线性回归
|
### 什么是线性回归
线性回归(Linear Regression)是一种用于**预测连续值**的统计方法。其基本思想是:通过寻找自变量(特征)和因变量(目标)之间的最佳线性关系,建立数学模型来预测新数据。
### 数学模型
线性回归假设目标变量 $y$ 与特征 $x_1, x_2, ..., x_n$ 之间存在线性关系:
$$y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + ... + \beta_n x_n + \epsilon$$
其中:
- $\beta_0$ 是**截距项**(常数)
- $\beta_1, \beta_2, ..., \beta_n$ 是**回归系数**(权重),表示每个特征对目标的贡献
- $\epsilon$ 是**误差项**,表示模型无法解释的部分
### 最小二乘法
为了找到最佳系数,线性回归采用**最小二乘法**(OLS),目标是最小化预测值与实际值的**残差平方和**:
$$\hat{w} = \arg\min_w \frac{1}{2n}\|y - Xw\|_2^2$$
解析解(闭式解):$\hat{w} = (X^TX)^{-1}X^Ty$
> **"回归"一词的来源**:高尔顿(Francis Galton)在研究遗传学时发现,子女的身高会趋向于人群平均值,即"回归平均"的现象。后来统计学家将这一概念用于描述变量间的趋势关系。
### 评估指标
| 指标 | 公式 | 含义 |
|------|------|------|
| **R²** | $1 - \frac{\sum(y_i - \hat{y}_i)^2}{\sum(y_i - \bar{y})^2}$ | 决定系数,越接近1越好 |
| **MAE** | $\frac{1}{n}\sum\|y_i - \hat{y}_i\|$ | 平均绝对误差,越小越好 |
| **MSE** | $\frac{1}{n}\sum(y_i - \hat{y}_i)^2$ | 均方误差,越小越好 |
|
|
### sklearn 线性回归实战:自行车租赁预测
```python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, mean_squared_error
# 读取数据
dataset = pd.read_csv('bike-day.csv')
dataset = dataset.drop(['casual', 'registered'], axis=1)
# 去掉无关特征
data = dataset.drop(['instant', 'dteday'], axis=1)
# 划分特征和标签
features = ['season', 'yr', 'mnth', 'holiday', 'weekday',
'workingday', 'weathersit', 'temp', 'atemp', 'hum', 'windspeed']
X = data[features]
y = data['cnt']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
```
```python
# 训练模型
lr = LinearRegression()
lr.fit(X=X_train, y=y_train)
# 评估
print(f'R² 分数: {lr.score(X_test, y_test):.4f}')
# 预测
y_pred = lr.predict(X_test)
print(f'MAE: {mean_absolute_error(y_test, y_pred):.2f}')
print(f'MSE: {mean_squared_error(y_test, y_pred):.2f}')
```
**基线结果**:R² = 0.8002, MAE = 642.87, MSE = 777068.41
### 预测值 vs 真实值可视化
```python
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
plt.figure(figsize=(16, 6))
plt.plot(y_test.values, marker=".", label="实际值", alpha=0.7)
plt.plot(y_pred, marker=".", label="预测值", color="r", alpha=0.7)
plt.legend(loc="best")
plt.title('线性回归预测对比')
plt.show()
```
|
|
### 为什么需要正则化?
普通线性回归容易出现**过拟合**问题,尤其是特征之间存在**多重共线性**时。正则化通过在损失函数中加入**惩罚项**来约束系数大小。
### Ridge 回归(L2 正则化)
在损失函数中加入系数的**平方和**作为惩罚:
$$\hat{w}_{Ridge} = \arg\min_w \left\{ \frac{1}{2n}\|y - Xw\|_2^2 + \frac{\alpha}{2}\|w\|_2^2 \right\}$$
- 解析解:$\hat{w} = (X^TX + \alpha I)^{-1}X^Ty$
- 系数被**缩小**但不会精确为0
- 适合特征间存在共线性的场景
### Lasso 回归(L1 正则化)
在损失函数中加入系数的**绝对值之和**作为惩罚:
$$\hat{w}_{Lasso} = \arg\min_w \left\{ \frac{1}{2n}\|y - Xw\|_2^2 + \alpha\|w\|_1 \right\}$$
- 需要**坐标下降法**迭代求解(无解析解)
- 系数可以被**精确压缩为0**,自动进行特征选择
- 适合需要筛选重要特征的场景
### ElasticNet(L1 + L2 混合正则化)
$$\hat{w}_{EN} = \arg\min_w \left\{ \frac{1}{2n}\|y - Xw\|_2^2 + \alpha\left(\frac{1-r}{2}\|w\|_2^2 + r\|w\|_1\right) \right\}$$
- `l1_ratio=0` → 纯 Ridge;`l1_ratio=1` → 纯 Lasso
- 兼具 Ridge 的**稳定性**和 Lasso 的**稀疏性**
### alpha 参数的效果
| alpha 值 | 效果 | 系数变化 |
|----------|------|----------|
| → 0 | 无正则化 | 系数自由取值 |
| 适中 | 适度约束 | 系数被缩小但保留 |
| → ∞ | 极强正则化 | Ridge: 趋近0;Lasso: 精确为0 |
> **直观理解**:$\alpha$ 就像一个"弹簧",拉住所有系数不让它们变得太大。$\alpha$ 越大,弹簧拉力越强。
|
|
### 梯度下降法基本思想
给定一个点,通过迭代地沿着成本函数下降最快的方向更新参数,逐步逼近最优解。
**参数更新公式**:
$$\theta_j := \theta_j - \alpha \cdot \frac{\partial J}{\partial \theta_j}$$
$\alpha$ 为**学习率**,控制每一步走的距离。
### 学习率的选择
| 学习率大小 | 表现 |
|-----------|------|
| 太大 | 发散,损失函数值越来越大 |
| 较大 | 震荡,在山谷两侧来回跳动 |
| 太小 | 收敛缓慢,需要大量迭代 |
| 合适的 $\alpha$ | 平稳下降,最终收敛到最小值 |
### 三种梯度下降变体
| 方法 | 描述 | 更新频率 |
|------|------|---------|
| **批量梯度下降** | 每轮遍历全部训练数据后更新 | 看到所有样本后更新 |
| **随机梯度下降(SGD)** | 每处理一个样本就更新 | 只看一个样本 |
| **小批量梯度下降** | 每次使用一小批样本更新 | 看一小批样本 |
**SGD 特点**:可以**逃离局部最优**,但缺点是**永远定位不出最小值**。
**模拟退火**:逐步降低学习率,开始步长大(快速进展和逃离局部最小),然后越来越小,让算法尽量靠近全局最小值。
### sklearn 线性回归 API
```python
from sklearn.linear_model import LinearRegression
class sklearn.linear_model.LinearRegression(
fit_intercept=True, # 是否计算截距
normalize=False, # 是否标准化
copy_X=True,
n_jobs=None # 并行计算作业数
)
```
### 成本函数与最小二乘法
成本函数(均方误差 MSE):
$$J(\theta_0, \theta_1) = \frac{1}{2m} \sum_{i=1}^{m}(h_\theta(x^{(i)}) - y^{(i)})^2$$
最小二乘法(解析解):$\theta = (X^TX)^{-1}X^Ty$
**局限**:求逆计算复杂度 $O(n^{2.4})$ ~ $O(n^3)$,特征数量大时极其缓慢。
|

### 四种算法核心对比
| 对比维度 | LinearRegression | Ridge (L2) | Lasso (L1) | ElasticNet (L1+L2) |
|---------|-----------------|------------|------------|---------------------|
| **求解方法** | $(X^TX)^{-1}X^Ty$ | $(X^TX+\alpha I)^{-1}X^Ty$ | 坐标下降(软阈值) | 坐标下降(软阈值+L2缩放) |
| **系数特点** | 自由取值 | 缩小但非零 | 可精确为零 | 缩小 + 可精确为零 |
| **特征选择** | 无 | 无 | 有(自动剔除) | 有(更稳定) |
| **多重共线性** | 不稳定 | 稳定 | 不够稳定 | 稳定 |
| **超参数** | 无 | $\alpha$ | $\alpha$ | $\alpha$ + $l1\_ratio$ |
### 手写复现核心公式
**LinearRegression** — 直接矩阵运算:
```python
X_b = np.c_[np.ones(n), X] # 添加截距列
w = np.linalg.inv(X_b.T @ X_b) @ X_b.T @ y
```
**Ridge** — 在对角线上加 $\alpha$:
```python
I_mat = np.eye(X_b.shape[1])
I_mat[0, 0] = 0 # 截距不参与正则化
w = np.linalg.inv(X_b.T @ X_b + alpha * I_mat) @ X_b.T @ y
```
**Lasso** — 坐标下降法 + 软阈值函数:
```python
def soft_threshold(rho, alpha):
if rho > alpha: return rho - alpha
elif rho < -alpha: return rho + alpha
else: return 0.0 # 关键:能将系数精确归零
```
**ElasticNet** — 在 Lasso 基础上加 L2 缩放:
```python
w[j] = soft_threshold(rho, l1_penalty) / (1 + l2_penalty)
```
### 多项式特征(捕获非线性关系)
```python
from sklearn.preprocessing import PolynomialFeatures, StandardScaler
from sklearn.pipeline import Pipeline
# degree=2: 生成平方项和交叉项,11个特征 → 77个特征
model = Pipeline([
("poly", PolynomialFeatures(degree=2, include_bias=False)),
("scaler", StandardScaler()),
("ridge", Ridge(alpha=1))
])
```
|
逻辑回归
|
### 从线性回归到逻辑回归
逻辑回归(Logistic Regression)虽然名字里有"回归",但它是一个**分类算法**,主要用于**二分类**问题。
**核心思路**:在线性回归的输出上套一个 **Sigmoid 函数**,把连续值映射为概率值,再根据概率进行分类。
| 对比 | 线性回归 | 逻辑回归 |
|------|----------|----------|
| **输出** | 连续值 $(-\infty, +\infty)$ | 概率值 $(0, 1)$ |
| **任务** | 预测数值 | 分类决策 |
| **损失函数** | 均方误差 MSE | 交叉熵损失 |
| **一句话** | 预测"多少" | 预测"是不是" |
### 逻辑回归的本质
1. 先用线性函数计算得分:$z = w_1x_1 + w_2x_2 + ... + w_nx_n + b$
2. 用 Sigmoid 函数将得分转为概率:$\hat{p} = \sigma(z)$
3. 根据概率做分类决策:$\hat{y} = 1$ 若 $\hat{p} \geq 0.5$,否则 $\hat{y} = 0$
> **说白了,逻辑回归就相当于单层的神经网络。**
|
|
### Sigmoid 函数
$$\sigma(z) = \frac{1}{1 + e^{-z}}$$
**性质**:
- 输出范围 $(0, 1)$,天然适合表示概率
- 当 $z=0$ 时,$\sigma(z)=0.5$(决策边界)
- 当 $z \to +\infty$ 时,$\sigma(z) \to 1$
- 当 $z \to -\infty$ 时,$\sigma(z) \to 0$
- 导数:$\sigma'(z) = \sigma(z)(1 - \sigma(z))$
### Sigmoid 的 Python 可视化
```python
import numpy as np
import matplotlib.pyplot as plt
z = np.linspace(-8, 8, 200)
sigmoid = 1 / (1 + np.exp(-z))
plt.figure(figsize=(8, 4))
plt.plot(z, sigmoid, linewidth=2)
plt.axhline(y=0.5, color='r', linestyle='--', label='决策边界 p=0.5')
plt.axvline(x=0, color='gray', linestyle='--')
plt.xlabel('z (线性得分)')
plt.ylabel('σ(z) (概率)')
plt.title('Sigmoid 函数')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
```
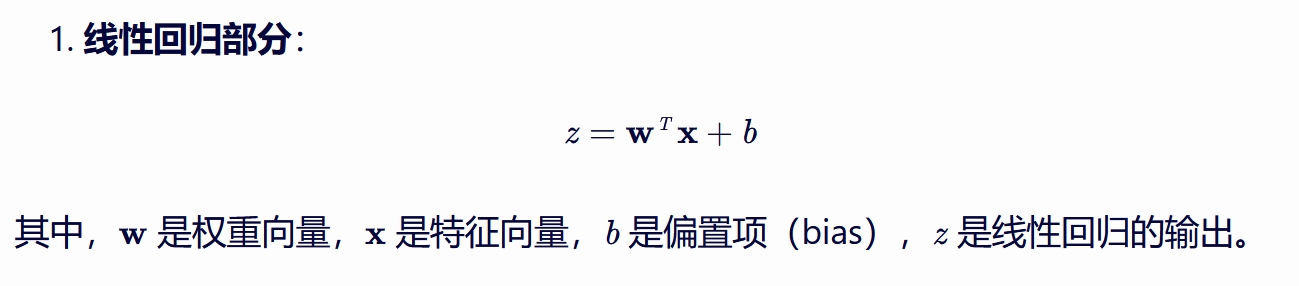
|
|
### 损失函数:交叉熵(Cross-Entropy)
逻辑回归不使用均方误差,而是使用**交叉熵损失**(也称对数损失):
$$L(w) = -\frac{1}{n}\sum_{i=1}^{n}\left[y_i \log(\hat{p}_i) + (1-y_i)\log(1-\hat{p}_i)\right]$$
**为什么不用 MSE?**
- MSE + Sigmoid 会导致损失函数**非凸**,存在多个局部最小值
- 交叉熵 + Sigmoid 保证损失函数是**凸函数**,有唯一全局最优解
### 梯度下降优化
逻辑回归通过**梯度下降**来最小化损失函数,更新权重 $w$ 和偏置 $b$:
$$w_j := w_j - \alpha \frac{\partial L}{\partial w_j}$$
梯度的推导结果非常简洁:
$$\frac{\partial L}{\partial w_j} = \frac{1}{n}\sum_{i=1}^{n}(\hat{p}_i - y_i) x_{ij}$$
> 梯度的形式和线性回归非常相似,区别只是预测值 $\hat{p}$ 是经过 Sigmoid 映射的概率。



|
|
### sklearn 逻辑回归 API 示例
```python
from ai.datasets import load_hotel
from sklearn.linear_model import LogisticRegression
# 加载酒店预订数据集
X_train, y_train, X_test, y_test = load_hotel(return_dict=False, return_Xy=True)
# X_train: (4800, 85) y_train: (4800,)
# X_test: (1200, 85) y_test: (1200,)
# 训练模型
model = LogisticRegression(max_iter=10000)
model.fit(X=X_train, y=y_train)
# 评估
print(f'准确率: {model.score(X=X_test, y=y_test):.4f}')
# 0.6008
# 预测
y_pred = model.predict(X=X_test)
print(y_pred[:10])
# array([0, 0, 1, 1, 0, 1, 1, 0, 0, 0])
```
### 乳腺癌数据集完整示例
```python
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 加载数据
data = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
data.data, data.target, test_size=0.2, random_state=42)
# 训练
lr = LogisticRegression(C=1.0, penalty='l2', solver='liblinear',
max_iter=100, random_state=42)
lr.fit(X_train, y_train)
# 评估
print(f'准确率: {accuracy_score(y_test, lr.predict(X_test)):.4f}')
```
|
手写实现
|
### 手写线性回归(随机梯度下降)
```python
import numpy as np
class Linear_Regression:
def __init__(self):
self._w = None
def fit(self, X, y, lr=0.01, epsilon=0.01, epoch=1000):
"""训练:使用随机梯度下降优化"""
X, y = np.asarray(X, np.float32), np.asarray(y, np.float32)
X = np.hstack((X, np.ones((X.shape[0], 1)))) # 添加常数列
self._w = np.zeros((X.shape[1], 1))
for _ in range(epoch):
# 随机选一个样本计算梯度
idx = np.random.choice(len(X))
x_i = X[idx].reshape(1, -1)
y_i = y[idx]
gradient = x_i.T * (np.dot(x_i, self._w) - y_i)
# 收敛则停止
if (np.abs(self._w - lr * gradient) < epsilon).all():
break
self._w = self._w - lr * gradient
return self._w
def predict(self, x):
x = np.asarray(x, np.float32)
x = x.reshape(x.shape[0], 1)
x = np.hstack((x, np.ones((x.shape[0], 1))))
return np.dot(x, self._w)
def print_results(self):
print(f"参数w: {self._w}")
print(f"回归拟合线: y = {self._w[0][0]}x + {self._w[1][0]}")
```
|
|
### 手写逻辑回归(梯度下降 + Sigmoid)
```python
import numpy as np
class LogisticRegression_Manual:
def __init__(self):
self.w = None
self.b = None
def sigmoid(self, z):
"""Sigmoid 激活函数"""
return 1 / (1 + np.exp(-np.clip(z, -500, 500)))
def fit(self, X, y, lr=0.01, epochs=1000):
"""训练:梯度下降优化交叉熵损失"""
n, d = X.shape
self.w = np.zeros(d)
self.b = 0
for _ in range(epochs):
# 前向传播
z = np.dot(X, self.w) + self.b
p = self.sigmoid(z)
# 计算梯度(交叉熵损失对w和b的偏导)
dw = (1/n) * np.dot(X.T, (p - y))
db = (1/n) * np.sum(p - y)
# 更新参数
self.w -= lr * dw
self.b -= lr * db
def predict_proba(self, X):
"""预测概率"""
return self.sigmoid(np.dot(X, self.w) + self.b)
def predict(self, X, threshold=0.5):
"""预测类别"""
return (self.predict_proba(X) >= threshold).astype(int)
```
**使用方式**:
```python
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
data = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
data.data, data.target, test_size=0.2, random_state=42)
# 标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 训练手写模型
model = LogisticRegression_Manual()
model.fit(X_train, y_train, lr=0.1, epochs=1000)
# 评估
y_pred = model.predict(X_test)
print(f"准确率: {np.mean(y_pred == y_test):.4f}")
```
|
|
### 模型持久化(pickle)
训练好的模型可以保存到文件,下次直接加载使用:
```python
import pickle
# 创建数据并训练
x = np.linspace(0, 100, 10).reshape(10, 1)
rng = np.random.RandomState(4)
noise = rng.randint(-10, 10, size=(10, 1)) * 4
y = 4 * x + 4 + noise
model = Linear_Regression()
model.fit(x, y, lr=0.0001, epsilon=0.001, epoch=20)
# 保存模型
with open('model.pickle', 'wb') as f:
pickle.dump(model, f)
# 加载模型
with open('model.pickle', 'rb') as f:
loaded_model = pickle.load(f)
print(loaded_model.predict([50]))
loaded_model.print_results()
```
> **提示**:sklearn 的模型同样可以用 `pickle` 或 `joblib` 保存,在生产环境中通常使用 `joblib`,因为它对大型 numpy 数组更高效。
|
参数详解
|
### LogisticRegression 参数总览
```python
LogisticRegression(
penalty='l2', # 正则化类型:'l1', 'l2', 'elasticnet', None
C=1.0, # 正则化强度倒数(越小正则化越强)
solver='lbfgs', # 优化算法
max_iter=100, # 最大迭代次数
tol=0.0001, # 收敛阈值
fit_intercept=True, # 是否计算截距
class_weight=None, # 类别权重(处理不平衡数据)
random_state=None, # 随机种子
multi_class='auto', # 多分类策略
warm_start=False, # 是否复用上次训练结果
n_jobs=None, # 并行数(-1为全部核心)
)
```
### 参数分类速查
| 类别 | 参数 | 作用 |
|------|------|------|
| **正则化** | `C`, `penalty` | 控制模型复杂度,防止过拟合 |
| **优化** | `solver`, `tol`, `max_iter` | 控制求解过程 |
| **模型** | `fit_intercept`, `class_weight` | 模型结构设置 |
| **性能** | `n_jobs`, `warm_start` | 计算效率优化 |
### solver 与 penalty 的兼容性
| solver | L1 | L2 | elasticnet | None | 适用场景 |
|--------|:--:|:--:|:----------:|:----:|----------|
| **liblinear** | ✓ | ✓ | ✗ | ✗ | 小数据集 |
| **lbfgs** | ✗ | ✓ | ✗ | ✓ | 默认,通用 |
| **newton-cg** | ✗ | ✓ | ✗ | ✓ | L2正则化 |
| **sag** | ✗ | ✓ | ✗ | ✓ | 大数据集 |
| **saga** | ✓ | ✓ | ✓ | ✓ | 全能型,大数据 |
|
|
### fit_intercept 参数详解
**`fit_intercept=True`(默认)**:模型包含截距项
- 数学表达:$y = w_1x_1 + w_2x_2 + ... + b$
- 适用场景:数据未中心化(均值不为0)时,截距可捕捉全局偏移
- **绝大多数情况下应保持默认 True**
**`fit_intercept=False`**:模型不含截距项
- 数学表达:$y = w_1x_1 + w_2x_2 + ...$(强制过原点)
- 适用场景:数据已标准化(均值为0),或领域知识确定回归线过原点
> 注意:设为 False 时,如果数据实际存在偏移,会导致拟合效果显著下降。
|
|
### solver 参数详解
| solver | 原理 | 优点 | 缺点 |
|--------|------|------|------|
| **liblinear** | 坐标下降法 | 小数据集快,支持L1 | 大数据集慢,不支持多项式 |
| **lbfgs**(默认) | 拟牛顿法 | 收敛快,内存占用低 | 可能陷入局部最优 |
| **newton-cg** | 牛顿法+共轭梯度 | 二阶收敛速度快 | 需要计算Hessian |
| **sag** | 随机平均梯度 | 大数据集快 | 只支持L2 |
| **saga** | SAG改进版 | 支持所有正则化 | 需要更多迭代 |
### 选择建议
```
数据量小(< 10万)且需要L1正则化 → liblinear
数据量一般,通用场景 → lbfgs(默认)
数据量大(> 10万)+ L2正则化 → sag
数据量大 + 需要L1或elasticnet → saga
```
|
|
### 正则化参数详解
#### C(正则化强度的倒数)
$$C = \frac{1}{\alpha}$$
- `C` 越大 → 正则化越弱 → 模型越复杂(可能过拟合)
- `C` 越小 → 正则化越强 → 模型越简单(可能欠拟合)
- 默认 `C=1.0`,调整时通常在 $10^{-2}, 10^{-1}, 1, 10, 10^2$ 上尝试
> 注意:线性回归中正则化强度参数是 $\alpha$(越大越强),逻辑回归中是 $C$(越大越弱),二者互为倒数。
#### penalty(正则化类型)
| penalty | 效果 | 适用场景 |
|---------|------|----------|
| `'l2'`(默认) | 系数缩小但非零 | 特征都有用,防止过拟合 |
| `'l1'` | 系数可归零 | 需要特征选择 |
| `'elasticnet'` | L1+L2混合 | 兼顾稀疏和稳定 |
| `None` | 无正则化 | 数据量充足时 |
#### class_weight(类别权重)
处理**样本不均衡**问题:
```python
# 自动按比例调整权重
model = LogisticRegression(class_weight='balanced')
# 手动指定权重
model = LogisticRegression(class_weight={0: 1, 1: 3}) # 少数类权重更高
```
|
参数优化实验
|
### 实验1:LinearRegression 参数变化
基线模型:R² = 0.8002, MAE = 642.87, MSE = 777068.41
| 模型 | R² | MAE | MSE |
|------|-----|-----|-----|
| LR 默认 (fit_intercept=True) | 0.8002 | 642.87 | 777068 |
| LR 无截距 (fit_intercept=False) | 0.7702 | 660.52 | 894008 |
| LR 正系数 (positive=True) | 0.7506 | 723.59 | 970212 |
**结论**:默认参数效果最好,去掉截距或强制正系数都会降低性能。
> **数据集说明**:自行车租赁预测(bike-day.csv),731 条记录,11 个特征,目标为租赁总数 `cnt`。
|
|
### 实验2:Ridge vs Lasso 不同 alpha
#### Ridge 回归(L2 正则化)
| alpha | R² | MAE | MSE |
|-------|-----|-----|-----|
| 0.001 | 0.8008 | 642.67 | 774750 |
| 0.01 | 0.8048 | 641.38 | 759148 |
| **0.1** | **0.8133** | **638.43** | **726175** |
| **1.0** | **0.8142** | **639.32** | **722789** |
| 10 | 0.7943 | 688.87 | 800201 |
| 100 | 0.5921 | 1049.22 | 1586566 |
| 1000 | 0.2087 | 1451.22 | 3078128 |
#### Lasso 回归(L1 正则化)
| alpha | R² | MAE | MSE | 非零系数 |
|-------|-----|-----|-----|---------|
| 0.001 | 0.8003 | 642.86 | 776892 | 11 |
| 0.01 | 0.8007 | 642.72 | 775321 | 11 |
| 0.1 | 0.8044 | 641.50 | 760773 | 11 |
| **1.0** | **0.8105** | **639.75** | **737001** | **10** |
| 10 | 0.7991 | 659.81 | 781470 | 10 |
| 100 | 0.7134 | 850.99 | 1114665 | 5 |
| 1000 | 0.0481 | 1606.95 | 3702651 | 1 |
**结论**:Ridge(alpha=1) 效果最优(R²=0.8142);alpha 过大性能急剧下降;Lasso 在 alpha=1 时自动剔除了 1 个特征。
|
|
### 实验3:特征标准化 + 多项式特征
#### 标准化 (StandardScaler) + 回归
| 模型 | R² | MAE | MSE |
|------|-----|-----|-----|
| 标准化 + LR | 0.8002 | 642.87 | 777068 |
| 标准化 + Ridge(α=1) | 0.8087 | 640.01 | 743941 |
| 标准化 + Ridge(α=10) | 0.8141 | 638.66 | 722957 |
| 标准化 + Lasso(α=0.1) | 0.8010 | 642.60 | 774077 |
> 标准化对线性回归无影响(因为已标准化),但对正则化模型有提升。
#### 多项式特征 + Ridge(最佳组合)
| 模型 | R² | MAE | MSE |
|------|-----|-----|-----|
| **2阶多项式 + Ridge(α=1)** | **0.8440** | **528.72** | **606652** |
| 2阶多项式 + Ridge(α=10) | 0.8384 | 555.85 | 628766 |
| 2阶多项式 + Ridge(α=100) | 0.8286 | 611.81 | 666772 |
**为什么多项式特征效果最好?**
自行车租赁需求与特征之间存在**非线性关系**:
- 温度:U 型关系(太冷或太热租车都少)
- 季节与假期的交互效应
- 多项式特征能捕获这些交互(11 个特征 → 77 个特征)
### 网格搜索自动寻优
```python
from sklearn.model_selection import GridSearchCV
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
pipe = Pipeline([
('scaler', StandardScaler()),
('ridge', Ridge())
])
param_grid = {'ridge__alpha': [0.01, 0.1, 1, 10, 50, 100, 200, 500]}
grid = GridSearchCV(pipe, param_grid, cv=5, scoring='r2', n_jobs=-1)
grid.fit(X_train, y_train)
print(f"最佳alpha: {grid.best_params_['ridge__alpha']}")
print(f"交叉验证R²: {grid.best_score_:.4f}")
print(f"测试集R²: {grid.score(X_test, y_test):.4f}")
```
|
|
### 全部实验结果汇总(按 R² 降序排列)
| 排名 | 模型 | R² | MAE | MSE |
|:----:|------|-----|-----|-----|
| 1 | **2阶多项式 + Ridge(α=1)** | **0.8440** | **528.72** | **606652** |
| 2 | 2阶多项式 + Ridge(α=10) | 0.8384 | 555.85 | 628766 |
| 3 | 2阶多项式 + Ridge(α=100) | 0.8286 | 611.81 | 666772 |
| 4 | Ridge(α=1) | 0.8142 | 639.32 | 722789 |
| 5 | 标准化 + Ridge(α=10) | 0.8141 | 638.66 | 722957 |
| 6 | Ridge(α=0.1) | 0.8133 | 638.43 | 726175 |
| 7 | Lasso(α=1) | 0.8105 | 639.75 | 737001 |
| 8 | 标准化 + Ridge(α=1) | 0.8087 | 640.01 | 743941 |
| 9 | Ridge(α=0.01) | 0.8048 | 641.38 | 759148 |
| 10 | LR 默认 | 0.8002 | 642.87 | 777068 |
### 最佳模型 vs 基线
| 指标 | 基线 (LR) | 最佳 (多项式+Ridge) | 提升 |
|------|-----------|---------------------|------|
| R² | 0.8002 | 0.8440 | +0.0438 (+5.5%) |
| MAE | 642.87 | 528.72 | -114.15 (-17.8%) |
| MSE | 777068 | 606652 | -170416 (-21.9%) |
### 实践推荐
| 场景 | 推荐配置 | 理由 |
|------|----------|------|
| 快速验证 | LinearRegression | 基准模型 |
| 特征有共线性 | Ridge(α=1~10) | L2 稳定系数 |
| 需要特征筛选 | Lasso(α=0.1~1) | L1 自动选特征 |
| 存在非线性关系 | 多项式(degree=2) + Ridge | 捕获交互 + 防过拟合 |
| 不确定用什么 | GridSearchCV 自动搜索 | 系统化寻优 |
|