \lambda)$ | **前向/后向算法** |
| 学习问题 | 仅给定 $O$,估计模型参数 $\lambda$ | **EM算法(Baum-Welch)** |
**Viterbi算法**的目标:
$$I^* = \arg\max_I P(I \mid O, \lambda)$$
**前向概率** $\alpha_t(i)$:
$$\alpha_t(i) = P(o_1, o_2, ..., o_t, i_t = s_i \mid \lambda)$$
递推公式:
$$\alpha_{t+1}(j) = \left[\sum_{i=1}^{N} \alpha_t(i) \cdot a_{ij}\right] \cdot b_j(o_{t+1})$$

|
|
### 最简示例:自动学习参数
```python
import numpy as np
from hmmlearn import hmm
# 观测序列
obs = np.array([0,1,0,1,0,0,1,1,1,0]).reshape(-1,1)
model = hmm.GaussianHMM(
n_components=2, covariance_type="full", n_iter=100
)
# model.startprob_ = np.array([0.6, 0.4]) # 初始状态概率
# model.transmat_ = np.array([[0.7,0.3],[0.4,0.6]]) # 状态转移概率矩阵
model.emissionprob_ = np.array([[0.8,0.2],[0.3,0.7]]) # 观测概率矩阵
# 使用观测序列训练
model.fit(obs)
# 预测隐藏状态序列
hidden_states = model.predict(X=obs)
# array([0, 1, 0, 1, 0, 0, 1, 1, 1, 0])
```
|
|
### 手工指定初始参数
`init_params` 默认为 `stmc`,可以包含:
- `s`:startprob(初始概率)
- `t`:transmat(转移矩阵)
- `m`:means(均值)
- `c`:covars(协方差)
去掉 `st`,然后手工指定初始状态概率和状态转移概率矩阵:
```python
import numpy as np
from hmmlearn import hmm
# 观测序列
obs = np.array([0,1,0,1,0,0,1,1,1,0]).reshape(-1,1)
model = hmm.GaussianHMM(
n_components=2, covariance_type="full",
n_iter=100, init_params='mc'
)
model.startprob_ = np.array([0.6, 0.4]) # 初始状态概率 π
model.transmat_ = np.array([[0.7,0.3],[0.4,0.6]]) # 状态转移矩阵 A
model.emissionprob_ = np.array([[0.8,0.2],[0.3,0.7]]) # 观测概率矩阵 B
# 使用观测序列训练
model.fit(obs)
# 预测隐藏状态序列
hidden_states = model.predict(X=obs)
# array([1, 0, 1, 0, 1, 1, 0, 0, 0, 1])
```
|
CRF 条件随机场
|
### 一句话理解CRF
CRF就像一个"填空高手":给你一句话,其中每个词的标签被擦掉了,
CRF会根据上下文,给每个词填上最合适的标签。
它不是孤立地看每个词,而是考虑整个句子的前后关系来做出判断。
### 生活中的例子
比如一段文字:"北京是中国的首都"
CRF在做命名实体识别时:
- 看到"北京"→地名
- 看到"是"→普通词
- 看到"中国"→地名
- 看到"的"→普通词
- 看到"首都"→普通词
CRF不仅看当前词本身,还会看前后词的关系。
比如"中国"后面跟着"的",这帮助确认"中国"是一个地名而非普通名词。
### CRF与HMM的对比
| 对比项 | HMM | CRF |
|--------|-----|-----|
| 模型类型 | 生成模型 | 判别模型 |
| 建模对象 | 联合概率 $P(O,I)$ | 条件概率 $P(Y \mid X)$ |
| 依赖关系 | 只考虑前一个状态 | 考虑整个序列的上下文 |
| 特征设计 | 自动(概率分布) | 需要手动设计特征函数 |
```
pip install sklearn-crfsuite
```
### CRF对数据集的要求
- python 列表
- 元素为字符串
- 训练集与标签,元素个数要对上
```
[["准备","吃饭"]] -- ["走起","
|
|
### 条件随机场CRF模型
条件随机场(CRF)是一种用于建模**输入序列与输出序列**之间的依赖关系的**统计模型**。
CRF广泛应用于各种自然语言处理任务,如词性标注、命名实体识别和语义角色标注等。
CRF的主要优点是能够明确地建模观测数据与标签之间的依赖关系,
同时考虑整个序列的上下文信息。
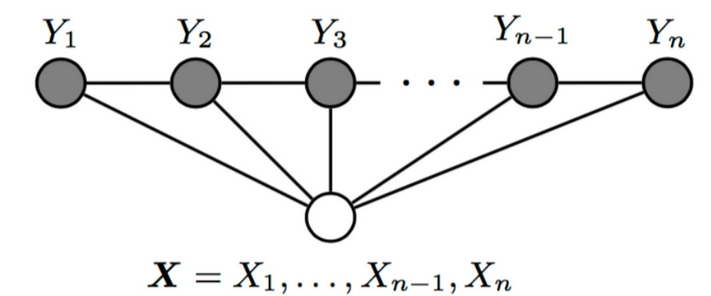 ### CRF的数学公式
**条件概率定义**:
给定输入序列 $x = (x_1, x_2, ..., x_n)$,输出标签序列 $y = (y_1, y_2, ..., y_n)$ 的条件概率为:
$$P(y \mid x) = \frac{1}{Z(x)} \exp\left(\sum_{i,k} \lambda_k t_k(y_{i-1}, y_i, x, i) + \sum_{i,l} \mu_l s_l(y_i, x, i)\right)$$
其中:
- $t_k(y_{i-1}, y_i, x, i)$ 是**转移特征函数**,描述标签之间的转移关系
- $s_l(y_i, x, i)$ 是**状态特征函数**,描述观测值与标签的关系
- $\lambda_k$ 和 $\mu_l$ 是对应的权重参数
- $Z(x)$ 是**归一化因子**(配分函数):
$$Z(x) = \sum_{y} \exp\left(\sum_{i,k} \lambda_k t_k(y_{i-1}, y_i, x, i) + \sum_{i,l} \mu_l s_l(y_i, x, i)\right)$$
**简化形式**:
将转移特征和状态特征统一为 $f_j(y_{i-1}, y_i, x, i)$,权重为 $w_j$:
$$P(y \mid x) = \frac{1}{Z(x)} \exp\left(\sum_{j=1}^{M} w_j F_j(y, x)\right)$$
其中全局特征函数:
$$F_j(y, x) = \sum_{i=1}^{n} f_j(y_{i-1}, y_i, x, i)$$
### CRF的优缺点
**优点**:
1. 模型表现力强:CRF能够对标记之间的依赖关系建模,能够处理更加复杂的序列标注任务
2. 预测准确率高:CRF对于模型训练和预测都采用了统计学习的方法,预测准确率相对比较高
3. 可解释性强:CRF的特征函数定义比较直观,可以帮助理解模型的预测过程
**缺点**:
1. 训练速度比较慢:CRF需要对整个训练集进行参数估计,时间复杂度较高
2. 特征选择比较困难:CRF的性能比较依赖于特征函数的选择和设计,需要手动设计特征函数
3. 对于没有显式标记的数据来说准确率会比较低
### CRF的数学公式
**条件概率定义**:
给定输入序列 $x = (x_1, x_2, ..., x_n)$,输出标签序列 $y = (y_1, y_2, ..., y_n)$ 的条件概率为:
$$P(y \mid x) = \frac{1}{Z(x)} \exp\left(\sum_{i,k} \lambda_k t_k(y_{i-1}, y_i, x, i) + \sum_{i,l} \mu_l s_l(y_i, x, i)\right)$$
其中:
- $t_k(y_{i-1}, y_i, x, i)$ 是**转移特征函数**,描述标签之间的转移关系
- $s_l(y_i, x, i)$ 是**状态特征函数**,描述观测值与标签的关系
- $\lambda_k$ 和 $\mu_l$ 是对应的权重参数
- $Z(x)$ 是**归一化因子**(配分函数):
$$Z(x) = \sum_{y} \exp\left(\sum_{i,k} \lambda_k t_k(y_{i-1}, y_i, x, i) + \sum_{i,l} \mu_l s_l(y_i, x, i)\right)$$
**简化形式**:
将转移特征和状态特征统一为 $f_j(y_{i-1}, y_i, x, i)$,权重为 $w_j$:
$$P(y \mid x) = \frac{1}{Z(x)} \exp\left(\sum_{j=1}^{M} w_j F_j(y, x)\right)$$
其中全局特征函数:
$$F_j(y, x) = \sum_{i=1}^{n} f_j(y_{i-1}, y_i, x, i)$$
### CRF的优缺点
**优点**:
1. 模型表现力强:CRF能够对标记之间的依赖关系建模,能够处理更加复杂的序列标注任务
2. 预测准确率高:CRF对于模型训练和预测都采用了统计学习的方法,预测准确率相对比较高
3. 可解释性强:CRF的特征函数定义比较直观,可以帮助理解模型的预测过程
**缺点**:
1. 训练速度比较慢:CRF需要对整个训练集进行参数估计,时间复杂度较高
2. 特征选择比较困难:CRF的性能比较依赖于特征函数的选择和设计,需要手动设计特征函数
3. 对于没有显式标记的数据来说准确率会比较低
|
|
### 对答示例
```python
X=[["你","几点","上班"],["你","几点","下班"],["你","开心","吗"]]
y=[["八点","半","
|
|
### 一元二次方程公式预测 $f(x) = x^2 + 2x + 1$
```python
X = [
[1, 1, 0, 2, 0, 0],
[0, 1, 1, 0, 4, 0],
[0, 0, 1, 1, 0, 8],
[0, 3, 0, 0, 1, 1],
]
X_train = []
y_train = []
for word_index in X:
X_train.append([str(x) for x in word_index])
y_train.append([str(x*x + 2*x + 1) for x in word_index])
```
```python
from sklearn_crfsuite import CRF
import numpy as np
crf = CRF(
algorithm='lbfgs', c1=0.1, c2=0.1,
max_iterations=100, all_possible_transitions=True
)
crf.fit(X_train, y_train)
y_pred = crf.predict(X_train)
print(np.array(y_pred))
```
输出:
```
[['4' '4' '1' '9' '1' '1']
['1' '4' '4' '1' '25' '1']
['1' '1' '4' '4' '1' '81']
['1' '16' '1' '1' '4' '4']]
```
与 $y_{train}$ 完全一致!
### 为什么公式会预测的这么准?
因为公式 $f(x) = x^2 + 2x + 1 = (x+1)^2$ 完全是**一对一映射**:
$$P(y \mid x) = 1 \quad \text{当} \quad y = f(x)$$
从概率的角度讲:
- $P(y=4 \mid x=1) = 100\%$
- $P(y=1 \mid x=0) = 100\%$
- ...
不重不漏,相互独立,准的不能再准了。
> 只要对于 $x$ 有唯一的 $y$,别说一元二次方程了,不管公式有多复杂,都100%预测正确。
|
PCA 主成分分析
|
### 一句话理解PCA
想象你要描述一个人,信息很多:身高、体重、年龄、性别、学历、收入、爱好...
但如果只允许你说3个最重要的特征,你会选什么?
PCA就是帮你自动找出"最重要的几个特征"的工具。
它把很多维度的数据压缩成少数几个维度,同时尽量保留最重要的信息。
### 生活中的例子
你去相亲,对方的信息有几十项:
身高、体重、年龄、学历、收入、是否有房、是否有车、爱好、性格...
你不可能一项一项看,你主要看的是:**外貌、经济条件、性格** 这三个维度。
这三个维度就是"主成分"——它们涵盖了大部分信息。
PCA做的事情就是:从几十个维度中,找出最能代表数据的几个主成分。
### PCA适合什么场景
主成分提取,从大量信息中提取部分主要信息。
适用于原矩阵是稀疏矩阵,特征多且有很多不重要的。
如果特征少或每个特征都很重要,就不适用用PCA。
|
|
### PCA的核心原理
主成分分析(PCA,Principal Component Analysis)
使用SVD(奇异值分解)提取主要信息。
适用于稀疏矩阵,就是存在大量0数据的矩阵。
从这样的矩阵中提取主要信息。
如果一个矩阵是稠密的,全是主要信息,那么就不适合使用PCA。
### PCA的数学推导
**目标**:找到一组正交基,使得数据在这组基上的投影方差最大。
**步骤一:数据中心化**
$$X_{centered} = X - \bar{X}$$
其中 $\bar{X}$ 是每个特征的均值。
**步骤二:协方差矩阵**
$$C = \frac{1}{n-1} X_{centered}^T X_{centered}$$
协方差矩阵 $C$ 是一个 $p \times p$ 的对称矩阵($p$ 为特征数)。
**步骤三:特征值分解**
对协方差矩阵做特征值分解:
$$C v_i = \lambda_i v_i$$
其中 $\lambda_1 \geq \lambda_2 \geq ... \geq \lambda_p \geq 0$ 是特征值,
$v_i$ 是对应的特征向量(主成分方向)。
**步骤四:降维投影**
取前 $k$ 个最大的特征值对应的特征向量 $V_k = [v_1, v_2, ..., v_k]$,降维结果为:
$$X_{reduced} = X_{centered} \cdot V_k$$
### SVD与PCA的关系
PCA也可以通过SVD直接实现,无需显式计算协方差矩阵:
$$X = U \Sigma V^T$$
其中:
- $U$:左奇异矩阵,维度 $m \times m$
- $\Sigma$:奇异值对角矩阵,奇异值 $\sigma_1 \geq \sigma_2 \geq ... \geq 0$
- $V^T$:右奇异矩阵,维度 $p \times p$
降维结果:
$$X_{reduced} = X \cdot V_k = U \Sigma V^T \cdot V_k$$
奇异值与特征值的关系:$\lambda_i = \frac{\sigma_i^2}{n-1}$
**方差解释率**:第 $i$ 个主成分解释的方差比例为:
$$r_i = \frac{\lambda_i}{\sum_{j=1}^{p} \lambda_j} = \frac{\sigma_i^2}{\sum_{j=1}^{p} \sigma_j^2}$$
前 $k$ 个主成分的累计方差解释率:
$$R_k = \frac{\sum_{i=1}^{k} \lambda_i}{\sum_{j=1}^{p} \lambda_j}$$
### 主成分是无监督的
比如人是复杂的,但要是去相亲(即转化为有监督,标签是相亲满意度),
主成分可能是:身材、颜值、收入、资产、地位等。
但要是去面试一个AI算法工程师(标签是面试是否通过),
主成分可能是:工作年限、行业、资历、年龄、期望薪水等。
而PCA不看标签。它以数据本身的信息为前提,提取其中的主要信息。
比如,你是一个面试官,虽然面试者提供的信息很多,
但你主要看 **工作年限、行业、资历、年龄、期望薪水** 这五个就够了。
|
|
### 降维前后对比
使用同一算法(KNN),数据降维前与降维后进行对比。
```python
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
# 加载数据集
X, y = load_breast_cancer(return_X_y=True)
# 切分数据集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=73
)
```
**降维前**:原始30维特征
```python
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X=X_train, y=y_train)
knn.score(X=X_test, y=y_test) # 0.9035
```
**PCA降维后**:降至2维
```python
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# 数据预处理
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 使用PCA进行降维
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
```
```python
X_train, X_test, y_train, y_test = train_test_split(
X_pca, y, test_size=0.2, random_state=73
)
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X=X_train, y=y_train)
knn.score(X=X_test, y=y_test) # 0.9123
```
> 从30维降到2维,准确率从 0.9035 提升到 0.9123!
> 说明PCA有效去除了冗余信息。
|
|
### 自定义PCA实现
```python
# 加载数据集
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=73
)
```
```python
class MyPCA(object):
"""自定义PCA"""
def __init__(self, n_components=None):
"""挂载超参数"""
self.n_components = n_components
def fit(self, X):
"""训练过程:SVD分解,获取转换矩阵"""
X = np.array(X)
# SVD分解:X = U @ Σ @ V^T
U, S, VT = np.linalg.svd(a=X, full_matrices=False)
# 取前k个主成分对应的特征向量
self.V = VT[:self.n_components, :].T
def transform(self, X):
"""降维转换:X_reduced = X @ V_k"""
X = np.array(X)
return X @ self.V
```
```python
my_pca = MyPCA(n_components=3)
my_pca.fit(X=X_train)
X_train1 = my_pca.transform(X=X_train)
print(X_train.shape, X_train1.shape) # (455, 30) (455, 3)
X_test1 = my_pca.transform(X=X_test)
print(X_test.shape, X_test1.shape) # (114, 30) (114, 3)
knn1 = KNeighborsClassifier(n_neighbors=3)
knn1.fit(X=X_train1, y=y_train)
knn1.score(X=X_test1, y=y_test) # 0.9123
```
### PCA是无监督学习
PCA是无监督的,即降维这个操作不需要标签。
但PCA仍然是需要学习、需要训练的。
由于训练集已经包含了所有的数据规律,
那么在训练集上提取主成份,还是在全体数据集上提取主成分,
其区别应该不大,这两种操作都可以。
### 降维的数学过程详解
SVD分解:
$$X = U \Sigma V^T$$
`full_matrices=False` 指修剪矩阵,使矩阵形状与 `n_components` 相符。
$S$(奇异值)就是主成分,其元素由大到小排列:
$\sigma_1 \geq \sigma_2 \geq ... \geq \sigma_k$
最主要的特征放在前面,越往后信息越不重要。
取前 $k$ 个主成分:
$$V_k = V^T[:k, :]^T \quad \text{(形状:} p \times k \text{)}$$
降维操作(矩阵乘法):
$$X_{reduced} = X \cdot V_k$$
$$\underbrace{[m \times p]}_{X} \cdot \underbrace{[p \times k]}_{V_k} = \underbrace{[m \times k]}_{X_{reduced}}$$
即提取前 $k$ 个主成分,就能得到 $k$ 维数据。
|