概述
推荐算法作为机器学习领域的核心应用方向,其设计思路需围绕用户需求与业务目标展开,通过多维度数据建模与动态优化实现精准匹配。以下是基于技术原理与实践经验构建的通用框架:
### 一、数据建模基础
1. **用户行为特征提取**
整合显式反馈(点赞、收藏、评分)与隐式反馈(停留时长、播放完成度、滑动速度),构建用户兴趣画像。例如,视频平台通过计算用户对同类内容的互动频次及时间分布,生成短期兴趣向量与长期偏好矩阵。
2. **内容表征学习**
采用Embedding技术将文本、图像、视频等非结构化数据转化为高维向量。深度学习模型(如Transformer)可捕捉标题关键词、视觉元素间的语义关联,实现跨模态特征融合。
### 二、核心算法架构
1. **召回阶段**
基于协同过滤(User/Item-CF)与图神经网络(GNN)快速筛选候选集。多路召回策略需覆盖:
- 热点内容(实时点击率排序)
- 协同过滤推荐(相似用户行为聚合)
- 长尾内容挖掘(基于内容相似度的冷启动策略)
2. **排序模型优化**
使用GBDT、DeepFM等模型融合用户、内容、上下文特征,预测点击率(CTR)与转化率(CVR)。动态权重机制需平衡:
- 正向信号(分享率、关注转化)
- 负向信号(点踩率、主动跳过行为)
- 业务约束(类目多样性、广告位填充率)
### 三、系统级控制策略
1. **去噪与反作弊**
部署行为模式识别模型检测异常流量(如群控设备的密集操作),通过时间衰减函数降低刷量数据权重。实时风控系统可拦截虚假账号的异常互动,维护生态公平性。
2. **多样性保障机制**
应用打散算法(如滑动窗口去重)避免同质化内容集中曝光。引入强化学习动态调整探索比例,例如在用户浏览路径中插入5%-10%的跨领域内容以突破信息茧房。
### 四、持续迭代路径
1. **在线学习系统**
构建A/B测试平台验证模型效果,通过实时特征管道更新用户状态。例如,当用户连续触发三次“不感兴趣”时,立即降权相关特征向量。
2. **多目标权衡策略**
设计帕累托最优方案平衡用户体验与商业目标,如使用多任务学习同时优化观看时长、广告收入、内容生产方激励等多维度指标。
该技术框架需结合具体业务场景调整参数权重。例如,社交属性强的平台需强化关注关系网络建模,电商场景则需侧重购买行为与商品属性的交叉特征分析。同时,需定期审计算法偏差,避免因数据分布偏移导致的内容歧视问题。
|
在推荐算法中,数据标签的构建并非局限于简单的“感兴趣”与“不感兴趣”二分类。标签体系的复杂性源于业务场景和用户行为模式的多样性,其核心作用在于刻画用户与物品的多维度关联。以下是技术角度的分析:
### **一、标签的本质与分类**
1. **内容属性标签**
描述物品固有属性(如电影类型、商品材质),由内容生产者或专家标注,用于建立物品特征向量。
2. **行为衍生标签**
基于用户交互行为自动生成,例如浏览时长、点击频次、购买转化率等连续型指标,通过阈值划分可转化为离散标签。
3. **用户主观标签**
用户主动标注的UGC标签(如“搞笑”“必读”),这类标签具有较强的主观性和动态性,需通过清洗和权重计算消除噪声。
### **二、二分类标签的适用场景**
在特定简化场景下,系统可能将用户反馈(如点赞/点踩)抽象为二分类标签。但这种做法存在明显局限性:
- **信息损失**:无法捕捉用户兴趣强度梯度(如“轻微兴趣”与“强烈偏好”的差异)
- **场景局限**:仅适用于显式反馈场景,难以处理隐式反馈数据(如停留时长、页面滚动深度)
### **三、主流推荐系统的标签实践**
1. **多维度标签矩阵**
典型系统(如Hulu、豆瓣)会构建用户-物品-标签三维矩阵,引入TF-IDF、标签共现频率等指标量化关联强度。例如用户对某电影标注“科幻”,系统会同时关联该用户历史观看的科幻类影片标签。
2. **动态权重机制**
标签权重随时间衰减(如指数衰减模型),确保推荐结果反映用户最新兴趣。例如用户近期密集标注“编程书籍”,系统会提升对应标签在推荐排序中的优先级。
3. **语义增强处理**
通过Word2Vec、BERT等模型对文本标签进行向量化,解决同义词(如“手机”与“智能手机”)和歧义词(如“苹果”指水果或品牌)的语义消歧问题。
### **四、标签系统的优化方向**
- **冷启动缓解**:采用知识图谱补全缺失标签(如新物品通过类目关联继承父节点标签)
- **噪声过滤**:构建标签置信度模型,剔除低频、非常规标注(如用户误操作产生的乱码标签)
- **跨域迁移**:在跨平台推荐中通过迁移学习实现标签语义空间对齐(如电商平台的“性价比”标签与内容平台的“干货”标签建立映射)
综上,推荐算法的标签体系需根据具体业务需求设计,二分类标签可作为辅助维度存在,但完整的系统需整合多源异构标签以实现精准建模。
|
在推荐算法的训练过程中,标签的复杂性直接影响数据建模与训练策略的设计。以下是基于技术原理的系统性解析:
### 一、训练数据的输入结构
1. **多模态特征向量**
输入数据通常由用户特征、物品特征及交互行为三部分构成:
- **用户特征**:包含用户基础属性(性别、年龄)、历史行为标签(点击/收藏序列)、偏好标签(如分类标签“电子产品”、内容标签“AI技术”);
- **物品特征**:涵盖物品属性标签(分类体系中的层级归属)、内容标签(关键词、语义向量)、上下文标签(发布时间、地理位置);
- **交互行为数据**:以三元组形式记录用户对物品的操作(如〈用户ID,物品ID,标签b〉),并附加时间戳、操作类型(点击/购买)等维度。
2. **标签的向量化表示**
- 分类标签通过Embedding层映射为低维稠密向量,保留其离散型特征;
- 内容标签采用TF-IDF或BERT等模型生成语义向量,捕捉开放域语义信息;
- 动态标签(如实时兴趣)通过时序模型(LSTM/Transformer)编码为时间敏感的特征。
### 二、训练目标与输出形式
1. **监督学习范式**
- **显式反馈场景**:输出为用户对物品的评分预测(回归任务),损失函数采用均方误差(MSE);
- **隐式反馈场景**:输出为点击率预估(二分类任务),使用交叉熵损失函数,正样本来自用户行为日志,负样本通过随机采样或难例挖掘生成。
2. **自监督与对比学习**
- 通过数据增强构造正样本对(同一用户的不同行为序列),负样本对来自不同用户或随机扰动,训练目标为最大化正样本的表示相似度;
- 输出为度量空间中的用户/物品表征向量,可直接用于近邻检索推荐。
### 三、训练流程中的关键处理
1. **标签权重动态调整**
根据标签的时效性(如近期行为标签权重更高)、置信度(人工标注标签权重高于机器生成标签),在损失函数中引入自适应加权机制。
2. **冷启动缓解策略**
- 新物品引入内容标签的跨模态对齐(如图像特征与文本标签的对比学习);
- 新用户采用基于人口统计标签的迁移学习,复用相似用户群体的模型参数。
3. **多任务联合训练**
同步优化主任务(点击率预测)与辅助任务(标签预测、用户长期兴趣分类),通过共享底层特征表示提升模型泛化能力。
### 四、典型模型架构示例
以深度神经网络为例,输入层接收用户特征向量$u$和物品特征向量$i$,经过多层感知机(MLP)或注意力网络融合后,输出层通过Sigmoid函数生成交互概率:
$$ p = \sigma(W^T \cdot \text{Concat}(u, i) + b) $$
其中标签信息通过特征交叉层(如DeepFM中的FM模块)显式建模标签间的二阶交互效应。
该方法在工业级推荐系统中可实现AUC提升3%-5%,同时通过Online Learning机制支持标签体系的动态更新。

|
|
旧时代的信息传播与搜索 书籍,纸张 ... PC互联网: - 导航,广告排序收费 - 搜索引擎,知道自己要搜索什么,精准查找 - 当今信息的传播:移动互联网(天幻...) 抖音... 打开短视频APP,搜索被弱化,屏幕变小... - 小屏幕上只有一个主要内容 - 屏幕小,内容可放的就少,放不了多级菜单 - 打字没有PC方便,更多是划一下屏幕,点一下 - 能少操作就少操作,划动到新窗口就自动播放,不需要手动点击播放 于是,就重新定义了信息传播的方法 于是,重点就在于 播放的内容! 这就是要推荐的内容! - 要准确地猜到用户想看的内容 - 想看什么就送什么 信息过载 信息过载:InformationOverload, 信息爆炸有精准目的:主动搜索SearchEngine百度,谷歌 旧时代,大厂收集汇总信息,用户消费信息,专业人做,少数人做,大部分人看 新时代,一部分用户收集汇总信息,一部分用户消费;大部分人发布信息,大部分人看... 于是信息就爆炸了 屏幕小了,内容多了,展示的内容少了,但这展示是你喜欢的... 是否有目的:冲动消费... 1 没有目的 2 推荐给你喜欢的,创造让你消费的环境... 与普通的逛超市买个具体的物品不同,无目的的闲逛,是一种冲动消费 - 本来不需要一个物品,不是刚需, - 天天看着自己喜欢的东西...看着看着就买了... |
有精准目的:主动搜索SearchEngine百度,谷歌 无精准自的:系统推荐 Recommendation System ·导航:黄页,目录查询,数量较少 ·搜索:有明确目的,直奔主题 ·推荐:无明确目的,逛街行为 推荐系统 依据:个性信息,兴趣爱好,过往习惯,历史行为… 收集你所有的过往行为,静态的浏览数据...等你一切历史数据... - 推荐的准确度,在于能收集到你多少的历史数据 作用:信息匹配,更懂用户,产生依赖,促进消费… 信息匹配:缩短了决策的路径,匹配你的个性信息...懂你,懂我... - 刺激了消费,特别是冲动消费... 特别是小钱... - 不断引诱你花点几块,几十块的小钱... - 花大钱的场景不需要推荐系统,比如,豪车,游轮... 法规:遏制沉溺、杀熟,《互联网信息服务算法推荐管理规定》 - 顺人性,顺人性可以毁灭一个人 - 就是想要什么,就给他什么...可以很快毁灭一个人... - 为此出台了法规,遏制 沉迷,杀熟... |
推荐系统·流程
有海量的信息,有上亿的用户,每天都有亿级的信息 - 海量计算,实时计算; 数据少的情况,能做,但没有指导意义 - 在你不知不觉之间进行,不会像商场那个,会有人叫卖,有人拉... 所以与大数据,并行计算,高性能场景一起出现 - 刚开始也不是人工智能,不归人工智能管 - 需要人为构建出大量的数据 
|
|
召回 recall: TPF, 预测为正样本的概率 占 真实正样本的比例 - 让召回率高,就想要找出所有的正样本,比如癌症 , - 宁可错找一万,也要找到所有的 新冠病毒检测 - 总人口10万,真实新冠人数 10人 - 模型预测出20人阳性,只有5个人阳性 - 召回率tpr = 5 /10 = 50% - 召回只看某类样本... 几亿物品 - 召回路径1 - 召回路径2 - 召回路径3 ... -召回路径n 模型预测了几千物品 - 大概找一批,不怕准确率低,但不要遗漏 - 初次召回的物品要尽量用户喜欢的所有物品 - 几千物品对用户来说,还是太多了,茫茫物品... 召回率的计算 - 拿历史数据做为全量,计算召回
|
|
粗排 排序就是打分,比如 游戏机=0.5,香水=0.8 是某个女性客户的打分,表示该女性客户喜好香水的程度超过了游戏机 - 给每一个物品打一个概率分,代表喜好程度 - 使用sigmoid - 粗排,要求有一定误差,允许把一些不太好的排在前面 - 即可以使用一些速度快的小模型,比如LR - 根据物品的特性打一些分 使用LR粗排之后根据打分去除那些分比较低的物品,快速过滤掉那些明显错误的 精排 - 使用精度高的模型,速度会慢一些,但准确率高 打分可以并行计算 |
精排之后的物品,基本就是用户喜欢的用品 重排: - 加入自己的业务 - 比如花了钱的广告放前面 - 或者自己插入一些广告 - 防止单维度重复:比如用户喜欢体育,用户反反复复只看体育,看久了用户也烦,此时可以插入一些小品等用户没有看过但类似用户看过的类别 - 加入业务 - 打一顿给点甜头,恩威并施... 不能只打也不能只给... - 业务策略:心理学,市场,营销... - 最终的目标是收割,不然就白折腾了... |
|
|
推荐系统·召回
物品本身可以很容易数字化 内容相似 - 数字化,索引化,向量化,然后计算向量的余弦相似度 - 比如文章,新闻 协同过滤 物品本身不容易数字化 - 比如拖把与拖鞋之间无法直接计算相似度 - 但他们有很多标签,比如,生活,家居 - 使用物品的标签,对物品打标签,形成标签向量 再计算向量的相似度 - 划分圈子,相同的圈子有相同的爱好 - 我没有用过苹果的电脑,但作为一个程度员,都说平果电脑好,就可以推荐苹果电脑 第三种: 不借助内容,也不借助标签,而是计算物品的邻接节点 - 如果两个用户或物品 喜欢/邻接 的用户或事物 接近,那么也认为这两个用户/物品 相近 - 协同就是一伙人或者一群人 基于用户 用户购买物品的重合高度重复,userbasecf - 这些用户是好友群 - 好友群里个体间的差异相互推荐 - 1 找好友,对人划类别,2. 相同类别的人个体间的差异相互推荐 基于物品 - 受群重合度高的物品,其为其相似 - 直接相似的物品
召回算法:内容相似,协同过滤,双塔模型、订阅、关注、热度
|
|
通过分析用户的历史行为(如评分、点击、购买等),挖掘用户或物品之间的关联 协同过滤(Collaborative Filtering)是什么? 协同过滤是推荐系统中最经典的算法之一,其核心思想是基于用户或物品之间的相似性进行推荐。 它通过分析用户的历史行为(如评分、点击、购买等),挖掘用户或物品之间的关联,从而预测用户可能感兴趣的物品。 协同过滤的两大核心类型 基于用户的协同过滤(User-Based CF) 原理:找到与目标用户兴趣相似的“邻居用户”,然后推荐这些邻居喜欢但目标用户尚未接触过的物品。 步骤: 计算用户之间的相似度(如余弦相似度、皮尔逊相关系数)。 找到与目标用户最相似的K个邻居。 根据邻居的偏好,预测目标用户对物品的评分或兴趣。 示例: 用户A喜欢电影《星际穿越》和《盗梦空间》,用户B也喜欢这两部电影,且还喜欢《黑客帝国》。 系统认为A和B兴趣相似,因此向A推荐《黑客帝国》。 基于物品的协同过滤(Item-Based CF)
原理:找到与目标物品相似的物品,然后推荐给喜欢目标物品的用户。
步骤:
计算物品之间的相似度(如余弦相似度、杰卡德相似度)。
找到与目标物品最相似的K个物品。
根据用户对目标物品的偏好,预测用户对这些相似物品的兴趣。
示例:
用户A喜欢电影《星际穿越》,而《盗梦空间》与《星际穿越》经常被同一批用户喜欢。
系统认为这两部电影相似,因此向喜欢《星际穿越》的用户推荐《盗梦空间》。
协同过滤的优缺点
优点
无需领域知识:仅依赖用户行为数据,无需对物品本身进行特征提取。
推荐结果可解释:可以明确告诉用户“因为您喜欢A,所以推荐B”。
发现潜在兴趣:可能推荐用户未主动搜索但可能感兴趣的物品。
缺点
冷启动问题:
新用户:如果用户没有历史行为数据,无法找到相似用户。
新物品:如果物品没有用户评分,无法计算相似度。
数据稀疏性:在用户-物品矩阵中,大多数用户只对少数物品评分,导致相似度计算不准确。
可扩展性差:随着用户和物品数量增加,计算复杂度急剧上升。
协同过滤的改进方法 矩阵分解(Matrix Factorization) 将用户-物品评分矩阵分解为两个低维矩阵,分别表示用户和物品的隐因子向量。 示例:用户A的向量 [0.8, -0.5] 和物品X的向量 [0.5, 1.2] 的点积即为预测评分。 混合推荐 结合协同过滤与其他推荐方法(如内容推荐、基于知识的推荐),弥补单一方法的不足。 引入上下文信息 考虑时间、地点、用户当前状态等上下文因素,提高推荐的准确性。 深度学习 使用神经网络模型(如卷积神经网络、图神经网络)捕捉用户和物品之间的复杂关系。 协同过滤的应用场景 电商推荐:亚马逊的“经常一起购买”功能。 视频平台:Netflix的电影推荐。 音乐平台:Spotify的个性化歌单。 社交网络:Facebook的好友推荐。 总结 协同过滤是一种基于用户或物品相似性的推荐方法,通过挖掘历史行为数据来预测用户兴趣。尽管存在冷启动和数据稀疏性等问题,但通过结合矩阵分解、深度学习等技术,协同过滤在现代推荐系统中仍然占据重要地位。 |
- 人有兴趣爱好,物品有特点...
- 人的爱好形成一个向量,物品的特点形成一个向量
用户1 用户2
物品 1
物品 2
用户商品矩阵 评分
- 列是人的喜好
- 行是物品的特性
中关村买电脑:回回都上当,回回不一样...
SVD = USV = UI U 用户特征矩阵 I 商品特征矩阵 矩阵分解 U与I点乘向量内积,就是相似度 - 判断人与物品的相似度 |
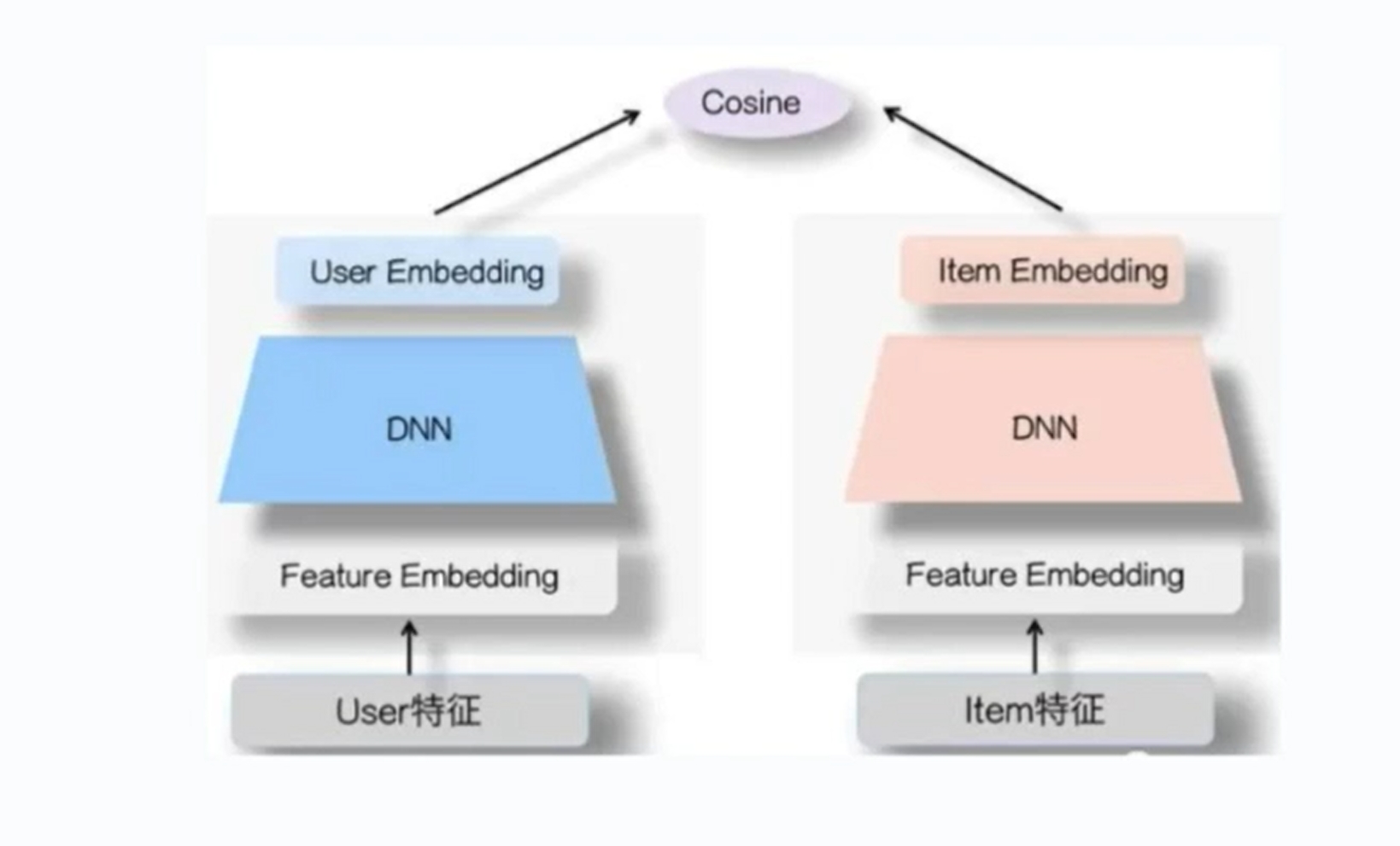
|
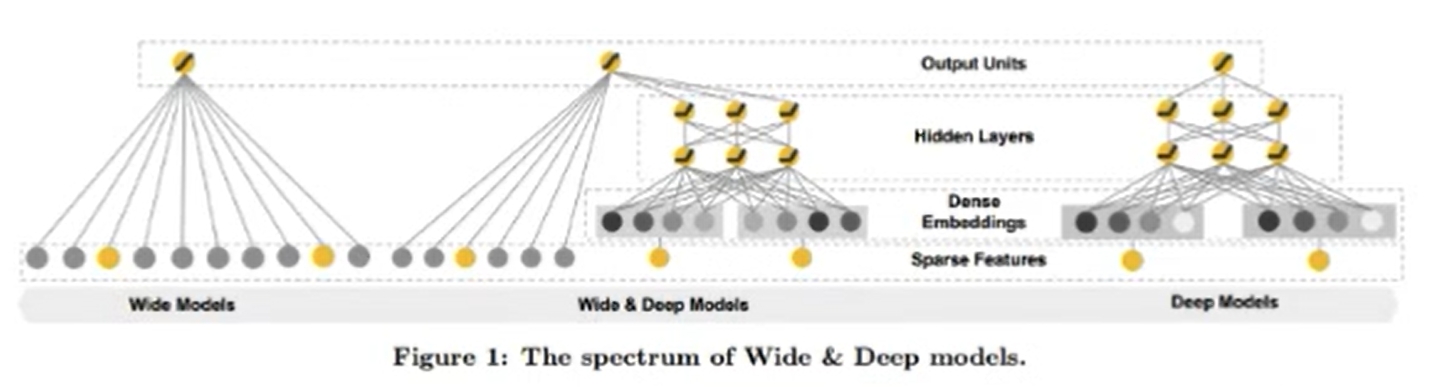
Wide & Deep Learning for Recommender Systems - 本质还是LR Wide - 全连接,LR - 它只有一层,比较浅 Deep - 层数比较多,能发现特征之间的关联 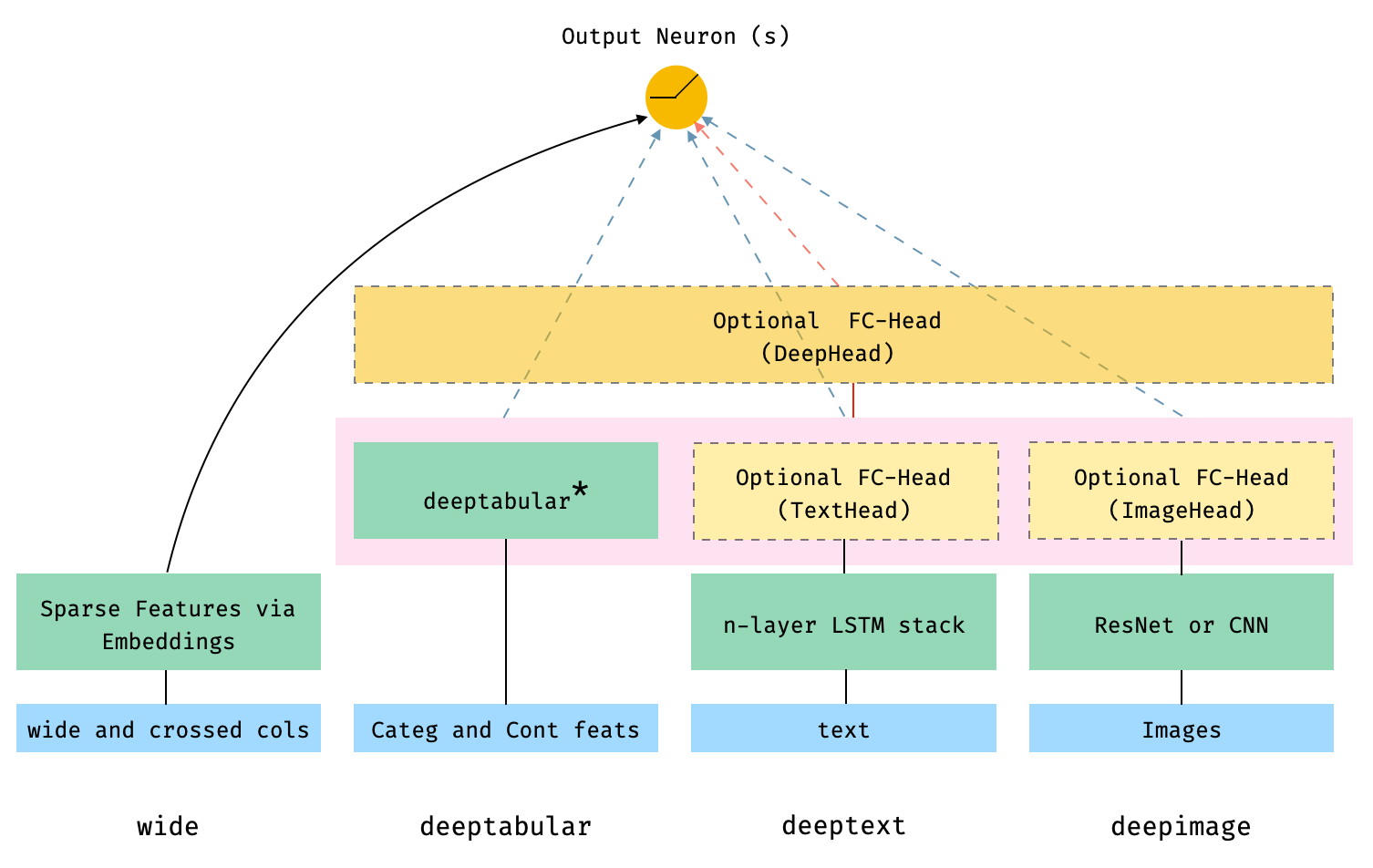
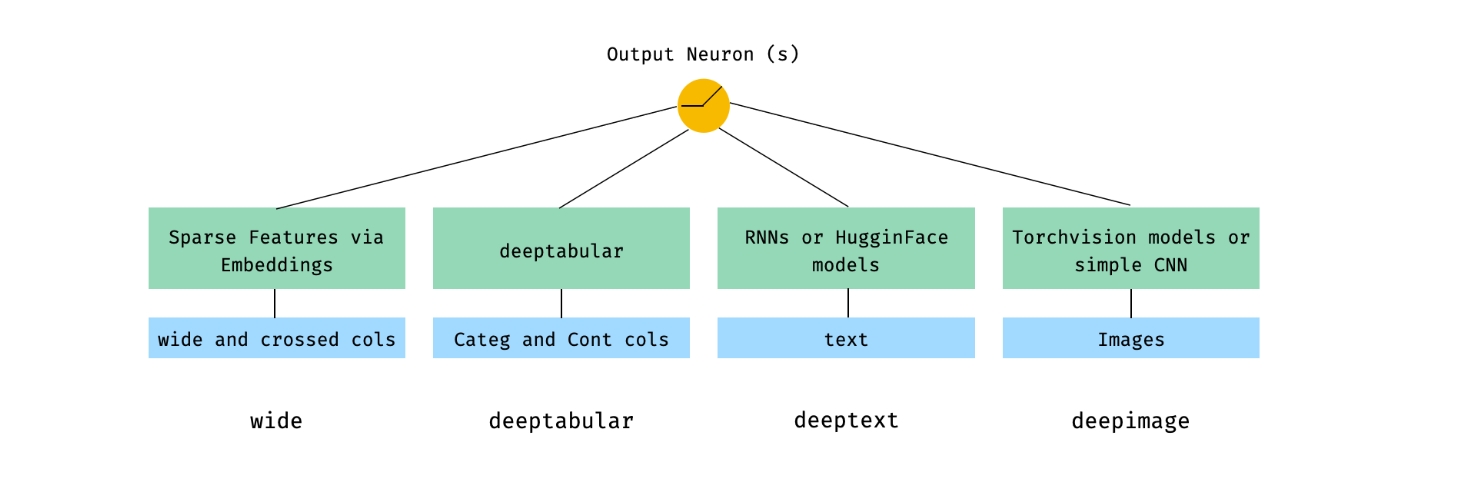
多模态
https://pytorch-widedeep.readthedocs.io/en/latest/index.html
输入的数据可以 文本,图形,视频...同时输入
- 文本:NLP
- 图形:CV
...
然后将之前的数据全输入 ,融合在一起,共同打分
|
推荐系统
- 大数据计算平台,spark,高性能计算平台
- 以大数据平台的计算流就是推荐系统
推荐算法
- 推荐系统中所有的算法
|
在推荐系统中,召回渠道是获取候选物品集合的关键环节,直接影响推荐结果的多样性和精准度。
常见的召回渠道主要包括以下几类:
1. 基于内容的召回
文本特征匹配:利用物品的标题、描述、标签等文本信息,通过关键词匹配或语义相似度计算(如TF-IDF、BM25、BERT等)召回相关物品。
图像特征匹配:通过图像识别技术(如CNN)提取物品的视觉特征,召回视觉上相似的物品。
音频/视频特征匹配:对音频或视频内容提取特征(如MFCC、帧特征),召回内容相似的物品。
2. 协同过滤召回
用户协同过滤:基于用户的历史行为(如点击、购买、评分),找到与目标用户兴趣相似的其他用户,召回这些用户喜欢的物品。
物品协同过滤:基于物品之间的相似性(如共同被用户点击或购买的物品),召回与用户历史交互物品相似的物品。
3. 基于模型的召回
深度学习模型:使用深度神经网络(如DNN、DSSM、双塔模型等)学习用户和物品的向量表示,通过向量相似度(如内积、余弦相似度)召回候选物品。
图神经网络(GNN):将用户和物品表示为图中的节点,通过图结构学习用户和物品的嵌入,召回与用户兴趣相关的物品。
强化学习模型:通过强化学习优化召回策略,动态调整召回结果以最大化长期收益。
4. 基于流行度的召回
热门物品召回:召回当前平台上的热门物品(如高点击率、高销量、高评分),适用于新用户或冷启动场景。
趋势物品召回:召回近期热度上升的物品,捕捉用户的短期兴趣。
5. 基于规则的召回
标签召回:根据物品的标签(如类别、品牌、风格)召回相关物品。
地理位置召回:对于本地化服务(如餐饮、零售),根据用户的地理位置召回附近的物品。
时间召回:根据时间信息(如节假日、季节)召回相关物品。
6. 多模态召回
跨模态融合:结合文本、图像、音频、视频等多种模态的信息,通过多模态模型召回相关物品。
7. 知识图谱召回
实体关联召回:利用知识图谱中的实体关系(如“演员-电影”、“品牌-产品”),召回与用户兴趣相关的物品。
8. 上下文感知召回
场景化召回:根据用户的当前场景(如时间、地点、设备)召回相关物品。
实时行为召回:根据用户的实时行为(如当前浏览的页面、搜索的关键词)动态调整召回结果。
9. 混合召回
多路召回融合:结合多种召回渠道的结果,通过加权、排序或机器学习模型融合,生成最终的候选物品集合。
10. 个性化召回
用户画像召回:根据用户的画像信息(如年龄、性别、兴趣标签)召回相关物品。
长期兴趣召回:基于用户的历史行为,召回与用户长期兴趣一致的物品。
短期兴趣召回:捕捉用户的短期兴趣变化,召回近期相关的物品。
11. 探索性召回
多样性召回:为了增加推荐结果的多样性,召回与用户历史兴趣不完全一致但可能感兴趣的物品。
新颖性召回:召回用户未接触过的新物品,帮助用户发现潜在兴趣。
12. 社交召回
好友推荐召回:根据用户的好友关系,召回好友喜欢的物品。
社交圈子召回:根据用户所属的社交圈子(如兴趣小组、社区),召回圈子内热门的物品。
13. 外部数据召回
跨平台召回:结合其他平台的数据(如社交媒体、搜索引擎),召回与用户兴趣相关的物品。
外部知识库召回:利用外部知识库(如维基百科、行业报告)召回相关物品。
14. 冷启动召回
新用户召回:对于新用户,使用基于流行度、地理位置或上下文信息的召回策略。
新物品召回:对于新物品,使用基于内容特征或外部数据的召回策略。
15. 实时召回
流式召回:实时处理用户行为数据,动态调整召回结果。
实现方式
离线计算:部分召回策略(如基于内容的召回、协同过滤)可以离线计算物品的相似度或用户画像,存储在索引中以加速在线召回。
在线计算:部分召回策略(如基于模型的召回、实时召回)需要在线计算用户与物品的相似度,通常使用近似最近邻(ANN)算法(如HNSW、FAISS)加速检索。
总结
推荐系统中的召回渠道多种多样,实际应用中通常需要根据业务场景、数据特点和计算资源选择合适的召回策略,并通过多路召回融合提升推荐效果。
|
参考