|
### 典型行业应用
人工智能已广泛渗透各行各业:
| 应用领域 | 典型技术/产品 | 说明 |
|---------|-------------|------|
| **目标检测** | YOLO 系列 | 实时图像中物体检测与定位 |
| **图像生成** | Stable Diffusion | 神经网络艺术创作、图像风格转换 |
| **知识图谱** | Google Knowledge Graph | 将实体关系结构化,支撑智能问答 |
| **用户画像** | 推荐系统 | 基于行为数据构建用户标签体系 |
| **大语言模型** | ChatGPT、Claude | 对话、代码生成、文本理解 |
| **自动驾驶** | 端到端感知决策 | 视觉+规划一体化驾驶系统 |
| **AIGC** | 多模态生成 | 文本/图像/视频/音频内容生成 |
|
|
### 三个发展阶段
| 阶段 | 时间 | 特征 |
|-----|------|------|
| **正式成形期** | 1980 年代 | 理论框架初步建立 |
| **蓬勃发展期** | 1990–2010 年代 | SVM、随机森林等算法诞生并实用化 |
| **深度学习期** | 2012 年至今 | AlexNet 开启,产业飞速发展 |
### 关键历史节点
- **1956 年**:达特茅斯会议,"人工智能"概念正式诞生
- **1997 年**:IBM 深蓝击败国际象棋世界冠军卡斯帕罗夫
- **2006 年**:Hinton 提出深度学习概念,开启第三次 AI 浪潮
- **2012 年**:AlexNet 在 ImageNet 竞赛中以巨大优势获胜
- **2016 年**:AlphaGo 击败围棋世界冠军李世石
- **2017 年**:Transformer 架构提出,成为现代大模型的基石
- **2022 年**:ChatGPT 发布,生成式 AI 引发全球产业变革
### 发展驱动力
- **算法**:逐层、分布式、并行算法能力大幅提升
- **算力**:GPU、FPGA、TPU 等专用 AI 芯片性能指数级增长
- **数据**:互联网产生海量标注与非标注数据
|
|
### CPU 与 GPU 架构对比
| 特性 | CPU | GPU |
|-----|-----|-----|
| Cache / 本地内存 | 大 | 小 |
| 线程数 | 少 | 多 |
| SIMD 单元 | 少 | 多 |
| 核心数量 | 几个~几十个 | 数千个 |
| 擅长任务 | 逻辑控制、串行运算 | 大规模并行计算 |
### 核心数量详解与作用
#### CPU 核心
- **消费级 CPU**:4 ~ 24 核(如 Intel i7/i9、AMD Ryzen 7/9)
- **服务器级 CPU**:可达 64 ~ 128 核(如 AMD EPYC、Intel Xeon)
- **特点**:每个核心都很"重"——拥有复杂的控制单元、大容量缓存、高主频(3 ~ 5 GHz),擅长处理复杂的逻辑分支和串行任务
- **作用**:负责操作系统调度、应用程序的复杂逻辑控制、数据库事务处理等需要大量判断和跳转的任务
#### GPU 核心
- **消费级 GPU**:数千个 CUDA 核心(如 RTX 4090 有 **16,384** 个)
- **数据中心 GPU**:
- NVIDIA A100:**6,912** 个 CUDA 核心
- NVIDIA H100:**16,896** 个 CUDA 核心
- NVIDIA B200:**20,480** 个 CUDA 核心
- **特点**:每个核心都很"轻"——控制逻辑简单、缓存极小、主频较低(1 ~ 2 GHz),但数量庞大
- **作用**:将同样的计算指令同时施加到海量数据上(SIMD / 单指令多数据流),非常适合深度学习中的矩阵乘法、卷积运算等重复性计算
#### 为什么数量差异如此巨大?
| 维度 | CPU | GPU |
|-----|-----|-----|
| **设计哲学** | 单核性能优先 | 并行吞吐优先 |
| **晶体管分配** | 大量用于分支预测、乱序执行、大缓存 | 大量用于计算单元(ALU) |
| **擅长任务** | 复杂逻辑、不规则计算 | 规则并行计算(矩阵、向量) |
| **比喻** | 一位博学的教授,什么都会 | 一千名小学生,同时做同样的算术题 |
#### 核心、线程与进程的区别
这三个概念处于计算机系统的不同层次,经常混淆:
**进程(Process)**
- 是**操作系统资源分配**的基本单位
- 每个进程拥有独立的内存空间(代码段、数据段、堆栈)
- 进程间相互隔离,一个进程崩溃不会影响其他进程
- 创建和切换开销大(需要切换页表、刷新缓存等)
- 举例:同时运行浏览器、微信、Python 训练脚本,每个都是一个独立进程
**线程(Thread)**
- 是 **CPU 调度**的基本单位
- 线程依附于进程,同一进程内的多个线程共享进程的内存空间
- 线程间切换开销较小(只需切换寄存器和栈)
- 一个进程可以包含多个线程
- 举例:浏览器的渲染线程、JavaScript 执行线程、网络请求线程
**核心(Core)**
- 是 CPU/GPU 芯片上**物理存在**的独立计算单元
- 每个核心可以独立执行一条指令流
- **超线程技术**(Hyper-Threading)可让一个物理核心同时调度两个线程
- 举例:8 核 16 线程 CPU = 8 个物理核心,通过超线程技术可同时调度 16 个线程
**三者的关系**
```
进程(资源容器)
├── 线程 1 → 调度到 核心 1 上执行
├── 线程 2 → 调度到 核心 2 上执行
├── 线程 3 → 调度到 核心 1 上执行(时间片轮转)
└── 线程 4 → 调度到 核心 3 上执行
```
**在 AI 训练中的体现**
| 层级 | 角色 | 实例 |
|-----|------|------|
| **进程** | 整个训练任务 | `python train.py` |
| **线程** | 数据加载、日志记录 | DataLoader 的 `num_workers=4` |
| **核心** | 执行矩阵运算的硬件单元 | GPU 的 6,912 个 CUDA Core |
- **CPU 侧**:PyTorch 的 `DataLoader(num_workers=4)` 启动 4 个子进程来预加载数据
- **GPU 侧**:一个 CUDA Kernel 启动数万个线程,映射到数千个 CUDA Core 上并行执行矩阵运算
### GPU 加速原理
1. **负载转移**:将计算密集部分转移到 GPU,CPU 负责程序逻辑
2. **并行架构**:GPU 拥有数千个更小、更高效的核心
3. **适用场景**:计算密集型、易于并行的程序
### 其他 AI 芯片
| 芯片类型 | 代表产品 | 特点 |
|---------|---------|------|
| **GPU** | NVIDIA A100/H100 | 通用并行计算,生态最成熟 |
| **TPU** | Google TPU v4/v5 | 专为 TensorFlow 优化 |
| **FPGA** | Xilinx/Intel | 可编程硬件,低延迟、低功耗 |
| **ASIC** | 华为昇腾 | 专用集成电路,性能/功耗比最优 |
| **NPU** | 苹果 Neural Engine | 移动端神经网络处理单元 |
|
|
### 机器学习定义
> 从数据中自动分析获得模型,并利用模型对未知数据进行预测。
### 传统编程 vs 机器学习
| 方式 | 流程 | 特点 |
|-----|------|------|
| **传统编程** | 人写规则 → 计算机执行 | 规则需人工持续更新 |
| **机器学习** | 数据 + 算法 → 自动学习模型 → 预测 | 自动适应新情况 |
**垃圾邮件过滤案例**:
- 传统方法:人工标记"4U"为垃圾词,当改成"For U"时失效
- 机器学习方法:自动统计异常频率,自动标记,人为干预极少
### 附加价值
- 检视模型认为的最佳预测因子
- 可能揭示人类未曾意识到的**关联性**或**新趋势**
|
|
### 深度学习定义
> 通过组合低层特征形成更加抽象的高层表示,以发现数据的分布式特征表示。
### 特征学习的层次性(以图像识别为例)
| 网络层 | 学习内容 | 示例 |
|-------|---------|------|
| 第 1 层 | 边缘、颜色、简单纹理 | — |
| 第 2 层 | 更细化的纹理 | 布纹、刻纹、叶纹 |
| 第 3 层 | 复杂图案与光影 | 黄色烛光、高光、萤火 |
| 第 4 层 | 物体部件 | 萌狗的脸、圆柱体 |
| 第 5 层 | 完整物体/场景 | 花、黑眼圈动物、键盘 |
### 网络结构调控
- **增加层数**:通过更抽象的概念识别物体
- **增加结点数**:增加同一层物质的种类/表示能力
### 可视化工具
- **TensorFlow Playground**:http://playground.tensorflow.org
|
|
### 机器学习 vs 深度学习
| | 机器学习 | 深度学习 |
|--|---------|---------|
| 特征处理 | 需人工特征工程 | 自动提取层级特征 |
| 数据需求 | 相对较少 | 通常需要大量数据 |
| 计算资源 | 普通 CPU 即可 | 通常需要 GPU |
| 可解释性 | 较好 | 较差(黑盒问题) |
| 应用场景 | 结构化数据、中小规模问题 | 图像、语音、文本、复杂模式识别 |
### 现代深度学习核心架构
- **CNN**:计算机视觉的基础
- **RNN/LSTM/GRU**:序列建模
- **Transformer**:GPT、BERT 等大语言模型的基础架构
- **生成式模型**:GAN、VAE、Diffusion Model
|
|
### 标准五步流程
```
获取数据 → 数据预处理 → 特征工程 → 模型训练 → 模型评估
```
### 各阶段说明
| 阶段 | 核心任务 | 关键要点 |
|-----|---------|---------|
| **1. 获取数据** | 收集训练所需原始数据 | 数据来源、样本代表性、数据量 |
| **2. 数据预处理** | 清洗、去噪、缺失值处理 | 数据质量决定模型上限 |
| **3. 特征工程** | 提取、选择、构造有价值的特征 | 传统 ML 中最关键的环节 |
| **4. 模型训练** | 选择算法,用训练数据拟合模型 | 损失函数、优化器、迭代训练 |
| **5. 模型评估** | 用测试集评估模型泛化能力 | 评估指标、过拟合/欠拟合判断 |
### 车速估算案例
一辆奥迪汽车车速测试:第一次 1 小时行驶 60km;第二次 1 分钟行驶 1200m(= 72km/h)。估算正常行驶 3 小时能开多远?
> 取稳定速度 66km/h,3 小时约 **198km**。说明模型需要基于数据预测,但数据可能存在噪声。
|
|
### 数据集划分
- **训练集**:用于训练模型
- **验证集**:用于调参和模型选择
- **测试集**:用于最终评估模型泛化能力
常见比例:7:2:1 或采用 K 折交叉验证
### 过拟合与欠拟合
| 概念 | 说明 | 应对策略 |
|-----|------|---------|
| **过拟合** | 训练集表现好,测试集表现差 | 正则化、Dropout、早停、增加数据 |
| **欠拟合** | 训练集和测试集表现都差 | 增加模型复杂度、增加特征 |
### 交叉验证
K 折交叉验证:将数据分成 K 份,轮流作为验证集,取平均评估结果,更可靠。
### 学习路径
```
基础入门 → 经典算法 → 深度学习 → 大模型与生成式 AI → 工程化落地
```
|
|
### 监督学习(Supervised Learning)
> 输入数据由输入特征值和目标值组成,训练数据是**有标签**的。
### 核心概念
| 概念 | 说明 |
|-----|------|
| **样本(Sample)** | 一条数据记录 |
| **标签(Label)** | 样本对应的目标值 |
| **训练集** | 用于训练模型的数据 |
| **测试集** | 用于评估模型的数据 |
### 两大任务
| 任务 | 定义 | 输出类型 | 典型案例 |
|-----|------|---------|---------|
| **回归** | 预测连续的目标值 | 连续实数 | 房价预测、温度预测 |
| **分类** | 推断样本所属类别 | 离散类别 | 肿瘤良恶性判断、图像分类 |
|
|
### 无监督学习(Unsupervised Learning)
> 输入数据**没有被标记**,需要根据样本间的相似性对样本集进行聚类,以发现事物内部结构。
### 主要方法
| 方法类型 | 说明 | 典型算法 |
|---------|------|---------|
| **基于概率密度函数估计** | 找到各类别在特征空间的分布参数 | 高斯混合模型(GMM) |
| **基于相似性度量的聚类** | 依据样本与核心的相似性度量聚类 | K-Means、DBSCAN、层次聚类 |
### 应用场景
- 分析数据的**主分量**(PCA)
- 分析数据集的**特点**与分布
- **降维**可视化
- **异常检测**
- **关联规则学习**(Apriori、FP-Growth)
|
|
### 半监督学习(Semi-supervised Learning)
> 训练集中**一部分数据有标签,其余部分无标签**。
- 标注数据成本高昂,无标注数据容易获取
- 利用大量无标注数据辅助少量有标注数据,提升模型性能
- **典型案例**:循证医学中,已确诊病例较少,大量病例数据未标注
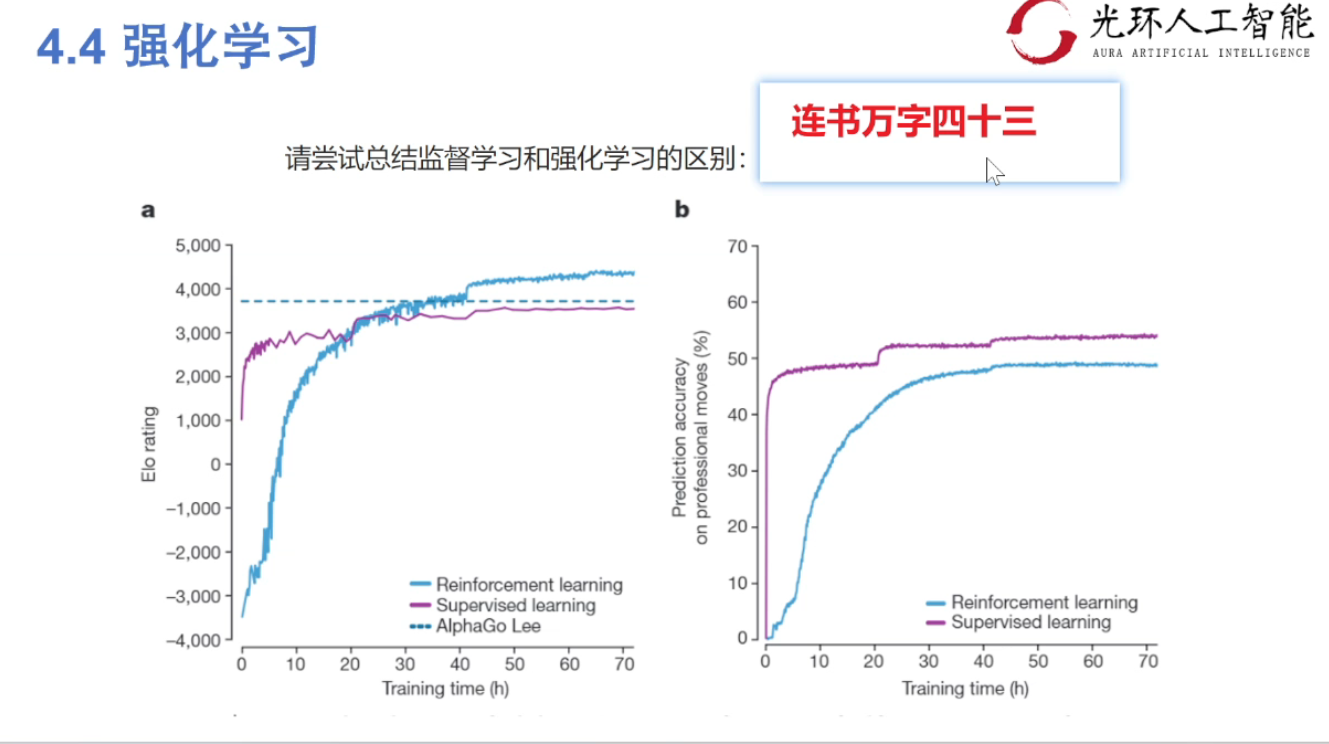
### 强化学习(Reinforcement Learning)
> 实质是 **make decisions** 问题,希望一段时间后获得最多的**累计奖励**。
#### 四要素
| 要素 | 说明 |
|-----|------|
| **Agent(智能体)** | 执行动作的决策者 |
| **环境状态(State)** | 当前环境的情况 |
| **行动(Action)** | Agent 可以采取的操作 |
| **奖励(Reward)** | 环境对行动的反馈信号 |
#### 监督学习 vs 强化学习
| 维度 | 监督学习 | 强化学习 |
|-----|---------|---------|
| 输入 | 有标签的数据 | 决策流程及激励系统 |
| 输出 | 直接反馈 | 延迟奖励 |
| 目的 | 预测结果 | 长期利益最大化 |
| 案例 | 学认字 | 学下棋 |

|