基础
python -c "import torch; print(torch.__version__)"
>>> 2.6.0
python -c "import torch; print(torch.version.cuda)"
>>> 12.6
pip install pyg_lib torch_scatter torch_sparse torch_cluster torch_spline_conv -f https://data.pyg.org/whl/torch-${TORCH}+${CUDA}.html
where ${TORCH} and ${CUDA} should be replaced by the specific PyTorch and CUDA versions, respectively:
PyTorch 2.7.*: ${TORCH}=2.7.0 and ${CUDA}=cpu|cu118|cu126|cu128
PyTorch 2.6.*: ${TORCH}=2.6.0 and ${CUDA}=cpu|cu118|cu124|cu126
PyTorch 2.5.*: ${TORCH}=2.5.0 and ${CUDA}=cpu|cu118|cu121|cu124
PyTorch 2.4.*: ${TORCH}=2.4.0 and ${CUDA}=cpu|cu118|cu121|cu124
PyTorch 2.3.*: ${TORCH}=2.3.0 and ${CUDA}=cpu|cu118|cu121
PyTorch 2.2.*: ${TORCH}=2.2.0 and ${CUDA}=cpu|cu118|cu121
PyTorch 2.1.*: ${TORCH}=2.1.0 and ${CUDA}=cpu|cu118|cu121
PyTorch 2.0.*: ${TORCH}=2.0.0 and ${CUDA}=cpu|cu117|cu118
PyTorch 1.13.*: ${TORCH}=1.13.0 and ${CUDA}=cpu|cu116|cu117
https://pytorch-geometric.readthedocs.io/en/latest/notes/installation.html
pip install pyg_lib torch_scatter torch_sparse torch_cluster torch_spline_conv -f https://data.pyg.org/whl/torch-2.5.0+cu121.html
pip install torch_geometric
|
torch2.4+大模型版,2025年流行版本,在大模型环境中安装torch-geometric
pip install torch==2.4.0 torchaudio==2.4.0 torchvision==0.19.0 transformers==4.44.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install tokenizers==0.19.1 triton==3.0.0 vllm==0.5.5 vllm-flash-attn==2.6.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install torch-scatter -f https://data.pyg.org/whl/torch-2.4.0+cu124.html
pip install torch-sparse -f https://data.pyg.org/whl/torch-2.4.0+cu124.html
pip install torch-geometric
pip install torch-cluster -f https://data.pyg.org/whl/torch-2.4.0+cu124.html
pip install torch-spline-conv -f https://data.pyg.org/whl/torch-2.4.0+cu124.html
torch2.5 无大模型
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install torch-scatter -f https://data.pyg.org/whl/torch-2.5.1+cu124.html
pip install torch-sparse -f https://data.pyg.org/whl/torch-2.5.1+cu124.html
pip install torch-geometric
pip install torch-cluster -f https://data.pyg.org/whl/torch-2.5.1+cu124.html
pip install torch-spline-conv -f https://data.pyg.org/whl/torch-2.5.1+cu124.html
|
|
|
|
|
|
|
度·出度·入度

在GNN中的意义 消息传递方向: GNN通过聚合邻居信息更新节点表示。在有向图中: 出度高的节点:可能影响更多下游节点(如社交网络中的“意见领袖”)。 入度高的节点:可能被更多节点依赖(如网页排名中的“权威页面”)。 应用场景: 引文网络:论文的入度表示被引用次数(重要性)。 社交网络:用户的出度表示关注他人数量,入度表示粉丝数量。 推荐系统:用户对商品的点击(出度)与商品被点击(入度)。 与无向图的区别 无向图:边无方向性,出入度相等,统称为度(Degree)。 有向图:需区分出入度,可能影响GNN设计(如Directional GNNs)。 实际应用建议 特征工程:将出入度作为节点特征输入模型(如拼接或归一化)。 注意力机制:GAT等模型可通过出入度调整注意力权重。 异构图(Heterogeneous Graph):不同边类型可能有独立的出入度统计。 例如,在PageRank算法中,入度是衡量网页重要性的核心指标; 而在GNN中,出入度可帮助模型理解节点在图中的局部结构角色。
|
geometric 英/ˌdʒiːəˈmetrɪk/ 美/ˌdʒiːəˈmetrɪk/ adj. 几何(学)的;(似)几何图形的 n. 有几何图形的东西 假设有一个有向图的边索引 edge_index
import torch
from torch_geometric.utils import degree
# 有向图的边索引 (2条边: 0→1, 1→2)
edge_index = torch.tensor([[0, 1], [1, 2]], dtype=torch.long)
# 计算入度(目标节点为边索引的第二行)
in_degree = degree(edge_index[1], dtype=torch.long) # 输出: tensor([0, 1, 1])
# 计算出度(源节点为边索引的第一行)
out_degree = degree(edge_index[0], dtype=torch.long) # 输出: tensor([1, 1, 0])
degree只统计节点边的数量 - 输入edge_index[0],结果就是出度 - 输入edge_index[1],结果就是入度 - 输出结果的索引默认为节点的编码,默认所有节点按索引编码
|
区分入度和出度的关键 在有向图中,edge_index 是一个形状为 [2, num_edges] 的张量: edge_index[0]:所有边的源节点(边的起点)。 edge_index[1]:所有边的目标节点(边的终点)。 通过选择 edge_index 的某一行作为输入,degree 函数会统计: 出度(Out-degree):传入 edge_index[0],统计每个节点作为起点的次数。 入度(In-degree):传入 edge_index[1],统计每个节点作为终点的次数。
import torch
from torch_geometric.utils import degree
# 有向图的边索引:两条边 0→1 和 1→2
edge_index = torch.tensor([[0, 1], # 源节点(起点)
[1, 2]], dtype=torch.long) # 目标节点(终点)
# 计算入度:统计每个节点作为目标节点的次数
in_degree = degree(edge_index[1]) # 输入目标节点行
# 输出: tensor([0, 1, 1])
# 解释:
# - 节点0:未被指向 → 入度=0
# - 节点1:被0指向1次 → 入度=1
# - 节点2:被1指向1次 → 入度=1
# 计算出度:统计每个节点作为源节点的次数
out_degree = degree(edge_index[0]) # 输入源节点行
# 输出: tensor([1, 1, 0])
# 解释:
# - 节点0:指向1一次 → 出度=1
# - 节点1:指向2一次 → 出度=1
# - 节点2:无出边 → 出度=0
出度:degree(edge_index[0]) → 统计节点作为起点的次数。 入度:degree(edge_index[1]) → 统计节点作为终点的次数。 本质:通过控制输入的边索引行,决定统计方向。 扩展:归一化出入度 在 GNN 中,常将出入度归一化后作为特征或用于邻域聚合权重。例如: # 归一化入度(用于GCN的度归一化) in_degree_norm = 1.0 / (degree(edge_index[1]) + 1) # 避免除零 Directional Graph Networks https://arxiv.org/abs/2010.02863 |
|
|
|
|
networkx
NetworkX是一个用于创建、操作和研究复杂网络结构、动态和功能的Python库。 它提供了简单易用的接口来构建各种类型的图(如无向图、有向图、加权图等), 并且包含了众多图算法,例如最短路径算法、连通性分析算法、社区发现算法等, 广泛应用于社交网络分析、生物网络、交通网络等多个领域。 pip install networkx 创建图
import networkx as nx
# 创建一个空的无向图
G = nx.Graph()
# 添加节点
G.add_node(1)
G.add_nodes_from([2, 3, 4])
# 添加边
G.add_edge(1, 2)
G.add_edges_from([(1, 3), (2, 4)])
# 查看图的节点和边
print("节点:", G.nodes())
print("边:", G.edges())
节点: [1, 2, 3, 4]
边: [(1, 2), (1, 3), (2, 4)]
有向图
# 创建一个空的有向图
DG = nx.DiGraph()
# 添加节点和边
DG.add_edge(1, 2)
DG.add_edge(2, 3)
DG.add_edge(3 ,1)
# 查看有向图的节点和边
print("节点:", DG.nodes())
print("边:", DG.edges())
节点: [1, 2, 3] 边: [(1, 2), (2, 3), (3, 1)] 扩展
import networkx as nx
# 创建空图
G = nx.Graph() # 无向图
DG = nx.DiGraph() # 有向图
MG = nx.MultiGraph() # 多重无向图
MDG = nx.MultiDiGraph() # 多重有向图
# 添加单个节点
G.add_node(1)
G.add_node("A")
# 添加多个节点
G.add_nodes_from([2, 3, "B", "C"])
# 添加带属性的节点
G.add_node(4, color="red", size=10)
# 添加边
G.add_edge(1, 2)
G.add_edge("A", "B", weight=0.5)
# 添加多条边
G.add_edges_from([(1, 3), (2, "C"), ("A", 3)])
# 添加带属性的边
G.add_edge(3, 4, weight=2.7, color="blue")
可视化
import matplotlib.pyplot as plt
# 简单绘制
nx.draw(G, with_labels=True)
plt.show()
# 更复杂的可视化
pos = nx.spring_layout(G) # 布局算法
nx.draw_networkx_nodes(G, pos, node_size=500)
nx.draw_networkx_edges(G, pos, width=1.0)
nx.draw_networkx_labels(G, pos, font_size=12, font_family="sans-serif")
plt.axis("off")
plt.show()
|
|
添加节点和边的属性
import networkx as nx
# 创建一个空的无向图
G = nx.Graph()
# 添加节点
G.add_node(1)
G.add_nodes_from([2, 3, 4])
# 添加边
G.add_edge(1, 2)
G.add_edges_from([(1, 3), (2, 4)])
# 查看图的节点和边
print("节点:", G.nodes())
print("边:", G.edges())
节点: [1, 2, 3] 边: [(1, 2), (2, 3), (3, 1)] # 给节点添加属性 G.add_node(1, color='red', size=10, id=1) G.nodes[1]['shape'] = 'circle' # 给边添加属性 G.add_edge(1, 2, weight=0.5, capacity=10) G[1][2]['label'] = 'edge1-2'
# 查看节点和边的属性
print("节点1的属性:", G.nodes[1])
print("边(1, 2)的属性:", G[1][2])
节点1的属性: {'color': 'red', 'size': 10, 'id': 1, 'shape': 'circle'}
边(1, 2)的属性: {'weight': 0.5, 'capacity': 10, 'label': 'edge1-2'}
G.nodes() NodeView((1, 2, 3, 4)) 节点1开始添加过了,增加属性时又加一遍,最终只有一个节点1 获取图的属性
# 获取所有节点的属性
for node, attr in G.nodes(data=True):
print(f"节点{node}的属性:{attr}")
节点1的属性:{'color': 'red', 'size': 10, 'id': 1, 'shape': 'circle'}
节点2的属性:{}
节点3的属性:{}
节点4的属性:{}
# 获取所有边的属性
for n1,n2,attr in G.edges(data=True):
print(f"边{n1,n2}的属性:{attr}")
边(1, 2)的属性:{'weight': 0.5, 'capacity': 10, 'label': 'edge1-2'}
边(1, 3)的属性:{}
边(2, 4)的属性:{}
|
import networkx as nx import matplotlib.pyplot as plt G = nx.Graph() G.add_nodes_from([1, 2, 3, 4, 5]) G.add_edges_from([(1, 2),(1, 3),(2, 5), (2, 4)]) nx.draw(G, node_size=50) plt.show() 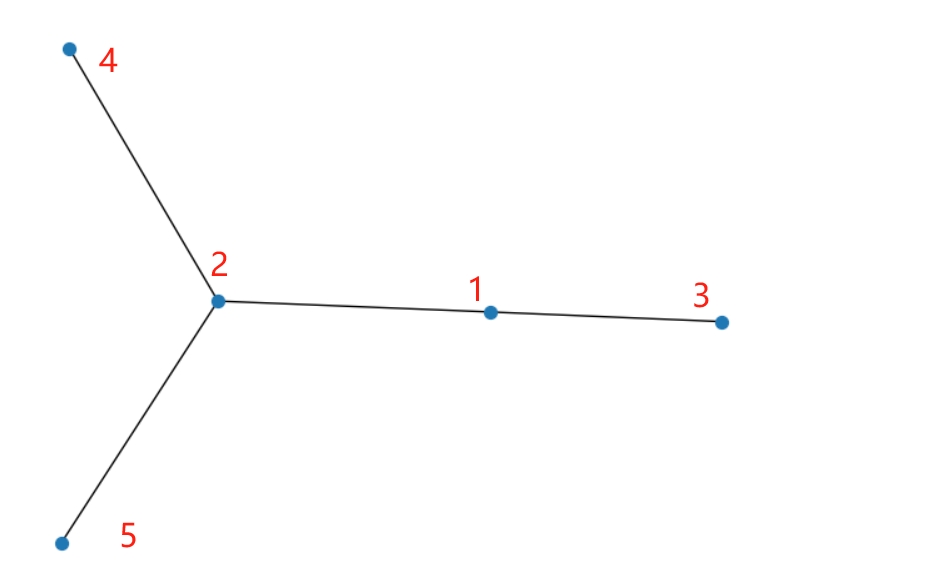
# 给节点添加属性 G.add_node(1, color='red', size=10, id=1) G.nodes[1]['shape'] = 'circle' # 给边添加属性 G.add_edge(1, 2, weight=0.5, capacity=10) G[1][2]['label'] = 'edge1-2' 深度优先搜索(DFS)
# 从节点1开始进行深度优先搜索
dfs_edges = list(nx.dfs_edges(G, source=1))
print("深度优先搜索的边序列:", dfs_edges)
深度优先搜索的边序列: [(1, 2), (2, 5), (2, 4), (1, 3)] 广度优先搜索(BFS)
# 从节点1开始进行广度优先搜索
bfs_edges = list(nx.bfs_edges(G, source=1))
print("广度优先搜索的边序列:", bfs_edges)
广度优先搜索的边序列: [(1, 2), (1, 3), (2, 5), (2, 4)] |
|
最短路径算法
import networkx as nx
import matplotlib.pyplot as plt
G = nx.Graph()
G.add_nodes_from([1, 2, 3, 4, 5])
G.add_edges_from([(1, 2),(1, 3),(2, 5), (2, 4)])
# 计算节点1到节点4的最短路径
shortest_path = nx.shortest_path(G, source=1, target=4)
print("最短路径:", shortest_path)
# 计算最短路径的长度
shortest_path_length = nx.shortest_path_length(G, source=1, target=4)
print("最短路径长度:", shortest_path_length)
最短路径: [1, 2, 4] 最短路径长度: 2 连通性分析
# 判断图是否连通
is_connected = nx.is_connected(G)
print("图是否连通:", is_connected)
# 获取图的连通分量
connected_components = list(nx.connected_components(G))
print("连通分量:", connected_components)
图是否连通: True
连通分量: [{1, 2, 3, 4, 5}]
import networkx as nx
import matplotlib.pyplot as plt
G = nx.Graph()
G.add_nodes_from([1, 2, 3, 4, 5,6,7,8])
G.add_edges_from([(1, 2),(1, 3),(2, 5), (2, 4)])
G.add_edge(7, 8)
# 判断图是否连通
is_connected = nx.is_connected(G)
print("图是否连通:", is_connected)
# 获取图的连通分量
connected_components = list(nx.connected_components(G))
print("连通分量:", connected_components)
图是否连通: False
连通分量: [{1, 2, 3, 4, 5}, {6}, {8, 7}]
社区发现
# 使用Louvain算法进行社区发现
from networkx.algorithms.community import louvain_communities
communities = louvain_communities(G)
print("社区划分:", communities)
社区划分: [{1, 3}, {2, 4, 5}, {6}, {8, 7}]
|
import matplotlib.pyplot as plt # 绘制图 nx.draw(G, with_labels=True, node_color='lightblue', edge_color='gray') plt.show() 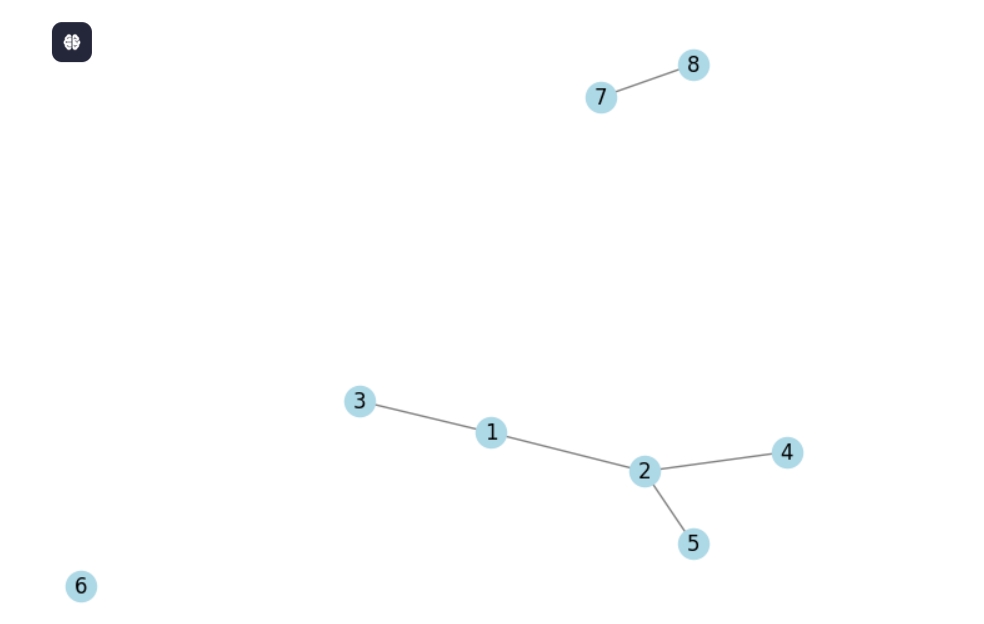
示例2
import networkx as nx
# 创建空图
G = nx.Graph() # 无向图
DG = nx.DiGraph() # 有向图
MG = nx.MultiGraph() # 多重无向图
MDG = nx.MultiDiGraph() # 多重有向图
# 添加单个节点
G.add_node(1)
G.add_node("A")
# 添加多个节点
G.add_nodes_from([2, 3, "B", "C"])
# 添加带属性的节点
G.add_node(4, color="red", size=10)
# 添加边
G.add_edge(1, 2)
G.add_edge("A", "B", weight=0.5)
# 添加多条边
G.add_edges_from([(1, 3), (2, "C"), ("A", 3)])
# 添加带属性的边
G.add_edge(3, 4, weight=2.7, color="blue")
import matplotlib.pyplot as plt
# 简单绘制
nx.draw(G, with_labels=True)
plt.show()

# 更复杂的可视化
pos = nx.spring_layout(G) # 布局算法
nx.draw_networkx_nodes(G, pos, node_size=500)
nx.draw_networkx_edges(G, pos, width=1.0)
nx.draw_networkx_labels(G, pos, font_size=12, font_family="sans-serif")
plt.axis("off")
plt.show()
|
图综合示例
|
示例1
import networkx as nx
import matplotlib.pyplot as plt
# 创建一个社交网络图
social_network = nx.Graph()
# 添加人物节点
social_network.add_nodes_from(["Alice", "Bob", "Charlie", "David", "Eve"])
# 添加人物之间的关系边
social_network.add_edges_from([("Alice", "Bob"), ("Alice", "Charlie"), ("Bob", "David"), ("Charlie", "David"), ("Charlie", "Eve")])
# 给节点添加属性,如年龄
social_network.nodes["Alice"]['age'] = 25
social_network.nodes["Bob"]['age'] = 30
social_network.nodes["Charlie"]['age'] = 28
social_network.nodes["David"]['age'] = 35
social_network.nodes["Eve"]['age'] = 22
# 给边添加属性,如关系类型
social_network["Alice"]["Bob"]['relationship'] = "friend"
social_network["Alice"]["Charlie"]['relationship'] = "colleague"
social_network["Bob"]["David"]['relationship'] = "friend"
social_network["Charlie"]["David"]['relationship'] = "friend"
social_network["Charlie"]["Eve"]['relationship'] = "family"
# 查看社交网络的节点和边
print("社交网络的节点:", social_network.nodes())
print("社交网络的边:", social_network.edges())
# 查看节点和边的属性
for node, attr in social_network.nodes(data=True):
print(f"人物{node}的属性:{attr}")
for n1, n2, attr in social_network.edges(data=True):
print(f"关系{n1,n2}的属性:{attr}")
# 进行社交网络分析
# 例如,计算每个人物的度中心性(degree centrality),表示其在社交网络中的连接程度
degree_centrality = nx.degree_centrality(social_network)
print("度中心性:", degree_centrality)
# 绘制社交网络图
nx.draw(social_network, with_labels=True, node_color='lightgreen', edge_color='gray')
plt.show()
社交网络的节点: ['Alice', 'Bob', 'Charlie', 'David', 'Eve']
社交网络的边: [('Alice', 'Bob'), ('Alice', 'Charlie'), ('Bob', 'David'), ('Charlie', 'David'), ('Charlie', 'Eve')]
人物Alice的属性:{'age': 25}
人物Bob的属性:{'age': 30}
人物Charlie的属性:{'age': 28}
人物David的属性:{'age': 35}
人物Eve的属性:{'age': 22}
关系('Alice', 'Bob')的属性:{'relationship': 'friend'}
关系('Alice', 'Charlie')的属性:{'relationship': 'colleague'}
关系('Bob', 'David')的属性:{'relationship': 'friend'}
关系('Charlie', 'David')的属性:{'relationship': 'friend'}
关系('Charlie', 'Eve')的属性:{'relationship': 'family'}
度中心性: {'Alice': 0.5, 'Bob': 0.5, 'Charlie': 0.75, 'David': 0.5, 'Eve': 0.25}
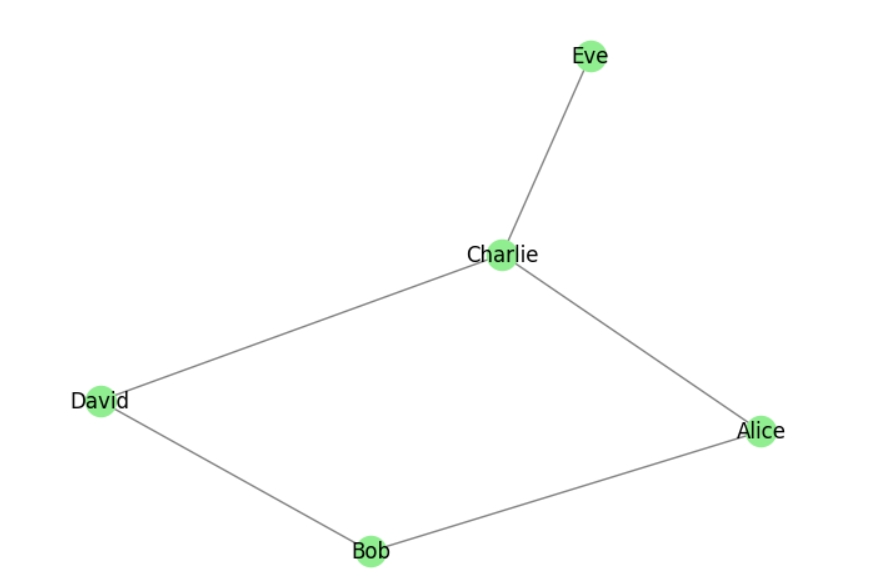
示例2
import networkx as nx
import matplotlib.pyplot as plt
# 设置支持中文的字体(使用系统自带的中文字体)
# plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体,windows
plt.rcParams['font.sans-serif'] = ['WenQuanYi Zen Hei'] # 文泉驿正黑,ubuntu
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 创建一个社交网络
social_network = nx.Graph()
social_network.add_edges_from([
("Alice", "Bob"), ("Alice", "Charlie"), ("Bob", "Charlie"),
("Charlie", "David"), ("David", "Eve"), ("Eve", "Frank"),
("Frank", "Grace"), ("Grace", "David"), ("Alice", "Frank"),
("Bob", "Eve"), ("Charlie", "Grace")
])
# 计算网络的基本属性
print("节点数量:", social_network.number_of_nodes())
print("边数量:", social_network.number_of_edges())
print("平均聚类系数:", nx.average_clustering(social_network))
print("平均最短路径长度:", nx.average_shortest_path_length(social_network))
节点数量: 7
边数量: 11
平均聚类系数: 0.23809523809523808
平均最短路径长度: 1.4761904761904763
# 识别关键人物(介数中心性最高的节点)
betweenness = nx.betweenness_centrality(social_network)
key_person = max(betweenness.items(), key=lambda x: x[1])[0]
print(f"关键人物: {key_person} (介数中心性: {betweenness[key_person]:.3f})")
关键人物: Charlie (介数中心性: 0.200)
|
import networkx as nx import matplotlib.pyplot as plt
# 创建一个交通网络图
traffic_network = nx.DiGraph()
# 添加地点节点
traffic_network.add_nodes_from(["A", "B", "C", "D", "E"])
# 添加地点之间的交通边,以及边的权重表示距离
traffic_network.add_edge("A", "B", weight=5)
traffic_network.add_edge("A", "C", weight=3)
traffic_network.add_edge("B", "C", weight=2)
traffic_network.add_edge("B", "D", weight=6)
traffic_network.add_edge("C", "D", weight=4)
traffic_network.add_edge("C", "E", weight=7)
traffic_network.add_edge("D", "E", weight=1)
# 查看交通网络的节点和边
print("交通网络的节点:", traffic_network.nodes())
print("交通网络的边:", traffic_network.edges())
# 进行交通网络分析
# 例如,计算从地点A到地点E的最短路径和最短路径长度
shortest_path = nx.shortest_path(traffic_network, source="A", target="E", weight="weight")
shortest_path_length = nx.shortest_path_length(traffic_network, source="A", target="E", weight="weight")
print("从A到E的最短路径:", shortest_path)
print("从A到E的最短路径长度:", shortest_path_length)
# 绘制交通网络图
pos = nx.spring_layout(traffic_network) # 使用spring布局
nx.draw(traffic_network, pos, with_labels=True, node_color='lightcoral', edge_color='gray')
edge_labels = nx.get_edge_attributes(traffic_network, "weight")
nx.draw_networkx_edge_labels(traffic_network, pos, edge_labels=edge_labels)
plt.show()
交通网络的节点: ['A', 'B', 'C', 'D', 'E']
交通网络的边: [('A', 'B'), ('A', 'C'), ('B', 'C'), ('B', 'D'), ('C', 'D'), ('C', 'E'), ('D', 'E')]
从A到E的最短路径: ['A', 'C', 'D', 'E']
从A到E的最短路径长度: 8
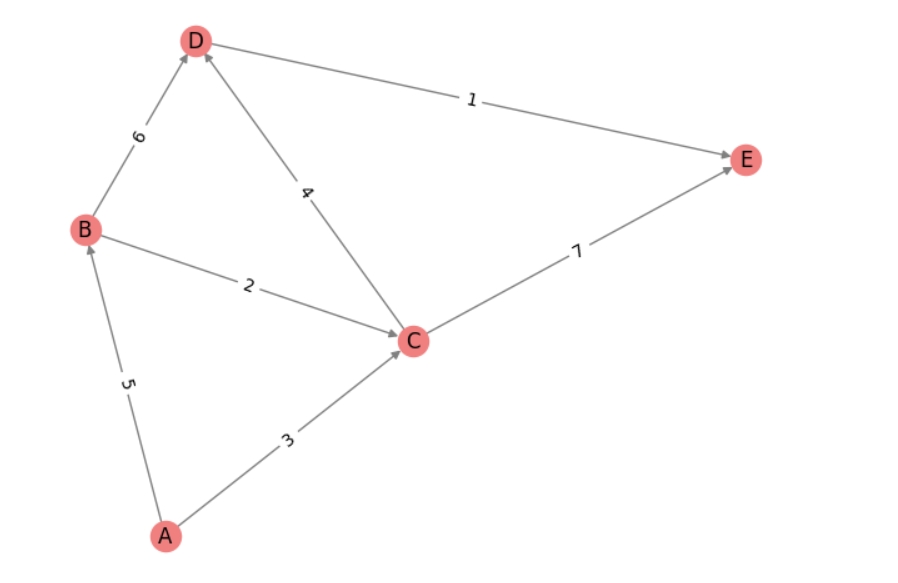
|
|
|
|
|
|
|
图邻接矩阵
import networkx as nx
import numpy as np
import matplotlib.pyplot as plt
from tpf.graph import show_lable_weigth
# 创建一个带权重的图
G = nx.Graph()
G.add_edges_from([(1, 2), (2, 3), (1, 3), (3, 4)])
show_lable_weigth(G,plt=plt)
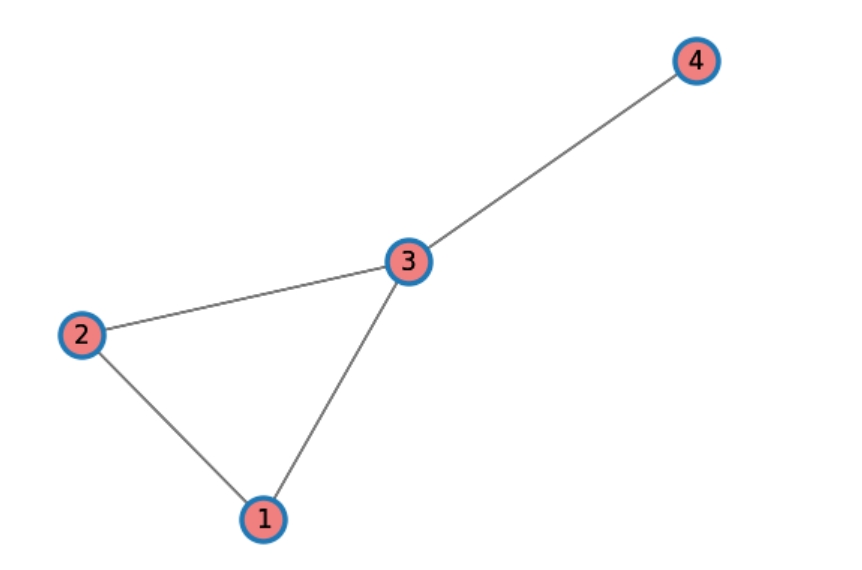
# 计算邻接矩阵
adj_matrix = nx.adjacency_matrix(G)
adj_matrix
4x4 sparse array of type 'class 'numpy.float64''
with 8 stored elements in Compressed Sparse Row format
# 转换为稠密矩阵(numpy数组)以便查看
adj_array = adj_matrix.todense()
print("邻接矩阵:")
print(adj_array)
邻接矩阵:
[[0 1 1 0]
[1 0 1 0]
[1 1 0 1]
[0 0 1 0]]
带权重
# 计算邻接矩阵
adj_matrix = nx.adjacency_matrix(G)
# 转换为稠密矩阵(numpy数组)以便查看
adj_array = adj_matrix.todense()
print("邻接矩阵:")
print(adj_array)
邻接矩阵:
[[0. 0.5 1.2 0. ]
[0.5 0. 0.8 0. ]
[1.2 0.8 0. 0.7]
[0. 0. 0.7 0. ]]
|
import numpy as np import networkx as nx # 创建一个带权重的图 G = nx.Graph() G.add_weighted_edges_from([(1, 2, 0.5), (2, 3, 0.8), (1, 3, 1.2), (3, 4, 0.7)]) # 生成邻接矩阵(NumPy 数组) adj_matrix = nx.to_numpy_array(G, weight='weight') print(adj_matrix)
[[0. 0.5 1.2 0. ]
[0.5 0. 0.8 0. ]
[1.2 0.8 0. 0.7]
[0. 0. 0.7 0. ]]
第 i 行第 j 列的值就是节点 i+1 和节点 j+1 之间的边权重。
如果想把节点编号换成自己想要的顺序,可传入 nodelist= 参数,例如:
adj_matrix = nx.to_numpy_array(G, nodelist=[1,2,3,4], weight='weight')
adj_matrix
array([[0. , 0.5, 1.2, 0. ],
[0.5, 0. , 0.8, 0. ],
[1.2, 0.8, 0. , 0.7],
[0. , 0. , 0.7, 0. ]])
节点顺序是 [1, 2, 3, 4](由 G.nodes() 决定)
adj_array[0,1] = 0.5 表示节点 1 和节点 2 之间的权重
adj_array[2,3] = 0.7 表示节点 3 和节点 4 之间的权重
得到的矩阵形状和行列顺序就与 nodelist 完全一致。
|
邻接矩阵表示的是 节点之间的是否存在边 - 存在为1,不存在为0 - 同时,这也是一个对称阵 ----------------------------------------------------------------- |
|
|
|
|
图算法
import networkx as nx
import matplotlib.pyplot as plt
from tpf.graph import show_lable_weigth
# 创建一个带权重的图
G = nx.Graph()
G.add_weighted_edges_from([(1, 2, 0.5), (2, 3, 0.8), (1, 3, 1.2), (3, 4, 0.7)])
# 计算最短路径
shortest_path = nx.shortest_path(G, source=1, target=4, weight="weight")
shortest_path_length = nx.shortest_path_length(G, source=1, target=4, weight="weight")
print(f"最短路径: {shortest_path}") # 输出: [1, 3, 4]
print(f"最短路径长度: {shortest_path_length}") # 输出: 1.9
show_lable_weigth(G,plt=plt)
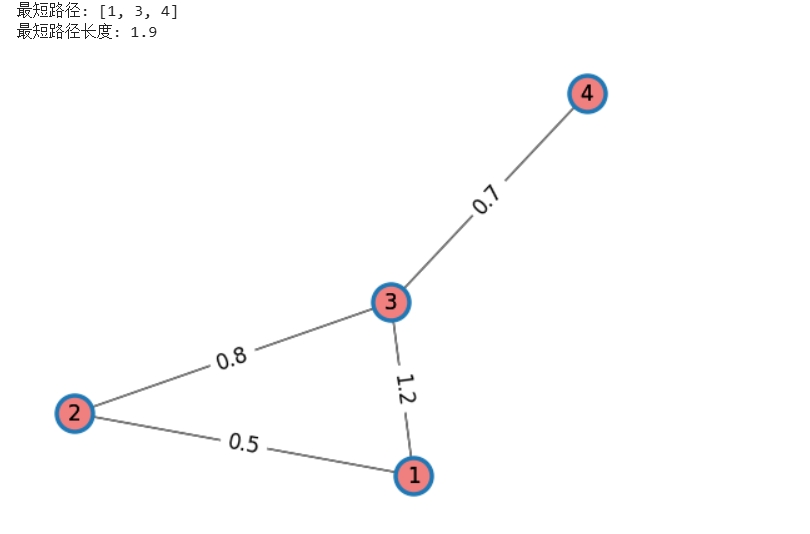
|
import networkx as nx
# 创建一个不连通图
G = nx.Graph()
G.add_edges_from([(1, 2), (2, 3), (4, 5), (5, 6), (7, 8)])
# 计算连通分量
connected_components = list(nx.connected_components(G))
print(f"连通分量: {connected_components}") # 输出: [{1, 2, 3}, {4, 5, 6}, {8, 7}]
连通分量: [{1, 2, 3}, {4, 5, 6}, {8, 7}]
|
import networkx as nx
# 创建一个小型社交网络
G = nx.Graph()
G.add_edges_from([("Alice", "Bob"), ("Alice", "Charlie"), ("Bob", "Charlie"),
("Charlie", "David"), ("David", "Eve")])
# 计算度中心性
degree_centrality = nx.degree_centrality(G)
print("度中心性:", degree_centrality)
度中心性: {'Alice': 0.5, 'Bob': 0.5, 'Charlie': 0.75, 'David': 0.5, 'Eve': 0.25}
# 计算接近中心性
closeness_centrality = nx.closeness_centrality(G)
print("接近中心性:", closeness_centrality)
接近中心性: {'Alice': 0.5714285714285714, 'Bob': 0.5714285714285714, 'Charlie': 0.8, 'David': 0.6666666666666666, 'Eve': 0.4444444444444444}
# 计算介数中心性
betweenness_centrality = nx.betweenness_centrality(G)
print("介数中心性:", betweenness_centrality)
介数中心性: {'Alice': 0.0, 'Bob': 0.0, 'Charlie': 0.6666666666666666, 'David': 0.5, 'Eve': 0.0}
|
import networkx as nx
import matplotlib.pyplot as plt
# 创建一个带权图
G = nx.Graph()
G.add_weighted_edges_from([(1, 2, 4), (1, 3, 2), (2, 3, 1),
(2, 4, 5), (3, 4, 8), (3, 5, 10),
(4, 5, 2), (4, 6, 6), (5, 6, 3)])
# 计算最小生成树
mst = nx.minimum_spanning_tree(G, weight="weight")
# 绘制结果
pos = nx.spring_layout(G)
nx.draw(G, pos, with_labels=True, alpha=0.5)
nx.draw_networkx_edges(mst, pos, edge_color="r", width=2)
plt.show()
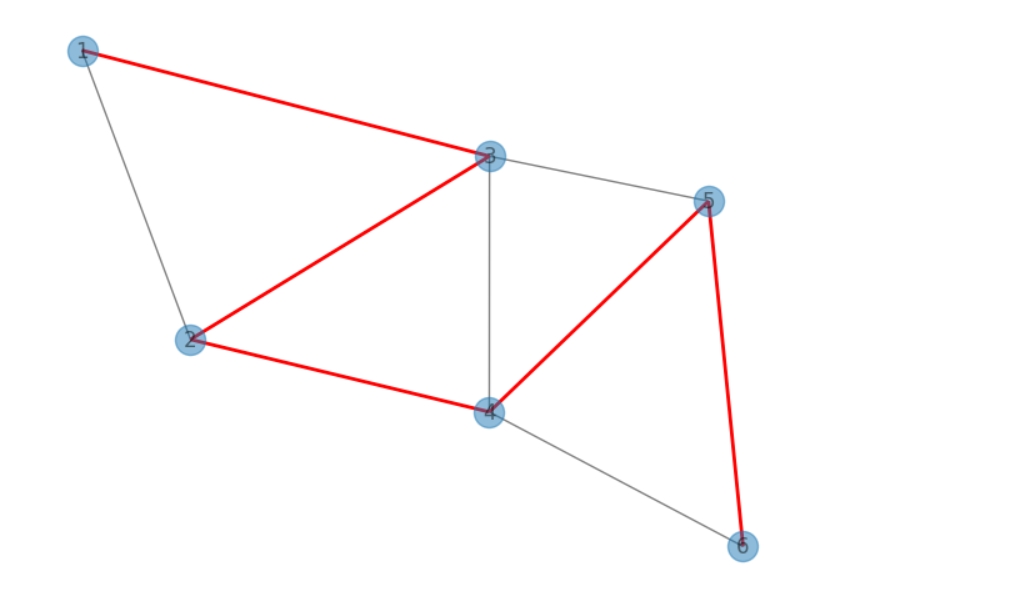
|
# 使用 Girvan-Newman 算法进行社区检测 from networkx.algorithms import community import networkx as nx # 创建一个具有社区结构的图 G = nx.karate_club_graph() # 检测社区 communities_generator = community.girvan_newman(G) top_level_communities = next(communities_generator) next_level_communities = next(communities_generator)
print("第一层社区划分:", sorted(map(sorted, top_level_communities)))
print("第二层社区划分:", sorted(map(sorted, next_level_communities)))
第一层社区划分: [[0, 1, 3, 4, 5, 6, 7, 10, 11, 12, 13, 16, 17, 19, 21], [2, 8, 9, 14, 15, 18, 20, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33]] 第二层社区划分: [[0, 1, 3, 4, 5, 6, 7, 10, 11, 12, 13, 16, 17, 19, 21], [2, 8, 14, 15, 18, 20, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33], [9]] |
|
|
|
|
|
图算法·进阶
import networkx as nx
# 创建一个有向图模拟网页链接
DG = nx.DiGraph()
DG.add_edges_from([(1, 2), (1, 3), (2, 3), (3, 1), (3, 4), (4, 3)])
# 计算 PageRank
pagerank = nx.pagerank(DG, alpha=0.85) # alpha 是阻尼因子
print("PageRank 值:", pagerank)
PageRank 值: {1: 0.21991357059363242, 2: 0.13096360941900992, 3: 0.4292092493937253, 4: 0.21991357059363242}
|
import networkx as nx
# 创建带容量的有向图
DG = nx.DiGraph()
DG.add_edge("s", "a", capacity=3.0)
DG.add_edge("s", "b", capacity=2.0)
DG.add_edge("a", "c", capacity=3.0)
DG.add_edge("b", "c", capacity=2.0)
DG.add_edge("b", "d", capacity=2.0)
DG.add_edge("c", "t", capacity=4.0)
DG.add_edge("d", "t", capacity=3.0)
# 计算从 s 到 t 的最大流
flow_value, flow_dict = nx.maximum_flow(DG, "s", "t")
print(f"最大流值: {flow_value}")
print("流分布:", flow_dict)
最大流值: 5.0
流分布: {'s': {'a': 3.0, 'b': 2.0}, 'a': {'c': 3.0}, 'b': {'c': 1.0, 'd': 1.0}, 'c': {'t': 4.0}, 'd': {'t': 1.0}, 't': {}}
- 这里不知为何d->t的值是1.0,明明是3.0
- d->t 不管我设置多少,流分布输出的都是1.0
import matplotlib.pyplot as plt from tpf.graph import show_lable_weigth show_lable_weigth(DG,plt,attr="capacity") 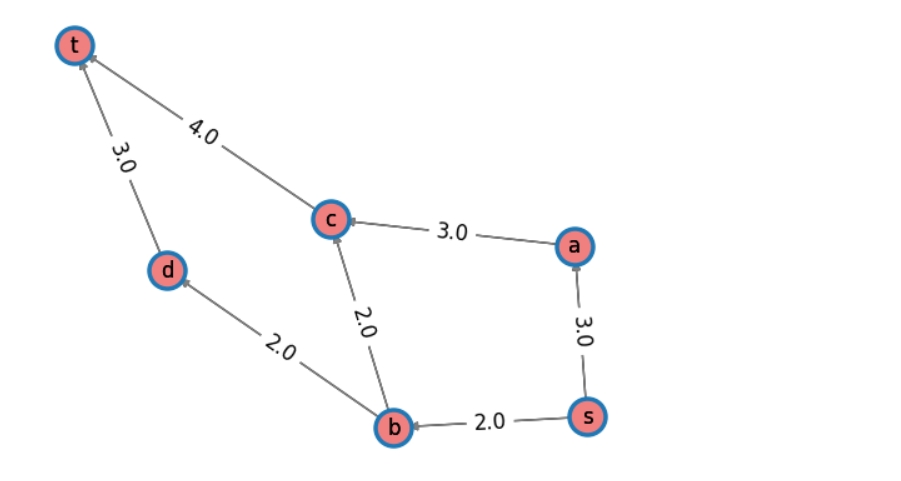
|
|
|
|
|
|
|
Cora数据集
|
数据加载(PyTorch Geometric 示例)
from torch_geometric.datasets import Planetoid
# 加载数据集
dataset = Planetoid(root='./data', name='Cora') # 可选 'CiteSeer' 或 'PubMed'
data = dataset[0] # 获取图数据
print(f"节点数: {data.num_nodes}, 边数: {data.num_edges}")
print(f"特征维度: {data.num_features}, 类别数: {dataset.num_classes}")
节点数: 2708, 边数: 10556 特征维度: 1433, 类别数: 7
http://1512000.xyz:8888/lab/tree/dl/gnn
http://172.26.114.122:8889/lab/tree/gnn
Planetoid 是图神经网络(GNN)研究中的一个经典基准数据集,主要用于节点分类任务
Planetoid 包含三个学术引文网络子数据集,每个数据集以论文为节点、引用关系为边,构成引文图
数据集概览
Cora
2,708 篇机器学习论文
5,429 条引用关系(无向边)
7 个类别(如神经网络、强化学习等)
每篇论文用 1,433 维词袋特征表示
CiteSeer
3,312 篇计算机科学论文
4,732 条引用关系
6 个类别
3,703 维词袋特征
PubMed
19,717 篇生物医学论文
44,338 条引用关系
3 个类别
500 维 TF-IDF 特征
关键特点
半监督学习设定:
每个数据集提供 20 个节点/类的标签作为训练集(Cora/CiteSeer),
PubMed 为 60 个节点/类,其余节点用于验证/测试。
同质图(Homophilic):
相邻节点倾向于相同类别(适合验证 GNN 的消息传递能力)。
特征稀疏性:
节点特征是词袋或 TF-IDF 向量,适合测试特征学习能力。
在 GNN 中的应用
经典基线任务:
用于验证 GCN(图卷积网络)、GAT(图注意力网络)等模型的性能。例如:
GCN 在 Cora 上可达 81.5% 准确率。
研究场景:
半监督节点分类
图表示学习
归纳式(Inductive)与直推式(Transductive)学习对比
注意事项
数据划分固定:
训练/验证/测试集已预定义,确保结果可比性。
引用关系无向化:
边被处理为无向边,适合大多数 GNN 模型。
特征标准化:
建议对节点特征做归一化(如 PubMed 的 TF-IDF 特征已标准化)。
Planetoid 因其简单性和代表性,成为 GNN 论文的“标准考题”,尤其适合验证模型在半监督场景下的性能
|
from torch_geometric.datasets import Planetoid # 加载数据集,Cora机器学习论文,每个节点代表一篇论文,边代表论文之间的引用关系,节点属性就是论文的特征;每个节点有7个类别 dataset = Planetoid(root='./data', name='Cora') # 可选 'CiteSeer' 或 'PubMed'
data = dataset[0] # 获取图数据
print(f"节点数: {data.num_nodes}, 边数: {data.num_edges}")
print(f"特征维度: {data.num_features}, 类别数: {dataset.num_classes}")
节点数: 2708, 边数: 10556
特征维度: 1433, 类别数: 7
data
Data(x=[2708, 1433], edge_index=[2, 10556], y=[2708], train_mask=[2708], val_mask=[2708], test_mask=[2708])
x: 节点特征,2708个节点,每个节点1433个特征
edge_index:
出节点组,入节点组,边从edge_index[0][i]节点出发,进入edge_index[1][i]节点,共有10556条边
y:节点的标签,2708个标签,一个节点一个标签
train_mask:训练集
val_mask:验证集
test_mask:测试集
|
|
表示图结构的数据形式 邻接矩阵(adjacency matrix)。 - 如果我们用A表示一个邻接矩阵,那么A[i,j] = 1就表示节点i和节点j之间存在一条边。 - 若A[i,j] = 0就表示节点i和节点j之间不存在连接。 - 因为图通常是稀疏的,所以我们经常用稀疏矩阵来存储这个邻接矩阵。 通过PyG提供的函数来把edge_index转换成稀疏矩阵 import networkx as nx import torch_geometric adj = torch_geometric.utils.to_scipy_sparse_matrix(dataset[0].edge_index) adj
2708x2708 sparse matrix of type 'class 'numpy.float32''
with 10556 stored elements in COOrdinate format>
2708x2708的矩阵带10556条边
COOrdinate 英/kəʊˈɔːdɪneɪt , kəʊˈɔːdɪnət/ 美/koʊˈɔːrdɪneɪt , koʊˈɔːrdɪnət/
n.坐标;
|
import matplotlib.pyplot as plt g = torch_geometric.utils.to_networkx(data, to_undirected=True) nx.draw(g, node_size=2) plt.show() 
周围零散的点,可以认为是孤立的点,因为它们与周围产生的连接少 - 中间的点有很多边,接连很多 - node_size:节点的直径,越大,画出的点面积就越大 |
|
|
CSR存储格式
import scipy.sparse as sp
from torch_geometric.datasets import Planetoid
dataset = Planetoid(root='./data', name='Cora') # 将数据保存在data文件夹下 data = dataset[0] adj = torch_geometric.utils.to_scipy_sparse_matrix(data.edge_index) adj为邻接矩阵
该函数将输入的边索引 edge_index(形状为 [2, num_edges])转换为对应的邻接矩阵。
邻接矩阵的形状是 [num_nodes, num_nodes],其中:
如果节点 i 和 j 之间存在一条边,则 A[i, j] = 1(默认无权情况)。
如果边有权重,可以通过 edge_weight 参数指定非零位置的值。
存储格式为稀疏矩阵 返回的是 SciPy 中的稀疏矩阵(默认是 coo_matrix 格式,即坐标格式)。 稀疏矩阵仅存储非零元素的位置和值,适合处理大规模图(避免内存浪费)。 可选参数 edge_weight:指定边的权重(默认全1)。 num_nodes:明确节点数量(否则根据 edge_index 自动推断)。 返回的稀疏矩阵格式可以通过 format 参数调整(如 'csr'、'csc' 等)。 示例代码 import torch from torch_geometric.utils import to_scipy_sparse_matrix # 示例边索引(2条边:0-1和1-2) edge_index = torch.tensor([[0, 1], [1, 2]], dtype=torch.long) # 转换为稀疏邻接矩阵(COO格式) adj_matrix = to_scipy_sparse_matrix(edge_index) print(adj_matrix) # 输出:非零位置 (0,1), (1,0), (1,2), (2,1)(无向图会双向添加) (0, 1) 1.0 (1, 2) 1.0
adj_matrix
3x3 sparse matrix of type 'class 'numpy.float32''
with 2 stored elements in COOrdinate format
注意事项 如果图是无向的,edge_index 应包含双向边(如 [0,1] 和 [1,0]),否则生成的邻接矩阵可能不对称。 如果需要密集矩阵格式,可以调用 .toarray() 方法(但仅适用于小规模图): dense_matrix = adj_matrix.toarray()
|
sp.csr_matrix(adj_matrix) 的作用是将输入的稀疏矩阵 adj_matrix(通常是 COO 格式或其他稀疏格式) 转换为 Compressed Sparse Row (CSR) 格式。 作用
转换稀疏矩阵存储格式:
将输入的 adj_matrix(可能是 SciPy 的 coo_matrix、lil_matrix 或其他格式)转换为更高效的 CSR 格式。
CSR 格式针对行操作(如行切片、矩阵-向量乘法)进行了优化,是许多数值计算(如 PageRank、图神经网络)的首选格式。
如果输入是稠密矩阵:
若 adj_matrix 是普通的 NumPy 数组或稠密矩阵,此函数会将其转换为稀疏 CSR 格式(仅存储非零元素)。
生成的矩阵结构(CSR 格式) CSR 格式通过三个数组存储非零元素: data:存储非零元素的值(例如邻接矩阵中的 1 或权重)。 indices:存储每列非零元素的列索引。 indptr:存储每行的起始位置在 indices/data 中的偏移量。 为什么用 CSR 格式 高效的行操作: CSR 格式的矩阵-向量乘法(如 A.dot(x))比 COO 格式更快,适合图神经网络中的消息传递(如 torch_sparse.matmul)。 内存连续: 存储方式紧凑,适合 GPU 加速计算(许多库如 PyTorch 支持 CSR 格式的 GPU 操作)。 实际应用场景 from scipy import sparse as sp # 假设 adj_matrix 是 COO 格式的邻接矩阵 adj_matrix = to_scipy_sparse_matrix(edge_index) # 默认生成 COO 格式 # 转换为 CSR 格式 csr_matrix = sp.csr_matrix(adj_matrix) # 可用于高效计算,如矩阵乘法 result = csr_matrix.dot(some_vector) 注意事项 输入类型: 如果 adj_matrix 已经是 CSR 格式,此操作不会复制数据,直接返回原矩阵。 无向图处理: 若 adj_matrix 未显式包含双向边(如 [0,1] 和 [1,0]),生成的 CSR 矩阵可能不对称,需手动处理。 |
|
假设邻接矩阵为: [[0, 1, 0], [1, 0, 1], [0, 1, 0]] 转换为 CSR 后: data = [1, 1, 1, 1] # 非零元素的值(默认边权重为1) indices = [1, 0, 2, 1] # 非零元素所在的列 indptr = [0, 1, 3, 4] # 每行的非零元素范围,其值是indices的索引切片[n:n+1]
解读 indptr:
第 0 行:非零元素在 data[0:1](列 indices[0]=1,值为 data[0]=1)。
第 1 行:非零元素在 data[1:3](列 indices[1]=0 和 indices[2]=2)。
第 2 行:非零元素在 data[3:4](列 indices[3]=1)。
indptr 的值为 [0, 1, 3, 4] 确实可能让人困惑,但它的含义并不是直接对应节点的索引,
而是 标记每一行的非零元素在 data 和 indices 数组中的位置范围
indptr(index pointer)是 CSR 格式的核心,
它存储的是 每一行的非零元素在 data 和 indices 数组中的起始和结束位置。
indptr设计规则 indptr[i] 给出第 i 行的非零元素在 data/indices 中的起始位置。 indptr[i+1] 给出第 i 行的非零元素在 data/indices 中的结束位置。 因此,第 i 行的 非零元素是 data[indptr[i]:indptr[i+1]], 对应的列索引是 indices[indptr[i]:indptr[i+1]]。
indices[indptr[i]:indptr[i+1]] 也是第i个节点的邻域
- 第i行就是第i个节点
|
|
假设邻接矩阵为: [[0, 1, 0], # 第0行 [1, 0, 1], # 第1行 [0, 1, 0]] # 第2行 非零元素的位置(行优先顺序): 第0行:列1(值1) 第1行:列0(值1)、列2(值1) 第2行:列1(值1) 对应的CSR数组: data = [1, 1, 1, 1] (所有非零元素的值,顺序是 (0,1)→(1,0)→(1,2)→(2,1)) indices = [1, 0, 2, 1] (非零元素的列索引) indptr = [0, 1, 3, 4] (关键!解释如下) 逐行解析 indptr: 第0行(i=0): 非零元素范围:indptr[0]:indptr[1] → 0:1 对应 data[0:1] = [1],indices[0:1] = [1] → 第0行的非零元素在列1,值为1。 第1行(i=1): 非零元素范围:indptr[1]:indptr[2] → 1:3 对应 data[1:3] = [1, 1],indices[1:3] = [0, 2] → 第1行的非零元素在列0和列2,值均为1。 第2行(i=2): 非零元素范围:indptr[2]:indptr[3] → 3:4 对应 data[3:4] = [1],indices[3:4] = [1] → 第2行的非零元素在列1,值为1。 为什么 indptr 的最大值是4 indptr 的最后一个元素是 4,因为共有4个非零元素(len(data)=4),它表示“结束位置”。 类似 Python 的切片规则:indptr[i+1] - indptr[i] 等于第 i 行的非零元素数量。 节点索引 vs. indptr 值 节点索引:0、1、2(对应矩阵的3行)。 indptr 值:0、1、3、4(标记非零元素的位置范围,与节点数量无关)。 这里的 3 和 4 是 data/indices 数组的索引,不是节点编号! |
|
|
Word2Vec
import jieba
from gensim.models import Word2Vec
#数字字符串,要能够转化为数字
sentences = [['1','2','3','4','5'],['6','5','3','7','8']]
# vector_size:词向量的维度,这里设置为100。
# window:上下文窗口大小,表示当前单词和周围单词的关联范围,这里设置为5。
# min_count:单词最少出现的次数,小于该次数的单词会被忽略,这里设置为1。
# workers:训练时使用的线程数,这里设置为4。
model = Word2Vec(sentences, vector_size=3, window=3, min_count=1)
model.wv.index_to_key # ['5', '3', '8', '7', '6', '4', '2', '1']
- 返回了所有的不重复的要编码的元素
map(int, model.wv.index_to_key)
- 将所有的元素转化为int类型
for i in map(int, model.wv.index_to_key):
print(type(i)) # class 'int'
break
|
|
高效转化np.array格式 import numpy as np a = ['5', '3', '8', '7', '6', '4', '2', '1'] np.fromiter(map(int, model.wv.index_to_key), np.int32)
这段代码中,`np.fromiter()` 函数的作用是
将一个可迭代对象(这里是 `map(int, model.wv.index_to_key)`)转换为一个 NumPy 数组。
### 具体分析:
1. **`map(int, model.wv.index_to_key)`**:
- `model.wv.index_to_key` 是一个包含字符串元素的列表(如 `['5', '3', '8', ...]`)。
- `map(int, ...)` 将列表中的每个字符串元素转换为整数(如 `'5'` → `5`,`'3'` → `3`,等等)。
- 这是一个惰性求值的迭代器,不会直接生成列表,而是按需计算。
2. **`np.fromiter()`**:
- 作用:将可迭代对象(如 `map` 对象、生成器等)转换为 NumPy 数组。
- 参数:
- 第一个参数是可迭代对象(这里是 `map(int, model.wv.index_to_key)`)。
- 第二个参数是 NumPy 数组的数据类型(这里是 `np.int32`,表示 32 位整数)。
- 返回值:一个 NumPy 数组,内容为转换后的整数。
### 示例: 如果 `model.wv.index_to_key` 是 `['5', '3', '8', '7', '6', '4', '2', '1']`,那么: ```python map(int, model.wv.index_to_key) # 生成一个迭代器,内容为 5, 3, 8, 7, 6, 4, 2, 1 np.fromiter(map(...), np.int32) # 生成数组:array([5, 3, 8, 7, 6, 4, 2, 1], dtype=int32) ``` ### 对比直接使用 `np.array`: 你也可以直接用 `np.array(list(map(int, model.wv.index_to_key)), dtype=np.int32)` 实现相同功能, 但 `np.fromiter` 更高效, 因为它不需要中间生成一个 Python 列表(直接由迭代器构建 NumPy 数组)。 ### 总结: `np.fromiter` 的作用是将 `map(int, model.wv.index_to_key)` 生成的整数迭代器转换为 `dtype=np.int32` 的 NumPy 数组,避免不必要的中间步骤,提高效率。 |
import numpy as np a = ['5', '3', '8', '7', '6', '4', '2', '1'] np.fromiter(map(int, model.wv.index_to_key), np.int32) array([5, 3, 8, 7, 6, 4, 2, 1], dtype=int32) np.fromiter(map(int, model.wv.index_to_key), np.int32).argsort() array([7, 6, 1, 5, 0, 4, 3, 2]) |
|
|
|
|
DeepWalk提取特征
图嵌入的通用框架:信息提取器、映射函数、重构器和优化目标 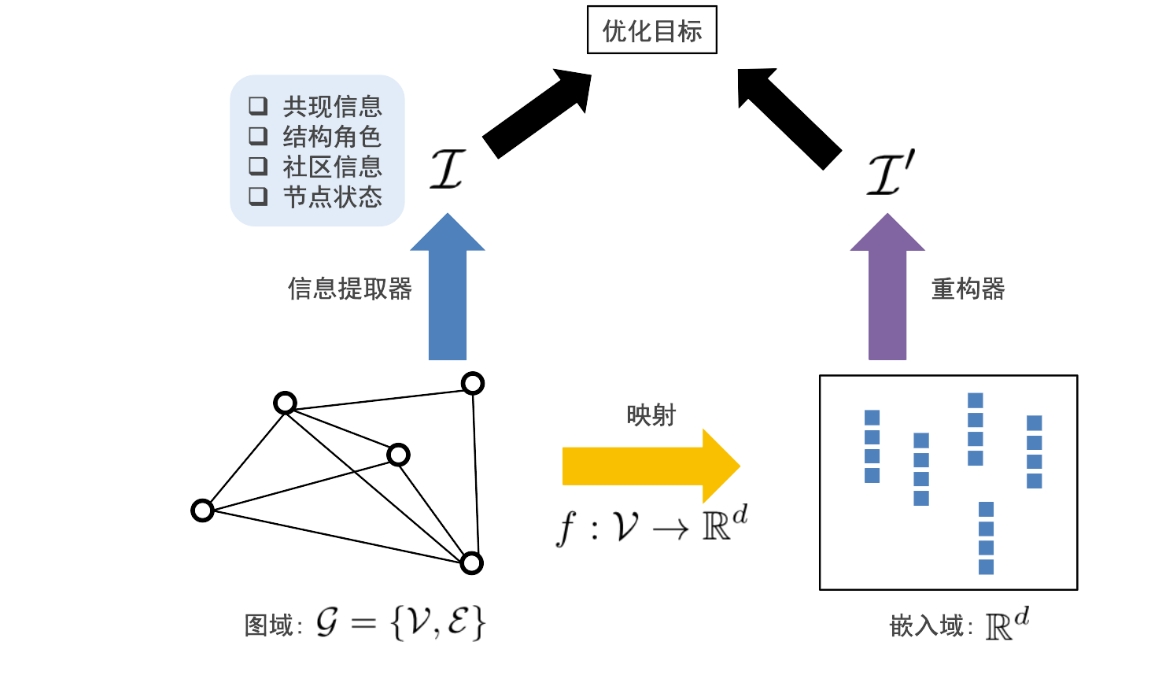
|
|
信息提取
使用随机游走的方法提取信息,从当前节点的邻域中随机提取一个节点,形成一条路径
np.random.choice可以从一组数据中随机选择出一个元素 import numpy as np arr = np.array([1,2,3,4,5]) np.random.choice(arr) # 4 每次执行都从arr中随机选择一个元素
for n in range(N): #对于每个节点
for il in range(walk_length): #生成长度为walk_length的列表
walks.append(n)
n = np.random.choice(indices[indptr[n]:indptr[n + 1]]) # 从节点n的邻居中随机采样一个节点作为新的节点
对于每个节点都生成生成长度为walk_length的列表,这个列表就是一次随机游走
-
Word2Vec将随机游走walks中的节点转化为向量
|
import numba
import numpy as np
# numba可以对Python程序进行加速(通过并行)。所以当我们的程序中有多重循环就可以考虑使用numba来加速。
# 将下面这行代码放在我们想要并行的函数上面。注意numba只能加速针对numpy数组的操作。
@numba.jit(nopython=True)
def _random_walk(indptr, indices, walk_length, walks_per_node):
"""并行地对图中每个节点采样随机游走
- 为了能够使用numba加速,该方法只处理Numpy数组
return
---------------------------
列表,一维;使用时,通常转换为2维reshape([-1, walk_length]);因为该方法使用了numba并行计算,因为维度的转换放外面
"""
N = len(indptr) - 1 # 得到节点数量
walks = []
for ir in range(walks_per_node):
for n in range(N): #对于每个节点
for il in range(walk_length): #生成长度为walk_length的列表
#第1次循环添加当前节点,第2次n变成了当前节点的领域节点中的下一个,然后多次循环就产生一个路径
walks.append(n)
n = np.random.choice(indices[indptr[n]:indptr[n + 1]]) # 从节点n的邻居中随机采样一个节点作为新的节点
return np.array(walks)
from torch_geometric.datasets import Planetoid dataset = Planetoid(root='./data', name='Cora') # 将数据保存在data文件夹下 data = dataset[0] import torch_geometric adj = torch_geometric.utils.to_scipy_sparse_matrix(data.edge_index)
import scipy.sparse as sp
embedding_dim=64
walk_length=80
walks_per_node=10
num_neg_samples=1
# 利用随机游走提取共现信息
adj = sp.csr_matrix(adj) #将邻接矩阵转换为稀疏矩阵
walks = _random_walk(adj.indptr, #行坐标
adj.indices, #列坐标
walk_length,
walks_per_node).reshape([-1, walk_length])
#2708个节点,每个节点10个路径,每个路径80步/节点
walks.shape #(27080, 80)
walks[0]
array([ 0, 2582, 0, 1862, 2582, 1166, 1986, 1558, 2338, 1558, 2338,
1558, 1986, 1127, 1583, 973, 115, 973, 935, 451, 935, 854,
203, 1115, 470, 1115, 809, 266, 578, 1105, 578, 266, 809,
1115, 809, 2228, 809, 2228, 2395, 1396, 2395, 2228, 809, 266,
2229, 809, 2228, 2227, 1630, 737, 2136, 1671, 2136, 1655, 2295,
1655, 1131, 2283, 1131, 836, 1572, 836, 519, 598, 869, 1440,
869, 1701, 1854, 1701, 261, 1701, 1870, 157, 1701, 563, 2045,
215, 1986, 2007])
walk = walks[0]
map(str, walk) # map at 0x786bcc533070
for i in map(str, walk):
print(type(i)) # class 'str'
break
map(str, walk)
- 将list中的每个元素转化为str
|
def deepwalk(adj, embedding_dim=64, walk_length=80, walks_per_node=10,
num_neg_samples=1):
"""
参数说明
----------
adj : 图的邻接矩阵
embedding_dim : 图嵌入的维度
walks_per_node : 每个节点采样多少个随机游走
walk_length : 随机游走的长度
num_neg_samples : 负样本的数量
"""
walks = sample_random_walks(adj, walk_length, walks_per_node) # 利用随机游走提取共现信息
model = Word2Vec(walks, vector_size=embedding_dim,
negative=num_neg_samples, compute_loss=True) # 映射函数、重构器、目标
embedding = model.wv.vectors[np.fromiter(map(int, model.wv.index_to_key), np.int32).argsort()] # 从词向量中取出节点嵌入
return embedding
walks.shape = [节点个数n*每个节点包含的路径数m, 步长s] - 一张图有N个节点 - 从每个节点出发都有m条路径,众节点包含的路径个数一致,谁不比谁多或少 路径不同,就反应了节点的不同 Word2Vec算法可以充分地挖掘item前后依赖信息,上下文信息,并将这些上下文信息以向量的形成记录下来 - 这就是共现信息,提取的是关系网络中的关系信息 |
|
|
Node2Vec
import torch_cluster random_walk = torch.ops.torch_cluster.random_walk batch = batch.repeat(self.walks_per_node) rowptr, col, _ = self.adj.csr() rw = random_walk(rowptr, col, batch, self.walk_length, self.p, self.q) # 采样随机游走 rowptr (Tensor) - 图的压缩稀疏行(CSR)格式的行指针数组。 - 表示图中每个节点的邻居在 col 中的起始和结束位置。 - 形状为 [num_nodes + 1],数据类型通常是 int32 或 int64。 这样可以在 O(1) 时间内定位任意节点的邻居区间 col (Tensor) - 图的 CSR 格式的列索引数组。 - 存储图中所有边的邻居节点 - 按 rowptr 指定的区间保存每个节点的所有出边(或入边,取决于图的构建方式)对应的目标节点编号 - 形状为 [num_edges],数据类型与 rowptr 一致。 batch (Tensor)
- 本次要作为随机游走起点的节点编号张量,一个一维张量,表示每个节点所属的批次(batch)。
- 长度等于 batch_size * walks_per_node,即每个节点会被重复 walks_per_node 次,以并行地生成多条游走路径
- 形状为 [num_nodes],值范围是 [0, num_graphs - 1]
- batch标记了每个节点属于哪个图,知道哪些节点属于同一张图,随机游走时就可以不跨图了
walk_length (int)
- 每条随机游走的步数(不含起始节点)。
- 因此返回张量的第二维长度是 walk_length + 1。
p (float)(Return parameter)
控制“返回上一跳”的概率权重。
值越大,游走越倾向于在局部徘徊;值越小,越容易远离起点。
q(In-out parameter)
控制“向内还是向外”探索的概率权重。
- q < 1 鼓励向外探索(BFS 倾向);
- q > 1 鼓励向内探索(DFS 倾向)。
返回值: rw (Tensor) - 形状为 (len(batch), walk_length + 1), - 每一行是一条从对应节点出发的随机游走路径 - 因为每个节点都有一个batch值,而rw又与batch对应,因此rw的r就对应了节点个数 - 第i个节点有一条随机游走路径,这条随机游走路径不一定包含所有的节点,但一定包含本节点 补充说明 该函数实现了 Node2Vec 风格的随机游走,通过 p 和 q 控制游走的偏向性(平衡局部和全局探索)。 如果 p = q = 1,则退化为普通的深度优先随机游走(无偏)。 batch 参数允许同时对多个独立的图进行随机游走(例如,批处理中的不同图)。
|
import torch_cluster random_walk = torch.ops.torch_cluster.random_walk # 假设一个图有 3 个节点,边为 0-1, 1-2 rowptr = torch.tensor([0, 1, 2, 3]) # CSR 行指针 col = torch.tensor([1, 0, 2]) # CSR 列索引 batch = torch.tensor([0, 0, 0]) # 所有节点属于同一个图 walk_length = 2 p, q = 1.0, 1.0 rw = random_walk(rowptr, col, batch, walk_length, p, q) # 可能输出(随机性): [[0, 1, 0], [1, 0, 1], [2, 1, 0]]
rw
(tensor([[0, 1, 0],
[0, 1, 0],
[0, 1, 0]]),
tensor([[0, 1],
[0, 1],
[0, 1]]))
batch 参数的作用 在 torch.ops.torch_cluster.random_walk 的上下文中, batch 参数的作用是 区分不同图中的节点, 从而支持同时对多个独立的图(例如批处理中的多个图)进行随机游走。 batch 参数的含义 batch 是一个一维张量,长度等于图中节点的总数(num_nodes)。 batch[i] 的值表示第 i 个节点属于哪个图(批次)。 例如: batch = [0, 0, 0]:3 个节点均属于图 0(即只有一个图)。 batch = [0, 1, 1]:第 0 个节点属于图 0,第 1、2 个节点属于图 1(共两个图)。 所有节点属于同一个图 当 batch 的所有值相同(如 [0, 0, 0])时,说明所有节点都属于同一个图(即 batch 的值为 0 的图)。 此时,随机游走会在单个图内进行,不会跨图游走(因为其他图不存在)。 与批处理(Batching)的关系
如果输入是多个独立的图(例如批处理场景),可以通过 batch 区分不同图的节点。
例如,有两个图:
图 0:节点 0、1
图 1:节点 2、3
则 batch = [0, 0, 1, 1],random_walk 会分别在两个图内部分别采样游走。
为什么需要 batch 图数据通常以批处理形式输入(如多个分子图、社交网络子图等), batch 确保随机游走不跨越不同图(因为实际场景中图之间没有边)。 如果忽略 batch(所有节点属于同一图),则可能错误地在不同图的节点之间游走(逻辑错误)。 单图情况(所有节点属于同一图) rowptr = torch.tensor([0, 1, 2, 3]) # 图包含 3 个节点(0-1-2) col = torch.tensor([1, 0, 2]) # 边:0-1, 1-0, 1-2 batch = torch.tensor([0, 0, 0]) # 所有节点属于图 0 rw = random_walk(rowptr, col, batch, walk_length=2, p=1, q=1) # 可能输出:[[0, 1, 0], [1, 0, 1], [2, 1, 0]](仅在 0-1-2 内游走) 多图情况(批处理)
rowptr = torch.tensor([0, 1, 3, 4]) # 两个子图:图0(节点0-1),图1(节点2-3)
col = torch.tensor([1, 0, 2, 1]) # 边:0-1, 1-0, 1-2, 2-1
batch = torch.tensor([0, 0, 1, 1]) # 节点0、1属于图0;节点2、3属于图1
rw = random_walk(rowptr, col, batch, walk_length=2, p=1, q=1)
# 可能输出:[[0, 1, 0], [1, 0, 1], [2, 1, 2], [3, 1, 3]](图0和图1分别游走)
总结
batch 的作用是 划分节点所属的独立图,确保随机游走仅在同一个图的内部进行。
当所有节点的 batch 值相同时,等价于所有节点属于同一个图(无需批处理)。
这种设计是图批处理(Batching)中的常见模式,类似于其他图操作(如 scatter、segment)中的批次区分。
|
|
正样本 确保每个节点有一定数据的随机游走 从每个随机游走,按固定长度滑动窗口,截取的节点链就是正样本 这样的样本包含了图中的信息,所以才是正样本 负样本 负样本随机采样,不包含图中信息,随机选择节点,形成的路径,作为负样本
torch.randint(3,(3,10))Docstring:
randint(low=0, high, size, ..., requires_grad=False) -> Tensor
tensor([[0, 1, 1, 0, 0, 1, 2, 1, 2, 2],
[0, 2, 1, 1, 0, 0, 1, 2, 2, 1],
[0, 1, 1, 0, 2, 1, 1, 2, 2, 2]])
batch = batch.repeat(self.walks_per_node * self.num_negative_samples)
rw = torch.randint(self.adj.sparse_size(0),
(batch.size(0), self.walk_length)) # 直接随机采样图中节点序列作为负样本
|
import torch from torch_sparse import SparseTensor # 示例边索引(2条边:0-1和1-2) edge_index = torch.tensor([[0, 1], [1, 2]], dtype=torch.long) N = edge_index.max().item() + 1 # 节点数量 #row为出边节点,col为入边节点 row,col = edge_index adj = SparseTensor(row=row, col=col, sparse_sizes=(N, N))
adj
SparseTensor(row=tensor([0, 1]),
col=tensor([1, 2]),
size=(3, 3), nnz=2, density=22.22%)
adj.sparse_size(0) 3 SparseTensor 是 torch_sparse 库中的一个核心类, 用于高效地存储和操作稀疏矩阵(尤其是图数据中的邻接矩阵)。 在这段代码中,它的作用是将图的边列表(edge_index)转换为一个稀疏的邻接矩阵表示,从而节省内存并加速计算。 表示图的邻接矩阵 图的边列表 edge_index = [[0, 1], [1, 2]] 表示两条有向边:0→1 和 1→2。 SparseTensor 会构建一个形状为 (N, N) 的稀疏矩阵(N 是节点数量), 其中非零元素的位置由 row(出边节点)和 col(入边节点)决定。 例如,上述边对应的邻接矩阵(稠密形式)为: [ [0, 1, 0], [0, 0, 1], [0, 0, 0]] 用 SparseTensor 存储时,只需记录非零值的位置(即边的信息),避免存储大量的零元素。 高效计算 稀疏矩阵乘法(如消息传递、图卷积)在 SparseTensor 格式下比稠密矩阵更高效, 尤其是当图非常稀疏时(如节点数多但边数少)。 支持快速的图操作(如转置、邻接矩阵的乘法、邻居采样等)。 与 PyTorch 生态集成 SparseTensor 可以直接参与 PyTorch 的计算图, 支持自动微分(torch.autograd),适合用于图神经网络(GNN)的实现。 代码中的关键参数 row=row:边的起点(出边节点索引)。 col=col:边的终点(入边节点索引)。 sparse_sizes=(N, N):指定稀疏矩阵的形状(节点数 × 节点数)。 如果边上有权重,还可以通过 value 参数传入(例如:value=torch.tensor([1.0, 1.0]))。 
|
随机采样图中的路径为正样本,以随机生成的序列为负样本 设计损失函数抑制负样本,强化正样本 经过训练后,生成的向量就能代表图中的路径信息...
def loss(self, pos_rw, neg_rw):
"""根据正负样本计算损失函数"""
EPS = 1e-15 # 出现在下面的地方,用于防止torch.log()中的输入为0
# 正样本的损失函数
start, rest = pos_rw[:, 0], pos_rw[:, 1:].contiguous()
h_start = self.embedding(start).view(pos_rw.size(0), 1,
self.embedding_dim)
h_rest = self.embedding(rest.view(-1)).view(pos_rw.size(0), -1,
self.embedding_dim)
out = (h_start * h_rest).sum(dim=-1).view(-1) # 计算内积
pos_loss = -torch.log(torch.sigmoid(out) + EPS).mean() # 希望start, reset的嵌入的内积大
# 负样本的损失函数
start, rest = neg_rw[:, 0], neg_rw[:, 1:].contiguous()
h_start = self.embedding(start).view(neg_rw.size(0), 1,
self.embedding_dim)
h_rest = self.embedding(rest.view(-1)).view(neg_rw.size(0), -1,
self.embedding_dim)
out = (h_start * h_rest).sum(dim=-1).view(-1) # 计算内积
neg_loss = -torch.log(1 - torch.sigmoid(out) + EPS).mean() # 希望start, reset的嵌入的内积小
return pos_loss + neg_loss
|
MetaPath2Vec
from torch_geometric.nn import MetaPath2Vec
# 定义metapath
metapath = [
('author', 'writes', 'paper'),
('paper', 'published_in', 'venue'),
('venue', 'publishes', 'paper'),
('paper', 'written_by', 'author'),
]
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = MetaPath2Vec(subgraph.edge_index_dict, embedding_dim=128,
metapath=metapath, walk_length=50, context_size=7,
walks_per_node=5, num_negative_samples=5,
sparse=True).to(device)
loader = model.loader(batch_size=128, shuffle=True, num_workers=6)
optimizer = torch.optim.SparseAdam(list(model.parameters()), lr=0.01)
def train():
model.train()
total_loss = 0
for i, (pos_rw, neg_rw) in enumerate(loader):
optimizer.zero_grad()
loss = model.loss(pos_rw.to(device), neg_rw.to(device))
loss.backward()
optimizer.step()
total_loss += loss.item()
@torch.no_grad()
def test(train_ratio=0.9):
model.eval()
batch_size = subgraph['author'].batch_size
z = model('author')[:batch_size]
y = subgraph['author'].y[:batch_size]
perm = torch.randperm(z.size(0))
train_perm = perm[:int(z.size(0) * train_ratio)]
test_perm = perm[int(z.size(0) * train_ratio):]
return model.test(z[train_perm], y[train_perm], z[test_perm], y[test_perm],
max_iter=1000)
for epoch in range(1, 5):
train()
acc = test()
print(f'Epoch: {epoch}, Accuracy: {acc:.4f}')
参考资料: node_embedding.py metapath2vec.py
|
|
|
|
|
|
|
|
数据集训练准备
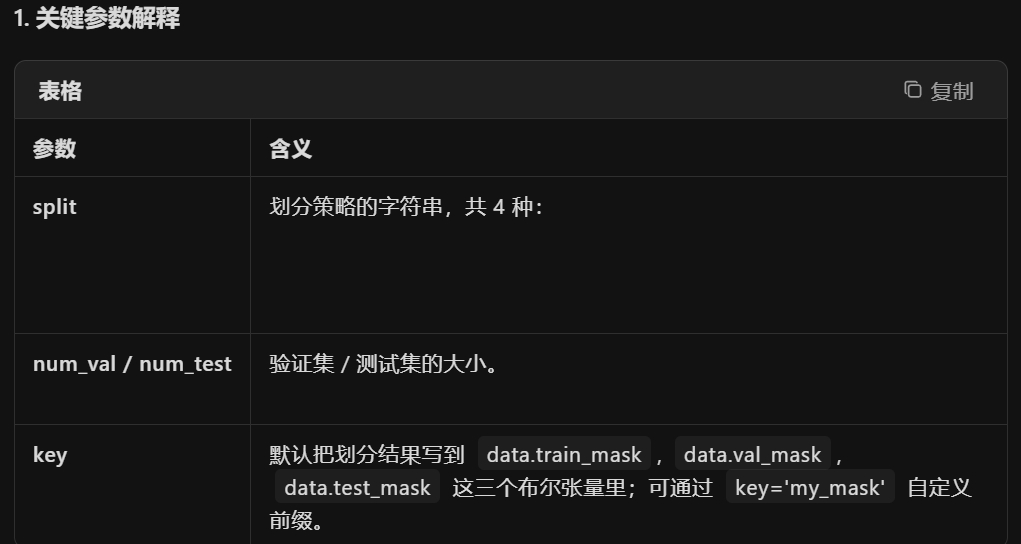
import torch_geometric.transforms as T split = T.RandomNodeSplit(split='train_rest', num_val=0.1, num_test=0)
T.RandomNodeSplit 是 PyTorch Geometric 提供的 图数据增强/划分 工具,
用来 随机地把图中的节点划分成训练 / 验证 / 测试集。
split = T.RandomNodeSplit(
split='train_rest', # 划分策略
num_val=0.1, # 验证集占 10%
num_test=0 # 不划分测试集(测试集空)
)
from torch_geometric.transforms import RandomNodeSplit
from torch_geometric.datasets import Planetoid
transform = RandomNodeSplit(split='train_rest', num_val=0.1, num_test=0)
dataset = Planetoid(root='./data', name='Cora', transform=transform)
data = dataset[0] # 此时 data.train_mask / data.val_mask / data.test_mask 已经生成
print(data.train_mask.sum()) # tensor(2437) 训练节点数
print(data.val_mask.sum()) # tensor(271) 验证节点数 ≈ 10%
print(data.test_mask.sum()) # tensor(0)
参数组合 结果 split='train_rest', num_val=0.1, num_test=0.2 训练 = 70%,验证 = 10%,测试 = 20% split='test_rest', num_val=0.1, num_test=0.2 训练 = 70%,验证 = 10%,测试 = 20%,但先扣掉 train/val,其余给 test split='random', num_val=100, num_test=200 完全随机挑 100 个验证、200 个测试节点,其余给训练
RandomNodeSplit 像一把“随机剪刀”,按指定比例把节点切成 train / val / test 三组,
并把布尔掩码写进 data.*_mask,后续训练循环直接按掩码选节点即可。
|
NeighborLoader 是 PyTorch Geometric(≥2.0)提供的 “子图采样器”,专为 大规模图 设计。 它按节点批次(mini-batch)动态地 采样邻居,把整张图切成一个个“小图”喂给模型,避免一次性把大图塞进显存。 关键参数解释 参数 含义 data 完整的 Data 或 HeteroData 对象。 num_neighbors 每层采样多少邻居。列表长度 = 采样深度(GNN 层数)。 batch_size 每次取多少个“中心节点”作为子图的根。 input_nodes 指定从哪些节点开始采样。通常用 train_mask、val_mask 等布尔掩码。 shuffle 每个 epoch 是否打乱中心节点顺序(默认 True)。 replace 邻居采样是否允许重复(默认 False)。 工作流程 data.train_mask 中共有 N 个训练节点。 NeighborLoader 先把这 N 个节点按 batch_size=256 分成若干批。 每取一批 256 个“中心节点”,递归地: 第 1 层:为每个中心节点采样最多 30 个 1-hop 邻居。 第 2 层:再为这 30 个邻居各采样最多 30 个 2-hop 邻居。 将采样得到的节点、边组成一个 子图(mini-batch),只包含相关节点/边,显存占用大幅下降。 返回的 Batch 对象可直接喂给 GAT 等模型。 for batch in train_loader: # batch 是 Data 对象,但只含采样子图 batch = batch.to(device) out = model(batch.x, batch.edge_index) # 前向 loss = criterion(out[batch.train_mask], batch.y[batch.train_mask]) ... 注意:batch 里带的 train_mask、y 等张量长度 = 子图节点数,不再是原图长度。 通常只需 out.squeeze() 和 batch.y 直接对齐即可。 NeighborLoader 把 巨型图切成可管理的小图,每层按 num_neighbors 采样邻居, 配合 batch_size 实现 小批次训练,是 大图 GNN 训练的核心工具 |
|
|
|
|
|
|
参考
神经网络】神经元ReLU、Leaky ReLU、PReLU和RReLU的比较