import numpy as np
import torch
import torch.nn as nn
from sklearn.preprocessing import StandardScaler
from torch.utils.data import DataLoader, TensorDataset
# 数据加载与预处理
def load_data(file_path, seq_length=30, split_ratio=0.8):
data = np.loadtxt(file_path) # 形状: (时间步, 特征维度)
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
# 构建滑动窗口序列
sequences, targets = [], []
for i in range(len(scaled_data) - seq_length):
seq = scaled_data[i:i+seq_length]
label = scaled_data[i+seq_length, 0] # 预测第一维特征的下一个时间点
sequences.append(seq)
targets.append(label)
# 划分训练集与验证集
split_idx = int(len(sequences) * split_ratio)
train_data = torch.FloatTensor(sequences[:split_idx])
train_labels = torch.FloatTensor(targets[:split_idx])
val_data = torch.FloatTensor(sequences[split_idx:])
val_labels = torch.FloatTensor(targets[split_idx:])
return DataLoader(TensorDataset(train_data, train_labels), batch_size=64, shuffle=True), \
DataLoader(TensorDataset(val_data, val_labels), batch_size=64)
# LSTM模型定义
class LSTMPredictor(nn.Module):
def __init__(self, input_size=38, hidden_size=64, output_size=1):
super().__init__()
self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, _ = self.lstm(x) # out形状: (batch, seq_len, hidden_size)
return self.fc(out[:, -1, :]) # 取最后一个时间步输出
# 训练流程
def train_model(train_loader, val_loader, epochs=50):
model = LSTMPredictor()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
for epoch in range(epochs):
model.train()
for X, y in train_loader:
optimizer.zero_grad()
outputs = model(X)
loss = criterion(outputs.squeeze(), y)
loss.backward()
optimizer.step()
# 验证阶段
model.eval()
val_loss = 0
with torch.no_grad():
for X_val, y_val in val_loader:
preds = model(X_val)
val_loss += criterion(preds.squeeze(), y_val).item()
print(f"Epoch {epoch+1}, Val Loss: {val_loss/len(val_loader):.4f}")
return model
# 示例调用
if __name__ == "__main__":
train_loader, val_loader = load_data("machine-1-1_train.txt")
model = train_model(train_loader, val_loader)
|
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
from sklearn.preprocessing import MinMaxScaler
# 生成模拟时序数据
def generate_time_series(start_date, num_steps, freq='D'):
timestamp = pd.date_range(start=start_date, periods=num_steps, freq=freq)
trend = np.linspace(0, 5, num_steps)
seasonality = 10 * np.sin(np.linspace(0, 10*np.pi, num_steps))
noise = np.random.normal(0, 1, num_steps)
value = trend + seasonality + noise
return pd.DataFrame({
'timestamp': timestamp,
'value': value.astype(np.float32),
'feature1': np.random.uniform(0, 10, num_steps), # 附加随机特征
'feature2': np.random.randint(0, 5, num_steps)
}).set_index('timestamp')
# 参数配置
SEQ_LENGTH = 7 # 滑动窗口长度
BATCH_SIZE = 16
HIDDEN_SIZE = 32
EPOCHS = 50
# 生成数据
df = generate_time_series('2025-01-01', 100)
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(df.values)
# 构建训练集
def create_sequences(data, seq_length):
sequences = []
targets = []
for i in range(len(data)-seq_length):
sequences.append(data[i:i+seq_length])
targets.append(data[i+seq_length, 0]) # 预测主特征
return torch.FloatTensor(sequences), torch.FloatTensor(targets)
X, y = create_sequences(scaled_data, SEQ_LENGTH)
train_size = int(0.8 * len(X))
train_X, test_X = X[:train_size], X[train_size:]
train_y, test_y = y[:train_size], y[train_size:]
# 定义RNN模型
class TimeSeriesRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, _ = self.rnn(x)
return self.fc(out[:, -1, :])
model = TimeSeriesRNN(input_size=3, hidden_size=HIDDEN_SIZE, output_size=1)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters())
# 训练过程
for epoch in range(EPOCHS):
model.train()
outputs = model(train_X)
loss = criterion(outputs.squeeze(), train_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch+1) % 10 == 0:
print(f'Epoch {epoch+1}, Loss: {loss.item():.4f}')
# 预测演示
model.eval()
with torch.no_grad():
test_pred = model(test_X).numpy()
test_actual = test_y.numpy()
# 可视化对比(需matplotlib)
import matplotlib.pyplot as plt
plt.plot(test_actual, label='Actual')
plt.plot(test_pred, label='Predicted')
plt.legend()
plt.show()
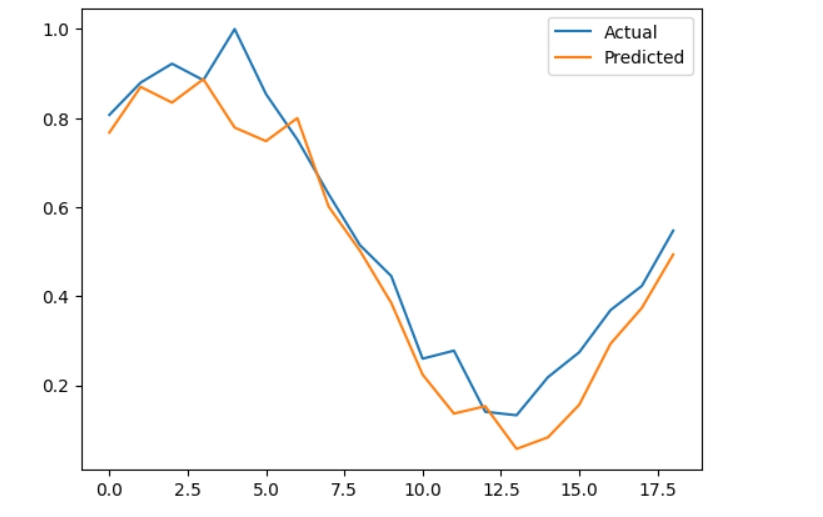
单变量时序特征
- 这里实际上只有一个变量,另外一个变量是随机噪声
- 预测就是取这个真实数据变量的下一个值作为label
-
|
y1 y2 y3 y4 y5 y6 y7 y8
0 0 0 0 0 1 0 0
x1 x2 x3 x4 x5 x6 x7 x8
对于异常检测来说,可以增加一个维度,就是标签的维度,这样就可以按这种方式进行预测了
但这并不合适
- 这种方式生成是的,或者说学习的是序列本身的规律,并不学习异常的规律
- 异常数据比例千分之一不到,在深度学习中被自动冲消...
可以拆解为两个模型
- 一个模型为生成模型预测正常序列,学习客户正常行为模式
- 一个模型学习上一个模型预测结果与标签之间的差异,
- 0-标记为正常,1-异常
- 差异小就是正常,差异大就是异常
y1 y2 y3 y4 y5 y6 y7 y8
0 0 0 0 0 1 0 0
x1 x2 x3 x4 x5 x6 x7 x8
还有另外一种思路,就是直接的序列[x1,x2,...,xi,...,xn] -- [y1,y2,...,yi,...,yn]
- [batch_size,seq_len,embedding_dim]
|
- [batch_size,seq_len,m]
|
- [batch_size,seq_len,n]
|
- [batch_size,seq_len,1]
变换的是embedding_dim维度,但在变换的过程中,却是从多个维度进行学习
- 自身维度
- 整句话的维度
- y6之所以为1是因为自身的信息与整个序列的信息不符所导致的
- 这就要有自身信息
- 还有自身相对于整个序列的信息
|