数据处理
|
以账户为节点,交易金额为边权 输入方式1: 交易流水 - 要求流水上有标签, - 自动统计账户的交易金额,并生成图数据 - 最终的标签打上账户上 - 以账户为节点,交易金额为边权 - 节点标签为账户,边标签为金额 输入方式2:文件,账户信息+交易流水 - 要求账户信息有标签, - 交易流水为对应的账户的交易流水 本流程以账户为节点,交易金额为边权,输入的是交易流水 - 重在提取 关系 ```python data_file = "/wks/datasets/ibm_aml/HI-Small_Trans.csv" df = pd.read_csv(data_file) df[:3] ``` 
- 11个字段,第1步就要对应这11个字段 -(机构,账户,金额,币种)* 2 = 8个字段 - 支付方式:现金,ATM,支票,转账,电汇,网银,手机支付,其他 - 标签 - 时间
|
|
文件格式要求 账户文件:账户ID,数字特征,标签 流水文件:from,to,数字特征 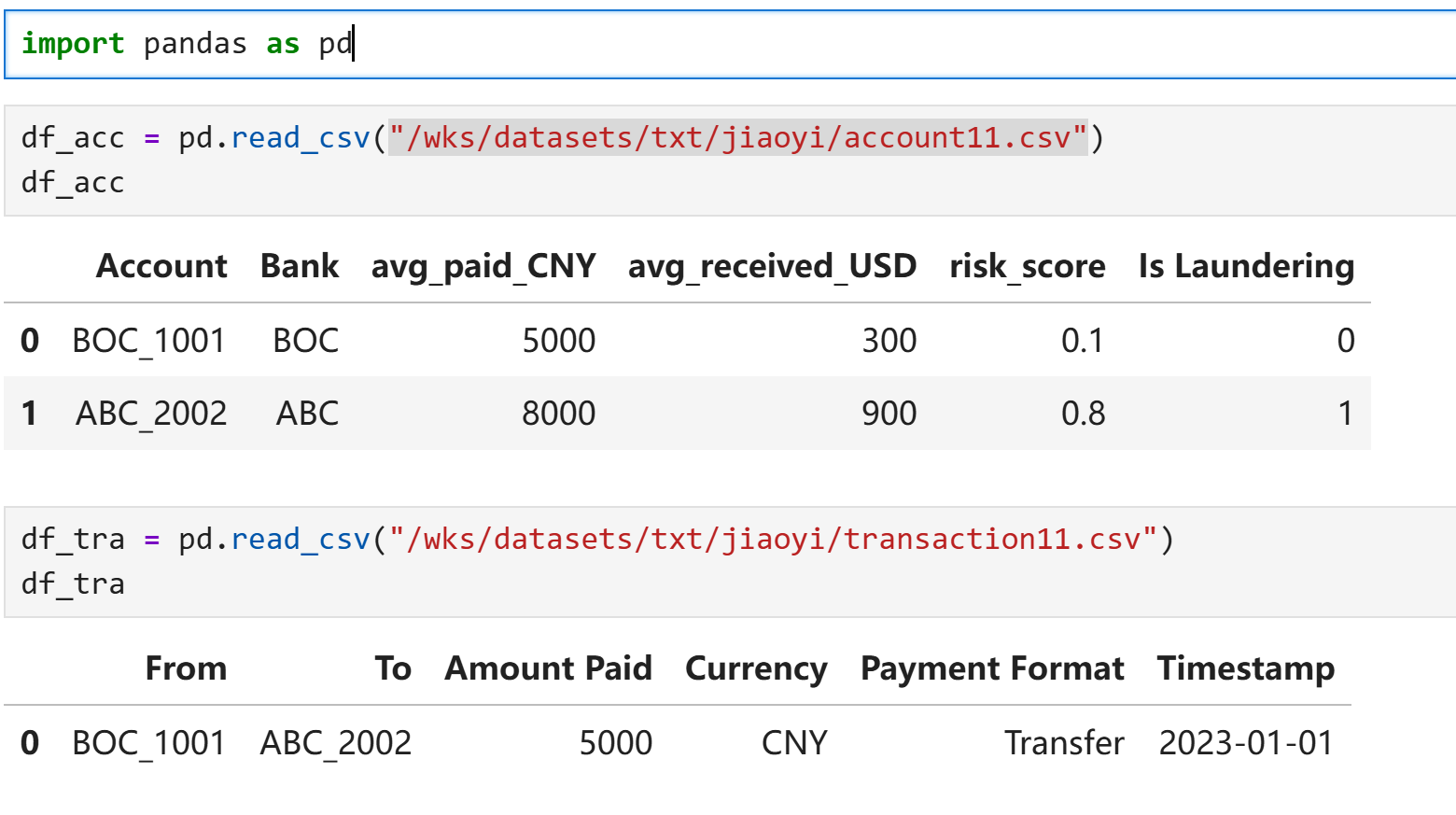
from tpf.data.tu11 import GraphDataBuilder
builder = GraphDataBuilder(
account_id_col='Account',
account_label_col='Is Laundering',
account_feature_cols=['avg_paid_CNY', 'avg_received_USD', 'risk_score'],
trans_from_col='From',
trans_to_col='To',
trains_time_col='Timestamp'
)
acc_file = "/wks/datasets/txt/jiaoyi/account11.csv"
tra_file = "/wks/datasets/txt/jiaoyi/transaction11.csv"
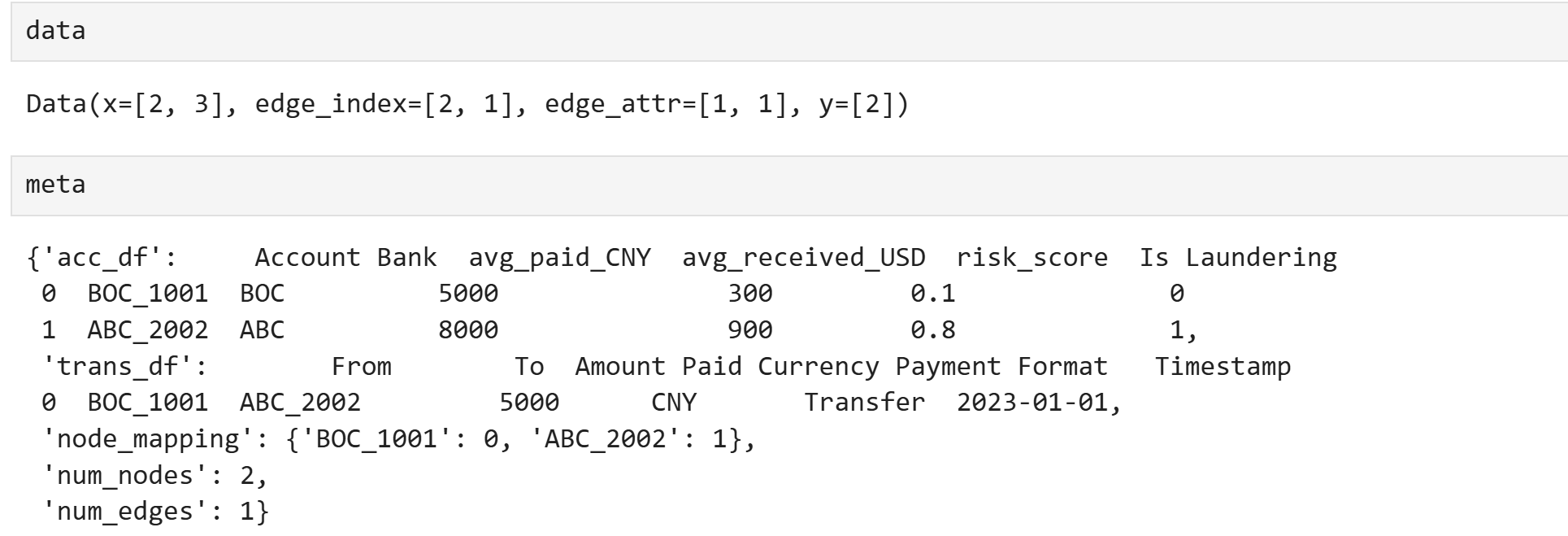
data, meta = builder.load_and_build(
account_file=acc_file,
transaction_file=tra_file,
file_type='csv'
)
print(data)
# 输出类似:
# Data(x=[N,3], edge_index=[2,E], edge_attr=[E,2], y=[N])
Data(x=[2, 3], edge_index=[2, 1], edge_attr=[1, 1], y=[2])
账户特征:排除ID与标签后,只选择数字类型
exclude_cols = {self.account_id_col, self.label_col}
numeric_cols = self.accounts_df.select_dtypes(include=['number']).columns
self.feature_cols = [c for c in numeric_cols if c not in exclude_cols]
因此,在这之前要把所有的特征列先转为数字
交易特征:删除了from,to,原始时间列后,选择了[float, int]
drop_cols = [self.from_col, self.to_col]
if self.time_col:
drop_cols.append(self.time_col)
feature_df = self.transactions_df.drop(columns=drop_cols, errors='ignore')
numeric_df = feature_df.select_dtypes(include=[float, int])
因为,符合要求的只有一列
|
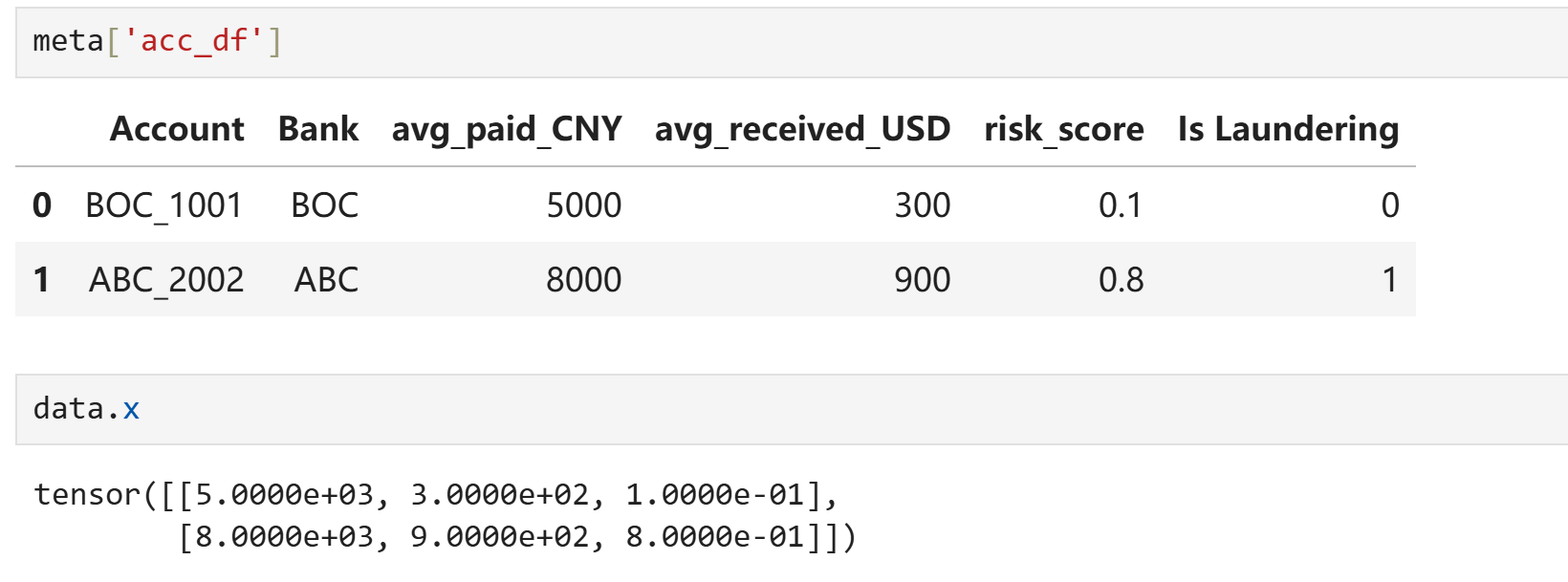
节点的索引与图数据data.x的索引天然一一对应 |
✅ 输出结果 生成了 100 个账户,包含合理分布的风险分、交易习惯等 生成了 1000 笔交易,符合账户间的流动逻辑,含时间、币种、支付方式等 可用于反洗钱建模、图神经网络、异常检测等任务 from tpf.data.make import JiaoYi as jy df_accounts = jy.make_acc11() df_transactions = jy.make_trans11() 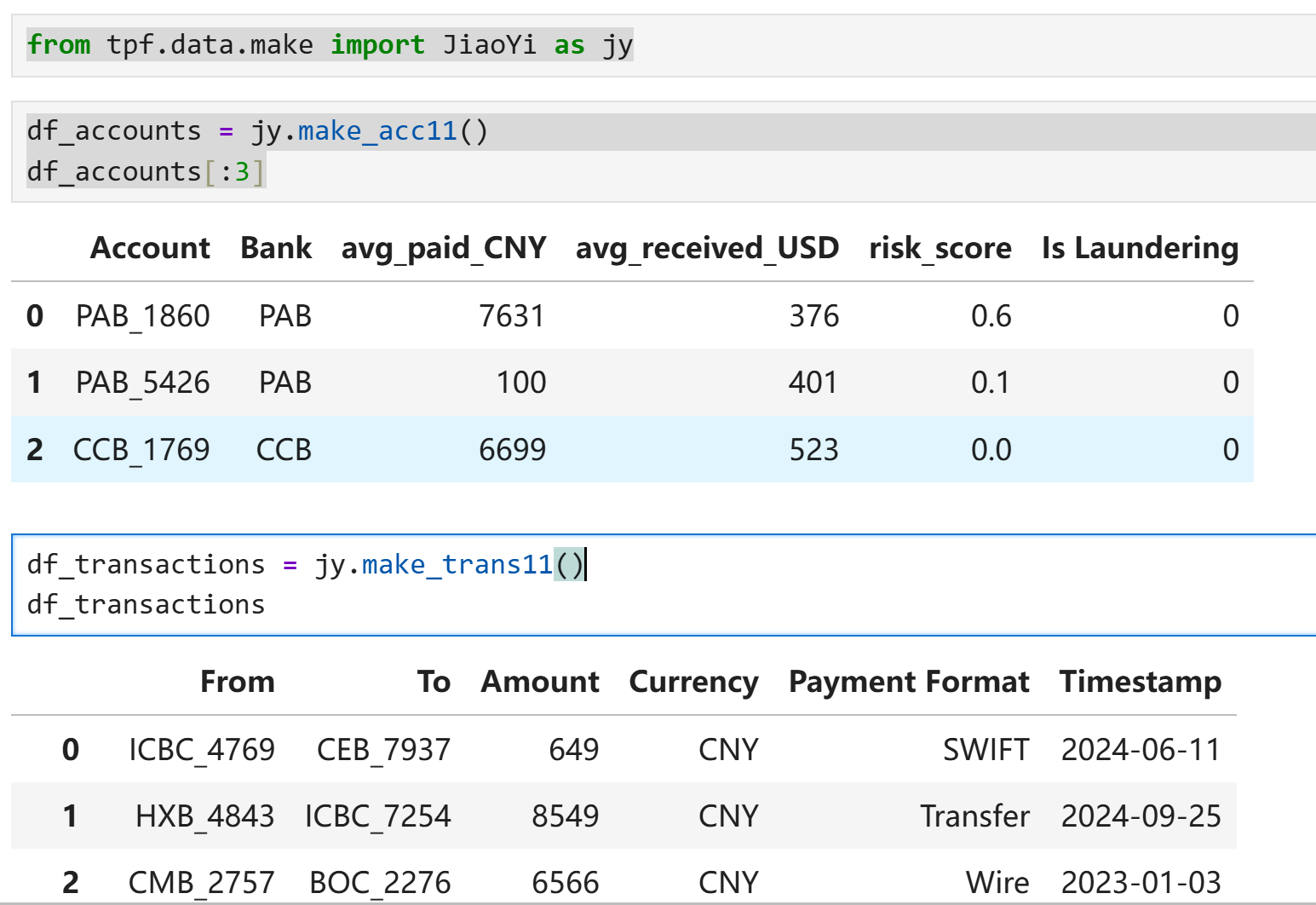
|
除了普通的训练与预测数据区别,还有以下不同点 - 节点与节点之间构成了网络,中间的边是交易,这在训练与预测数据中是一样的 - 模型输入的是节点特征,边关系,边属性,这在训练与预测数据中是一样的 - 训练数据带标签y,而预测没有; 即生成的图数据Data差一个标签,除此外,其他数据都是相同的 |
|
|
|
|
数据预处理示例
|
首先三分:标识列,特征列,标签
from tpf.data.make import JiaoYi as jy
df_accounts = jy.make_acc11()
df_accounts= df_accounts.drop(columns=['Bank'])
df_accounts[:3]
如果有多个标识列,代码会自动将之合并为一个列,名称默认第一列的名称
from tpf.data.deal import DataDealDL
# 配置字段
identity_cols = ['Account']
classify_cols = []
classify_shared_groups = [] # From 和 To 共用编码器
num_cols = ['risk_score', 'avg_paid_CNY', 'avg_received_USD']
num_small=['risk_score'] #存在于该列表中的列不再做Log处理,通常有大量低于1的数值
date_cols = []
bool_cols = []
# 初始化
data_deal = DataDealDL(
identity_cols=identity_cols,
classify_cols=classify_cols,
classify_shared_groups=classify_shared_groups,
num_cols=num_cols,
num_small=num_small,
date_cols=date_cols,
bool_cols=bool_cols,
log10_transform=True,
max_date_str="2035-01-01",
scaler_root="./",
alg_type="lgbmc",
batch_num=100
)
# 训练阶段
df_train_processed = data_deal.fit_transform(df_accounts)
# 推理阶段(新数据)
df_pre_processed = data_deal.transform(df_accounts)
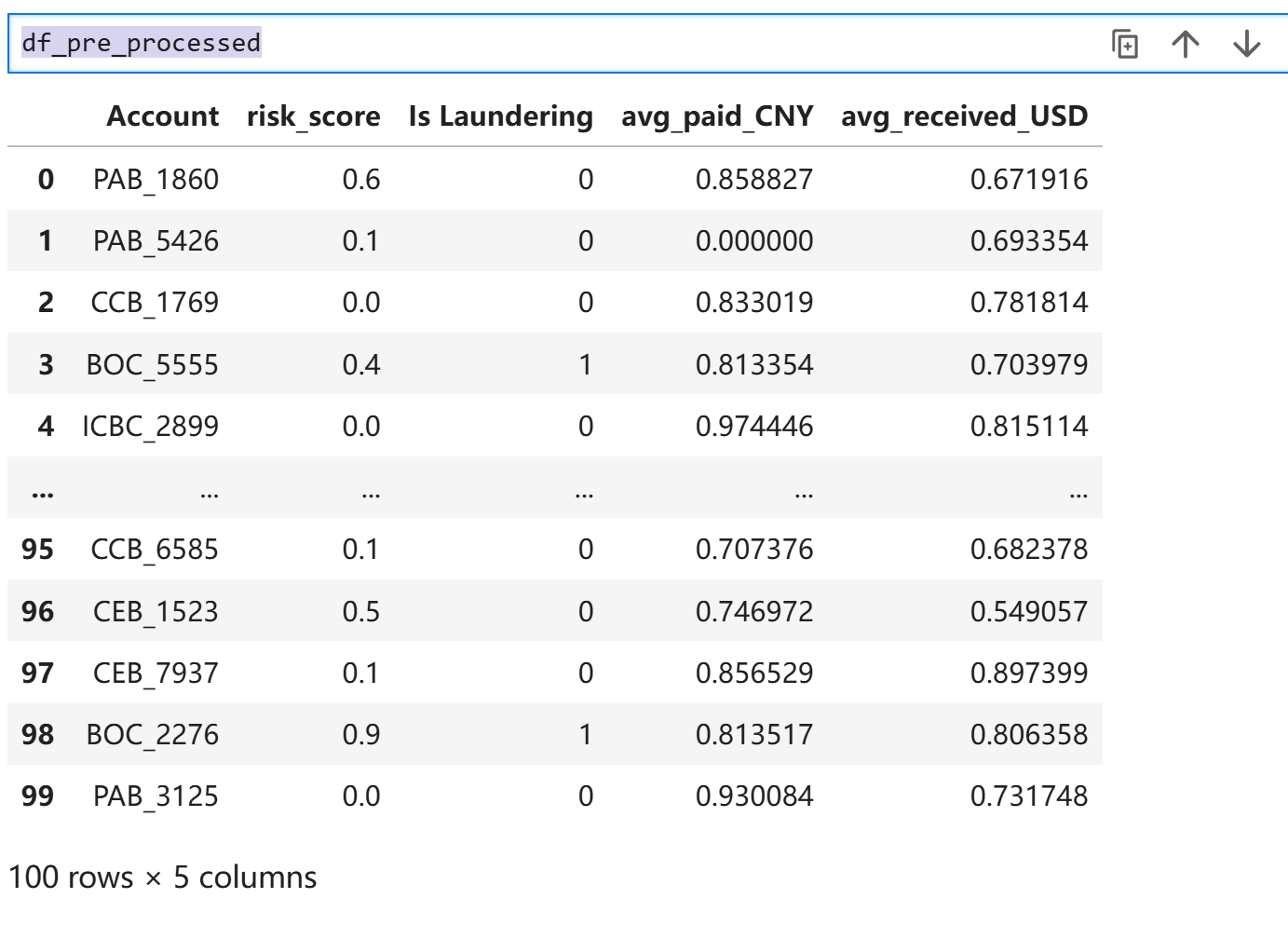
|
from tpf.data.make import JiaoYi as jy
df_transactions = jy.make_trans11()
df_transactions[:3]
from tpf.data.deal import DataDealDL
# 配置字段
identity_cols = ['From','To']
classify_cols = ['Currency','Payment Format']
classify_shared_groups = [[]] # From 和 To 共用编码器
num_cols = ['Amount']
date_cols = ['Timestamp']
bool_cols = []
alg_type="lgbmc"
batch_num=100
# 初始化
data_deal = DataDealDL(
identity_cols=identity_cols,
classify_cols=classify_cols,
classify_shared_groups=classify_shared_groups,
num_cols=num_cols,
num_small=['risk_score'],
date_cols=date_cols,
bool_cols=bool_cols,
scaler_root="./",
alg_type=alg_type,
batch_num=batch_num
)
# 训练阶段
df_train_processed = data_deal.fit_transform(df_transactions)
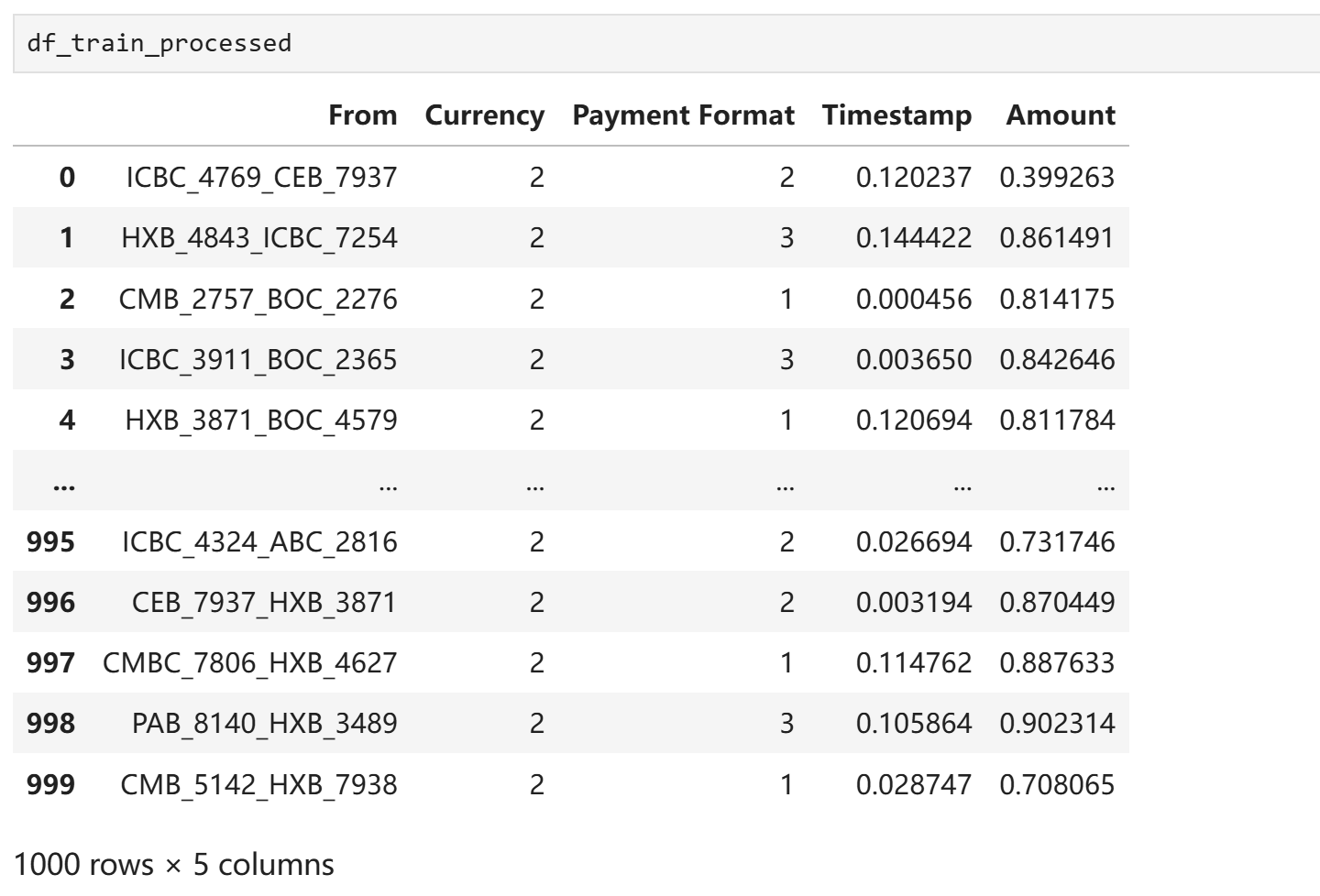
保存模型
from tpf import pkl_load,pkl_save
import os
data_deal_model_path = os.path.join("./",f"{alg_type}_dtmodel_{batch_num}.pkl")
pkl_save(data_deal,file_path=data_deal_model_path)
预测
data_deal = pkl_load(file_path=data_deal_model_path)
# 推理阶段(新数据)
df_pre_processed = data_deal.transform(df_transactions)
df_pre_processed
标识列合并改为以"_._"拼接
aa="ICBC_4324_._ABC_281"
aa=aa.split("_._")
aa
['ICBC_4324', 'ABC_281']
|
|
只输入基础参数,组合而成的参数由pc内部处理传入
pc.col_type.num_type = col_types["num_type"]
pc.col_type.classify_type = col_types["classify_type"]
pc.col_type.identity = str_identity_acc
pc.col_type.date_type = []
pc.col_type.bool_type = []
pc.col_type.classify_type2 = [[]] #一组类别使用同一个字典
#pc.col_type.classify_type_pre = [pc.channel, pc.currency1, pc.currency2,pc.bank11, pc.bank12] #预测时的类别列
pc.alg_type = alg_type
cm.lg(pc.col_type.num_type[:3])
cm.lg(pc.col_type.classify_type[:3])
pc.max_date = '2035-01-01'
pc.drop_cols = []
# 数据预处理
data_deal = DataDealDL( # 初始化
identity_cols=pc.col_type.identity,
classify_cols=pc.col_type.classify_type,
classify_shared_groups=pc.col_type.classify_type_pre,
num_cols=pc.col_type.num_type,
num_small=[],
date_cols=pc.col_type.date_type,
bool_cols=pc.col_type.bool_type,
log10_transform=True,
pc=pc
)
# 训练阶段
df_train_processed = data_deal.fit_transform(df)
cm.lg(f"df_train_processed[:3]:\n{df_train_processed[:3]}")
if not os.path.exists(pc.data_deal_model_path()):
pkl_save(data_deal,file_path=pc.data_deal_model_path())
cm.lg(f"data_deal model saved to {pc.data_deal_model_path()}")
[2025-09-11 17:47:28] data_deal model saved to /ai/data/model/gnn_dtmodel_1418.pkl |
|
|
|
|
参考
神经网络】神经元ReLU、Leaky ReLU、PReLU和RReLU的比较