ibm数据
|
项目信息 https://www.kaggle.com/code/issacchanjj/anti-money-laundering-detection-with-gnn
#IMPORT STATEMENTS
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
pd.set_option('display.max_columns', None)
data_path = "/wks/datasets/ibm_aml/HI-Small_Trans.csv"
df=pd.read_csv(data_path)
df[:3]
数据类型 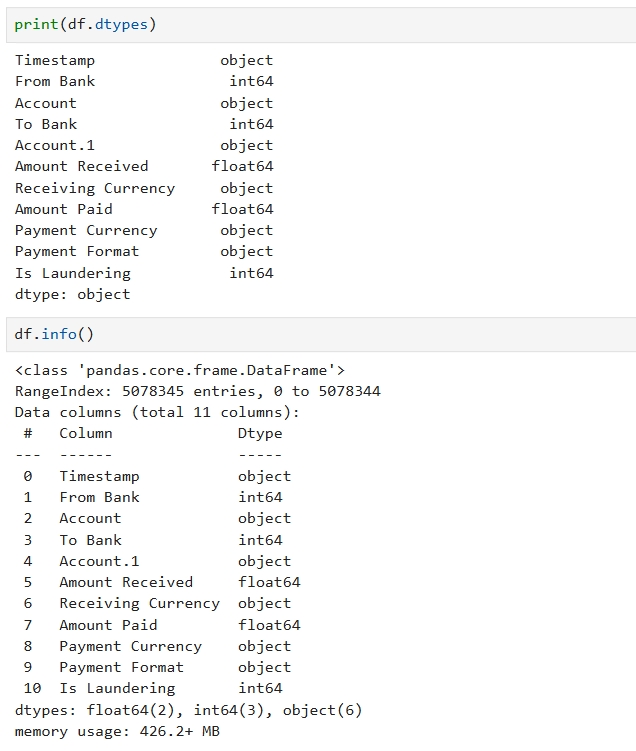

df.shape
(5078345, 11)
df.isna().sum()
Timestamp 0
From Bank 0
Account 0
To Bank 0
Account.1 0
Amount Received 0
Receiving Currency 0
Amount Paid 0
Payment Currency 0
Payment Format 0
Is Laundering 0
dtype: int64
df.duplicated().sum()
9
result = (df["Amount Received"] == df["Amount Paid"]).all()
print(result)
False
result = (df["Receiving Currency"] == df["Payment Currency"]).all()
print(result)
False
result = set(df["Receiving Currency"].unique()) ==set(df["Payment Currency"].unique())
print(result)
True
Check the dataset is balanced or not
df["Is Laundering"].unique()
array([0, 1])
df["Is Laundering"].value_counts()
Is Laundering
0 5073159
1 5177
Name: count, dtype: int64
target_count=df["Is Laundering"].value_counts()
target_count.index,target_count.values
(Index([0, 1], dtype='int64', name='Is Laundering'), array([5073159, 5177]))
round(target_count.values[0]/target_count.values[1])
980
plt.subplot(1,2,1) sns.barplot(x=target_count.index,y=target_count.values) plt.subplot(1,2,2) plt.pie(target_count.values,labels=target_count.index); 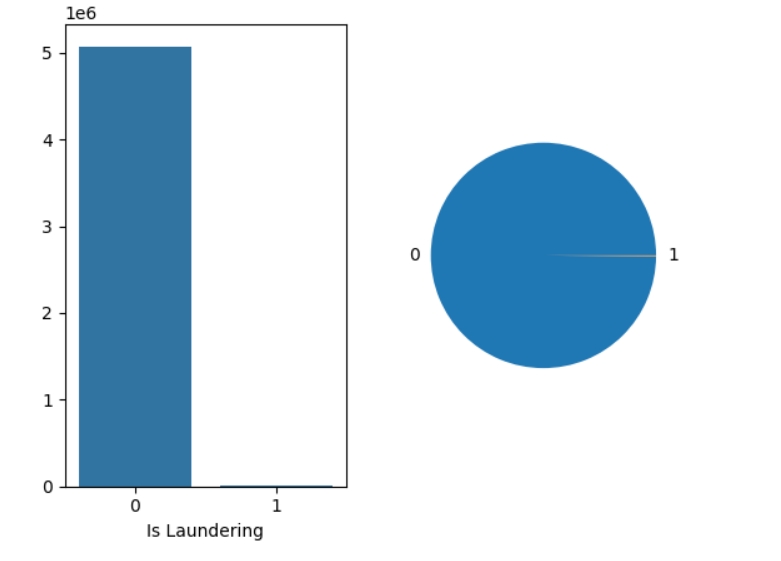
|
# Convert the "Timestamp" column to datetime format
df["Timestamp"] = pd.to_datetime(df["Timestamp"])
# Extract Date, Day, and Time from the Timestamp
df["Date"] = df["Timestamp"].dt.date
df["Day"] = df["Timestamp"].dt.day_name()
df["Time"] = df["Timestamp"].dt.time
df.drop(columns=["Timestamp"], inplace=True)

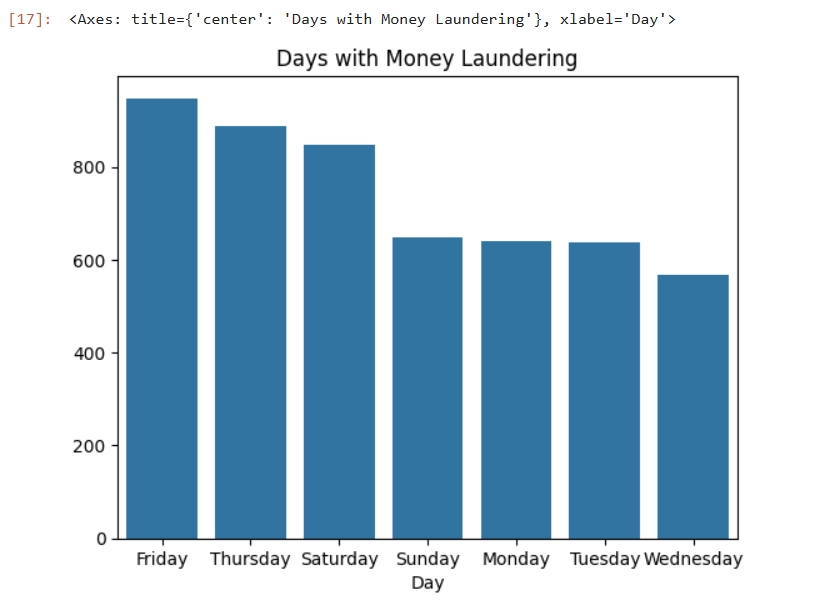
Date Time with Money Laundering
plt.title("Days with Money Laundering")
day=df[df["Is Laundering"]==1]["Day"].value_counts()
sns.barplot(x=day.index,y=day.values)
卡方验证
chi2_contingency是scipy库中用于执行卡方独立性检验的函数。
在统计学中,卡方独立性检验(Chi-Square Test of Independence)是一种用来确定两个变量之间是否有显著关联的方法。
具体来说,它是根据列联表中的观察频率来计算卡方统计量和p值,从而判断两个变量是否独立,或者它们之间是否存在某种关联性。
这种检验通常用于分类数据,以检验两个分类变量是否相互独立。
scipy.stats.chi2_contingency函数能够方便地从给定的列联表中找到期望频率和自由度,进而执行卡方独立性检验。
使用该函数时,用户需要提供一个包含观测值的二维数组(即列联表),
其中每一行代表一个因素的不同水平,每一列代表另一个因素的不同水平。
函数将返回卡方统计量、p值、自由度和期望频率等结果。
基于这些结果,用户可以判断两个变量之间是否存在显著的关联性。
例如,如果p值小于某个显著性水平(如0.05),则可以拒绝两个变量相互独立的原假设,认为它们之间存在显著的关联性。
contingency = pd.crosstab(df['Is Laundering'], df['Day'])
import scipy.stats as st
x,p,y,z = st.chi2_contingency(contingency)
if p < 0.05:
print("There is a relationship")
else:
print("There is no relationship")
There is a relationship
contingency = pd.crosstab(df['Is Laundering'], df['Time'])
import scipy.stats as st
x,p,y,z = st.chi2_contingency(contingency)
if p < 0.05:
print("There is a relationship")
else:
print("There is no relationship")
There is a relationship
|
df["Payment Format"].unique()
array(['Reinvestment', 'Cheque', 'Credit Card', 'ACH', 'Cash', 'Wire',
'Bitcoin'], dtype=object)
payment_format=df[df["Is Laundering"]==1]["Payment Format"].value_counts() plt.figure(figsize=(15,4)) plt.subplot(1,2,1) sns.barplot(x=payment_format.index,y=payment_format.values) plt.subplot(1,2,2) plt.pie(payment_format.values,labels=payment_format.index,wedgeprops=dict(width=0.4)); #use semicolon to avoid texts in O/P |
df["Receiving Currency"].unique()
array(['US Dollar', 'Bitcoin', 'Euro', 'Australian Dollar', 'Yuan',
'Rupee', 'Mexican Peso', 'Yen', 'UK Pound', 'Ruble',
'Canadian Dollar', 'Swiss Franc', 'Brazil Real', 'Saudi Riyal',
'Shekel'], dtype=object)
df["Payment Currency"].unique()
array(['US Dollar', 'Bitcoin', 'Euro', 'Australian Dollar', 'Yuan',
'Rupee', 'Yen', 'Mexican Peso', 'UK Pound', 'Ruble',
'Canadian Dollar', 'Swiss Franc', 'Brazil Real', 'Saudi Riyal',
'Shekel'], dtype=object)
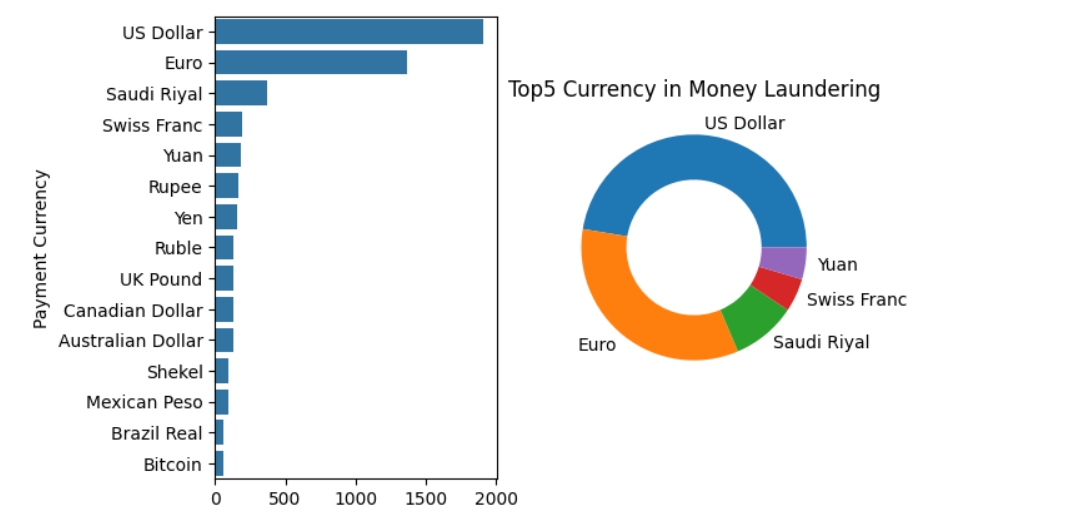
currency=df[df["Is Laundering"]==1]["Payment Currency"].value_counts()
plt.subplot(1,2,1)
#plt.figure(figsize=(5,5))
sns.barplot(y=currency.index,x=currency.values)
plt.subplot(1,2,2)
currency=currency.head()
plt.title("Top5 Currency in Money Laundering")
plt.pie(currency.values,labels=currency.index,wedgeprops=dict(width=0.4));
from_bank=df[df["Is Laundering"]==1]["From Bank"].value_counts().head() sns.barplot(x=from_bank.index,y=from_bank.values) 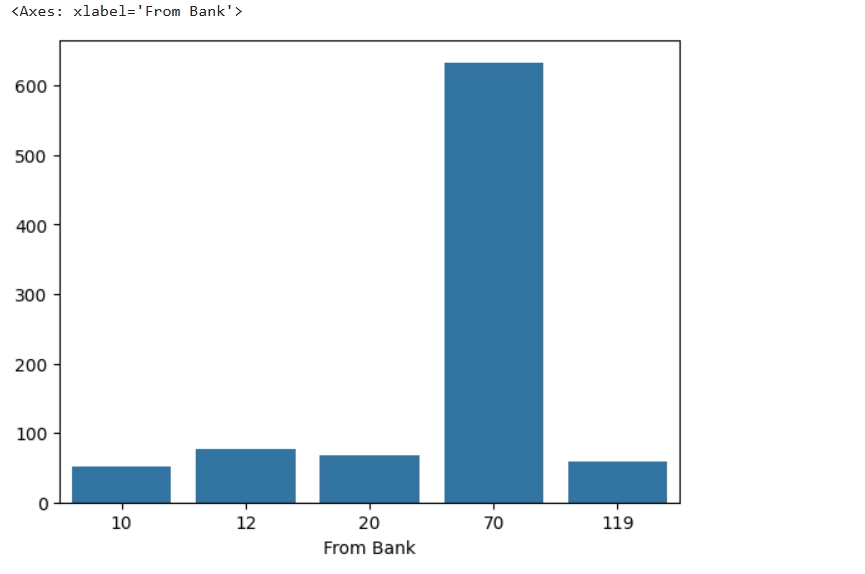
|
cr=df.corr(numeric_only=True) sns.heatmap(cr,annot=True,cmap="Blues") 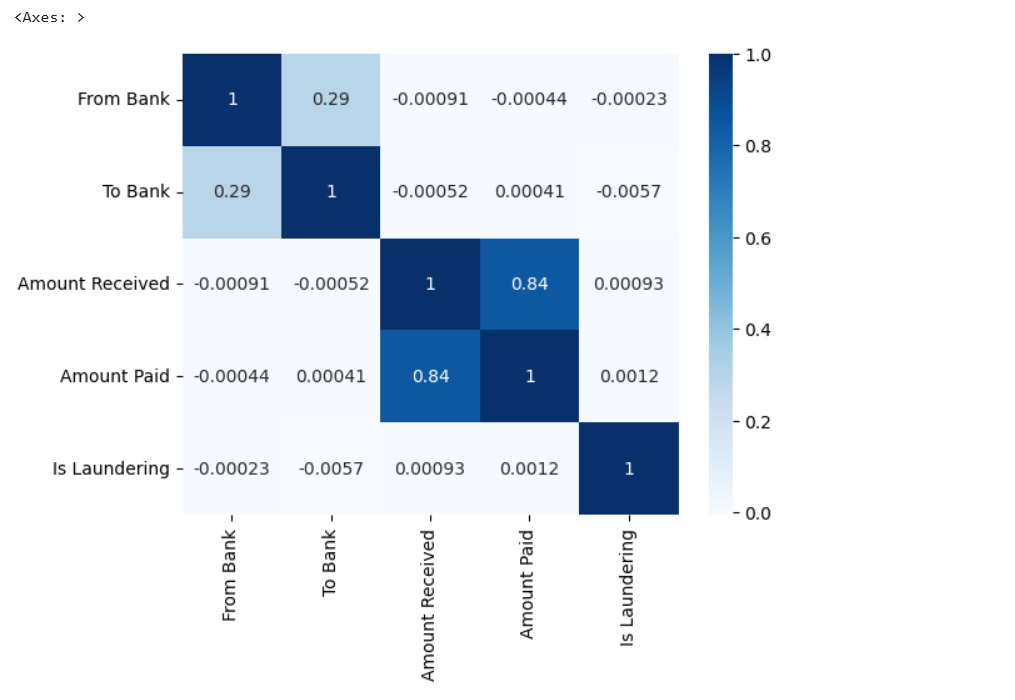
|
import os import time import numpy as np import torch from torch import nn from tpf import pkl_save,pkl_load BASE_DIR = "/wks/datasets/ibm_aml" file_pkl = "ibm_aml_1.pkl" # file_path = os.path.join(BASE_DIR, file_pkl) file_path = file_pkl X_train, X_test, y_train, y_test = pkl_load(file_path=file_path) len(y_test[y_test==1]),len(y_test),len(y_train[y_train==1]),len(X_train) (1087, 1015669, 4090, 4062676) |
|
加载数据集
|
|
|
|
|
|
|
|
编码归一化
|
|
|
|
|
|
|
|
HI-Medium_Trans
2.9G Feb 28 2023 HI-Medium_Trans.csv 454M Feb 28 2023 HI-Small_Trans.csv 文件位置 http://172.26.64.200:8889/lab/workspaces/auto-Y/tree/ibm_medium/21-%E6%95%B0%E6%8D%AE%E5%8A%A0%E8%BD%BD.ipynb
|
|
|
|
|
|
|
|
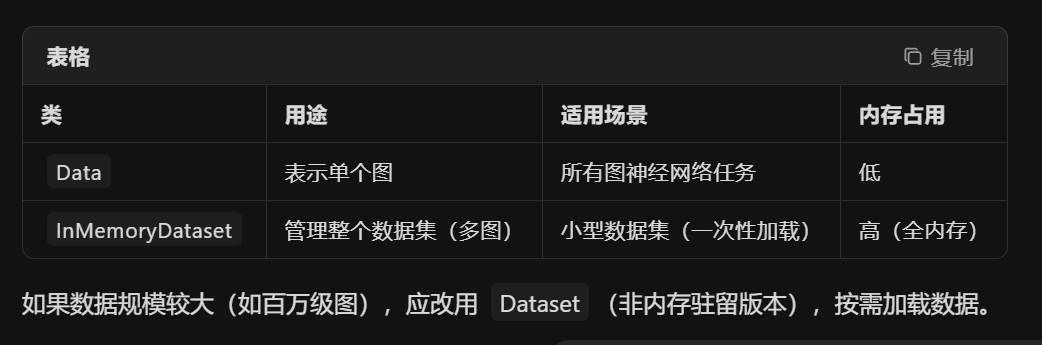
PyG数据集
Data 是 PyG 中用于表示**单个图(graph)**的数据结构,
封装了图的节点、边、节点特征、边特征、标签等信息。
关键属性:
x: 节点特征矩阵,形状为 [num_nodes, num_node_features]。
edge_index:边索引矩阵,形状为 [2, num_edges](COO格式,即每条边的起点和终点)。
edge_attr: 边特征矩阵,形状为 [num_edges, num_edge_features](可选)。
y: 图的标签或节点/边的标签(形状取决于任务,如节点分类、图分类等)。
pos:节点的空间坐标(可选,用于3D点云等任务)。
from torch_geometric.data import Data import torch x = torch.tensor([[1], [2], [3]], dtype=torch.float) # 3个节点,每个节点1维特征 edge_index = torch.tensor([[0, 1, 2], [1, 2, 0]], dtype=torch.long) # 3条边:0→1, 1→2, 2→0 data = Data(x=x, edge_index=edge_index) data # 输出:Data(x=[3, 1], edge_index=[2, 3])
|
InMemoryDataset 是一个抽象基类,用于快速加载中小型数据集到内存中。 它要求将整个数据集一次性预加载到内存(适合如Cora、Citeseer等小规模图数据集)。 核心方法(需子类重写) raw_file_names(): 返回原始数据文件名列表(检查文件是否已下载)。 processed_file_names():返回处理后的数据文件名列表(检查缓存是否存在)。 download(): 下载原始数据到raw_dir目录(可选实现)。 process(): 将原始数据转换为Data对象列表,并保存到processed_dir目录。 基本结构
from torch_geometric.data import InMemoryDataset, Data
import torch
class MyDataset(InMemoryDataset):
def __init__(self, root, transform=None, pre_transform=None):
super().__init__(root, transform, pre_transform)
self.load(self.processed_paths[0]) # 加载处理后的数据到内存
@property
def raw_file_names(self):
return ['data.csv'] # 假设原始数据是CSV文件
@property
def processed_file_names(self):
return ['data.pt'] # 处理后的数据保存为PyTorch文件
def process(self):
# 读取原始数据并生成Data对象列表
data_list = [Data(...), Data(...), ...]
self.save(data_list, self.processed_paths[0])
|
|
代码示例
目录准备
mkdir -p data_tmp/raw/
cp ibm_aml/HI-Small_Trans.csv data_tmp/raw/
import torch
from torch_geometric.data import InMemoryDataset, Data
class MyDataset(InMemoryDataset):
def __init__(self, root, transform=None, pre_transform=None):
super().__init__(root, transform, pre_transform)
self.load(self.processed_paths[0]) # 加载处理后的数据到内存
@property
def raw_file_names(self):
return 'HI-Small_Trans.csv' # 假设原始数据是CSV文件
@property
def processed_file_names(self):
return 'data.pt' # 处理后的数据保存为PyTorch文件
def process(self):
# 读取原始数据并生成Data对象列表
# data_list = [Data(...), Data(...), ...]
x = torch.tensor([[1], [2], [3]], dtype=torch.float) # 3个节点,每个节点1维特征
edge_index = torch.tensor([[0, 1, 2], [1, 2, 0]], dtype=torch.long) # 3条边:0→1, 1→2, 2→0
data = Data(x=x, edge_index=edge_index)
data_list = [data]
print(self.raw_paths)
print(self.processed_paths)
self.save(data_list, self.processed_paths[0])
dataset = MyDataset(root="/wks/datasets/data_tmp")
dataset[0] Data(x=[3, 1], edge_index=[2, 3]) 运行之后,目录的变化 xt@qisan:/wks/datasets/data_tmp$ pwd /wks/datasets/data_tmp xt@qisan:/wks/datasets/data_tmp$ ll total 0 drwxrwxrwx 1 xt xt 512 Jul 21 16:00 ./ drwxrwxrwx 1 xt xt 512 Jul 21 15:58 ../ drwxrwxrwx 1 xt xt 512 Jul 21 16:00 processed/ drwxrwxrwx 1 xt xt 512 Jul 21 16:00 raw/ xt@qisan:/wks/datasets/data_tmp$ ll processed/ total 4 drwxrwxrwx 1 xt xt 512 Jul 21 16:00 ./ drwxrwxrwx 1 xt xt 512 Jul 21 16:00 ../ -rwxrwxrwx 1 xt xt 1496 Jul 21 16:00 data.pt* -rwxrwxrwx 1 xt xt 864 Jul 21 16:00 pre_filter.pt* -rwxrwxrwx 1 xt xt 864 Jul 21 16:00 pre_transform.pt* xt@qisan:/wks/datasets/data_tmp$ ll raw/ total 464516 drwxrwxrwx 1 xt xt 512 Jul 21 16:00 ./ drwxrwxrwx 1 xt xt 512 Jul 21 16:00 ../ -rwxrwxrwx 1 xt xt 475664283 Jul 21 16:00 HI-Small_Trans.csv* print(self.raw_paths) print(self.processed_paths) 只在调试的过程打印出来过,后来重启环境就打印不出来了,它的路径是 ['/wks/datasets/data_tmp/raw/HI-Small_Trans.csv'] ['/wks/datasets/data_tmp/processed/data.pt'] |
|
nMemoryDataset 类(数据集管理) InMemoryDataset 是 PyG 提供的用于加载和预处理图数据集的基类, 适用于可以全部加载到内存中的数据集(如 Cora、Citeseer 等标准数据集)。 核心功能 自动下载和缓存数据(通过 raw_dir 和 processed_dir)。 数据预处理(通过 process() 方法)。 支持索引访问(如 dataset[0] 获取第一张图)。 自定义数据集示例
from torch_geometric.data import InMemoryDataset
class MyDataset(InMemoryDataset):
def __init__(self, root, transform=None):
super().__init__(root, transform)
self.data, self.slices = torch.load(self.processed_paths[0])
@property
def raw_file_names(self):
return ['some_file_1', 'some_file_2'] # 原始数据文件名
@property
def processed_file_names(self):
return ['data.pt'] # 处理后的数据文件名
def download(self):
# 下载原始数据(如果需要)
pass
def process(self):
# 1. 读取原始数据
# 2. 转换为Data对象列表
data_list = [Data(...), Data(...)] # 假设有两个图
# 3. 保存处理后的数据
data, slices = self.collate(data_list)
torch.save((data, slices), self.processed_paths[0])
# 使用数据集
dataset = MyDataset(root='path/to/dataset')
print(dataset[0]) # 访问第一张图

总结 Data: 表示单张图,是 PyG 中的基本数据结构。 InMemoryDataset: 管理多张图的数据集,适合内存可容纳的数据。 通过这两个类,PyTorch Geometric 提供了灵活且高效的图数据处理接口。 如果需要处理大规模图(无法全加载到内存),可以使用 Dataset 代替 InMemoryDataset。 |
|
InMemoryDataset 的工作流程 当你创建数据集实例时,首先会检查处理后的数据文件是否存在(data.pt) 如果文件存在,直接加载(通过 self.load()),不会调用 process() 只有当处理后的文件不存在时,才会调用 process() 来生成数据 删除已存在的处理文件
import os
import torch
from torch_geometric.data import InMemoryDataset, Data
class MyDataset(InMemoryDataset):
def __init__(self, root, transform=None, pre_transform=None):
super().__init__(root, transform, pre_transform)
self.load(self.processed_paths[0])
@property
def raw_file_names(self):
return 'HI-Small_Trans.csv'
@property
def processed_file_names(self):
return 'data.pt'
def process(self):
x = torch.tensor([[1], [2], [3]], dtype=torch.float)
edge_index = torch.tensor([[0, 1, 2], [1, 2, 0]], dtype=torch.long)
data = Data(x=x, edge_index=edge_index)
data_list = [data]
print("Processing data...") # 这会打印出来
print("Raw paths:", self.raw_paths)
print("Processed paths:", self.processed_paths)
self.save(data_list, self.processed_paths[0])
# 确保每次运行都重新处理数据
dataset_root = "/wks/datasets/data_tmp"
if os.path.exists(os.path.join(dataset_root, "processed/data.pt")):
os.remove(os.path.join(dataset_root, "processed/data.pt"))
dataset = MyDataset(root=dataset_root)
强制重新处理 def __init__(self, root, transform=None, pre_transform=None): super().__init__(root, transform, pre_transform) self._process() # 强制处理 self.load(self.processed_paths[0]) |
时间窗口
import pandas as pd
from datetime import date, timedelta
# ---------- 1. 原函数 ----------
def data_time_window(data_path, col_time='DT_TIME',
start_time='2022-09-01', days=10):
df = pd.read_csv(data_path, parse_dates=[col_time])
target_day = pd.to_datetime(start_time).date()
start_day = target_day - timedelta(days=days-1)
return df[(df[col_time].dt.date >= start_day) &
(df[col_time].dt.date <= target_day)]
# ---------- 2. 新增:按固定间隔滚动 ----------
def rolling_windows(data_path, col_time='DT_TIME',
interval=7, win_len=10):
"""
生成器:每次 yield (window_start, window_end, sub_df)
从最早日期开始,每隔 interval 天取一个 win_len 天的窗口
"""
df = pd.read_csv(data_path, parse_dates=[col_time])
date_col = df[col_time].dt.date
min_date = date_col.min()
max_date = date_col.max()
# 当前窗口起点
cur_start = min_date
while cur_start + timedelta(days=win_len-1) <= max_date:
cur_end = cur_start + timedelta(days=win_len-1)
mask = date_col.between(cur_start, cur_end)
yield cur_start, cur_end, df[mask]
cur_start += timedelta(days=interval)
每天取近10天数据
data_path = "/wks/datasets/ibm_aml/bb11_train_ibm_small.csv"
# 1. 取固定窗口
df_win = data_time_window(data_path,
start_time='2022-09-03',
days=7)
# 2. 滚动窗口:每 5 天取一个 7 天窗口
for s, e, sub in rolling_windows(data_path,
interval=1,
win_len=10):
print(f'窗口 {s} ~ {e},记录数 {len(sub)}')
# 这里可以保存 sub 或做后续分析
窗口 2022-09-01 ~ 2022-09-10,记录数 5077237 窗口 2022-09-02 ~ 2022-09-11,记录数 3962712 窗口 2022-09-03 ~ 2022-09-12,记录数 3208544 窗口 2022-09-04 ~ 2022-09-13,记录数 3001346 窗口 2022-09-05 ~ 2022-09-14,记录数 2794037 窗口 2022-09-06 ~ 2022-09-15,记录数 2311433 窗口 2022-09-07 ~ 2022-09-16,记录数 1829390 窗口 2022-09-08 ~ 2022-09-17,记录数 1346662 窗口 2022-09-09 ~ 2022-09-18,记录数 863900 
|
|
|
|
|
|
|
|
参考
神经网络】神经元ReLU、Leaky ReLU、PReLU和RReLU的比较