按列值分组
|
统计相同卡号下最大交易号
a[["卡号","交易ID"]].groupby("卡号").max()
|
|
求sum要先判断其为数字,若为字符串,pandas会直接将其拼接,而不是报错
import pandas as pd
# 假设你有以下的DataFrame
data = {
'交易号': ['T001', 'T002', 'T003', 'T004', 'T005', 'T006'],
'卡号': ['C001', 'C002', 'C001', 'C003', 'C002', 'C001'],
'金额': [100, 200, 150, 300, 250, 120]
}
df = pd.DataFrame(data)
# 按卡号分组,并计算交易笔数和总金额
grouped = df.groupby('卡号').agg({'交易号': 'size', '金额': 'sum'}).reset_index()
# 将列名更改为更直观的名称
grouped.columns = ['卡号', '交易笔数', '总金额']
print(grouped)
卡号 交易笔数 总金额
0 C001 3 370
1 C002 2 450
2 C003 1 300
|
import pandas as pd
# 示例数据
data = {
'交易号': ['T1', 'T2', 'T3', 'T4', 'T5','T6'],
'卡号': ['C1', 'C1', 'C2', 'C2', 'C3','C3'],
'商户1': ['M1', 'M1', 'M2', 'M2', 'M1','M1'],
'商户2': ['S1', 'S2', 'S1', 'S2', 'S1','S1'],
'金额': [100, 200, 300, 400, 500,500]
}
df = pd.DataFrame(data)
print(df)
交易号 卡号 商户1 商户2 金额 0 T1 C1 M1 S1 100 1 T2 C1 M1 S2 200 2 T3 C2 M2 S1 300 3 T4 C2 M2 S2 400 4 T5 C3 M1 S1 500 5 T6 C3 M1 S1 500
# 首先,我们按'商户1'和'商户2'以及'卡号'进行分组
grouped = df.groupby(['卡号', '商户1', '商户2'])
# 接着,我们计算每个组的交易笔数('size')和交易金额的总和('金额'的'sum')
# 注意:'size'是pandas分组对象的一个默认方法,用于计算每个组的行数
result = grouped.agg({'交易号': 'size', '金额': 'sum'}).reset_index()
# 如果需要,可以将'交易号'列的名称更改为'交易笔数'以使其更清晰
result = result.rename(columns={'交易号': '交易笔数'})
result
卡号 商户1 商户2 交易笔数 金额 0 C1 M1 S1 1 100 1 C1 M1 S2 1 200 2 C2 M2 S1 1 300 3 C2 M2 S2 1 400 4 C3 M1 S1 2 1000 |
|
|
|
|
groupby
import pandas as pd
import numpy as np
# 示例数据
data = {
'指标编码': [1, 2, 3, 4, 5, 6],
'类别': ['基础', '衍生', '基础', '衍生', '基础', '衍生'],
'特征算法名': ['alg1', np.nan, 'alg3', np.nan, 'alg5', 'alg6']
}
df = pd.DataFrame(data)
df
指标编码 类别 特征算法名
0 1 基础 alg1
1 2 衍生 NaN
2 3 基础 alg3
3 4 衍生 NaN
4 5 基础 alg5
5 6 衍生 alg6
count:不包含空值的个数
# 使用 groupby 和 agg 进行统计
result = df.groupby('类别')['特征算法名'].agg(
总个数='count',
非空个数=lambda x: x.notna().sum(),
空值个数=lambda x: x.isna().sum()
).reset_index()
print(result)
类别 总个数 非空个数 空值个数
0 基础 3 3 0
1 衍生 1 1 2
size:包含空值的个数
import pandas as pd
import numpy as np
# 示例数据
data = {
'指标编码': [1, 2, 3, 4, 5, 6],
'类别': ['基础', '衍生', '基础', '衍生', '基础', '衍生'],
'特征算法名': ['alg1', np.nan, 'alg3', np.nan, 'alg5', 'alg6']
}
df = pd.DataFrame(data)
# 使用 groupby 和 agg 进行统计
result = df.groupby('类别')['特征算法名'].agg(
总个数='size', # 使用 size 计算总行数,包括 NaN
非空个数=lambda x: x.notna().sum(),
空值个数=lambda x: x.isna().sum()
).reset_index()
print(result)
上面的代码并不会统计类别为空的情况,可进行以下处理
import pandas as pd
import numpy as np
# 示例数据
data = {
'指标编码': [1, 2, 3, 4, 5, 6],
'类别': ['基础', '衍生', np.nan, '衍生', '基础', np.nan],
'特征算法名': ['alg1', np.nan, 'alg3', np.nan, 'alg5', 'alg6']
}
df = pd.DataFrame(data)
# 将类别列中的空值替换为“类别空值”
df['类别'] = df['类别'].fillna('未分类')
# 使用 groupby 和 agg 进行统计
result = df.groupby('类别')['特征算法名'].agg(
总个数='size', # 使用 size 计算总行数,包括 NaN
非空个数=lambda x: x.notna().sum(),
空值个数=lambda x: x.isna().sum()
).reset_index()
print(result)
类别 总个数 非空个数 空值个数
0 基础 2 2 0
1 未分类 2 2 0
2 衍生 2 0 2
|
使用 include_groups=False
而使用 include_groups=False,则 "PARTY_ID" 列不会被包含在内,
因此你的 .apply() 函数无法直接访问 "PARTY_ID" 列(除非你在函数内部特别处理)。
def example_apply_without_group_key(group):
# 注意这里没有访问 'PARTY_ID' 列,因为我们设置了 include_groups=False
return group['value'].sum()
result = df.groupby("PARTY_ID", include_groups=False).apply(example_apply_without_group_key).reset_index()
|
y_label_stats = df.groupby('label').agg(
count=('mismatch', 'sum'),
y_label_count=('label', 'size')
).reset_index()
df = df.merge(y_label_stats, on='label', how='left')
df[:3]
会生成两列y_label_count,count - count是mismatch按label sum - y_label_count是label size |
```
df['mean_reranked_score'] = df.groupby('real_label')['reranked_score'].transform('mean')
df['mean_ms_score'] = df.groupby('real_label')['ms_score'].transform('mean')
```
|
|
|
连续分组
import pandas as pd
# 示例数据
df = pd.DataFrame({
'date_diff': [0, 1, 1, 0, 1, 3, 0,1,1,2,1],
'lianxu_day': [0, 1, 1, 1, 1, 0, 1,1,1,0,1]
})
# Step 1: 标记每次清零的位置作为新的组标志
# 每当 lianxu_day == 0 时,表示一个新组开始
groups = (df['lianxu_day'] == 0).cumsum()
df['lianxu'] = df.groupby(groups)['lianxu_day'].cumsum()
print(df)
date_diff lianxu_day lianxu
0 0 0 0
1 1 1 1
2 1 1 2
3 0 1 3
4 1 1 4
5 3 0 0
6 0 1 1
7 1 1 2
8 1 1 3
9 2 0 0
10 1 1 1
|
group = df[df["PARTY_ID"]=="PARTY009"].sort_values(by="TSTM")
group["date_diff"] = group["TSTM"].diff().dt.days.fillna(0).astype(int)
group["lianxu_day"] = group["date_diff"].apply(lambda x: 1 if x in [0, 1] else 0)
# 创建分组标记
groups = (group['lianxu_day'] == 0).cumsum()
# 自定义函数:仅累加 date_diff == 1 的行
def custom_cumsum(x):
cnt = 0
result = []
for val in x['date_diff']:
if val == 1:
cnt += 1
result.append(cnt)
result = np.array(result)+1
return pd.Series(result, index=x.index)
# 应用分组和自定义累加
group['consecutive'] = group.groupby(groups, group_keys=False).apply(custom_cumsum)
group[["TSTM", "date_diff","lianxu_day","consecutive"]]
TSTM date_diff lianxu_day consecutive
5 2022-06-01 0 1 1
60 2022-06-02 1 1 2
69 2022-06-02 0 1 2
2 2022-06-03 1 1 3
4 2022-06-03 0 1 3
98 2022-06-03 0 1 3
46 2022-06-05 2 0 1
43 2022-06-06 1 1 2
80 2022-06-07 1 1 3
50 2022-06-08 1 1 4
33 2022-06-09 1 1 5
38 2022-06-09 0 1 5
|
|
|
|
|
|
|
分组结果为新列
按某列分组,然后取均值
然后分组后的个数会比原来的数据行数少,因为会存在合并的数据
import pandas as pd
df = pd.read_csv("/wks/datasets/demo_data/.csv")
df
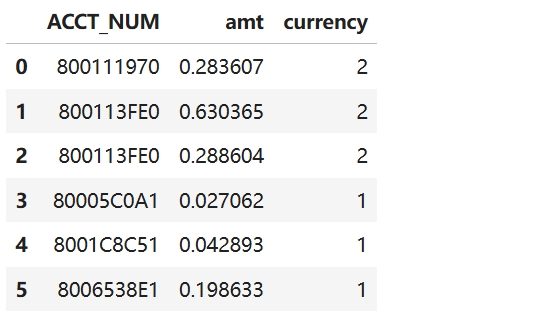
temp =df[df["currency"] == 2]
tmp1 = temp["amt"].groupby(temp["ACCT_NUM"]).transform('mean')
df["a1_mean"] = tmp1
df
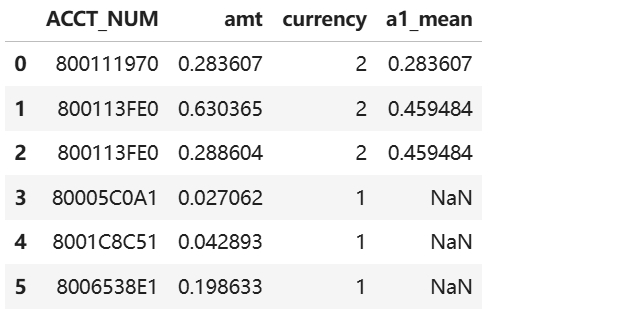
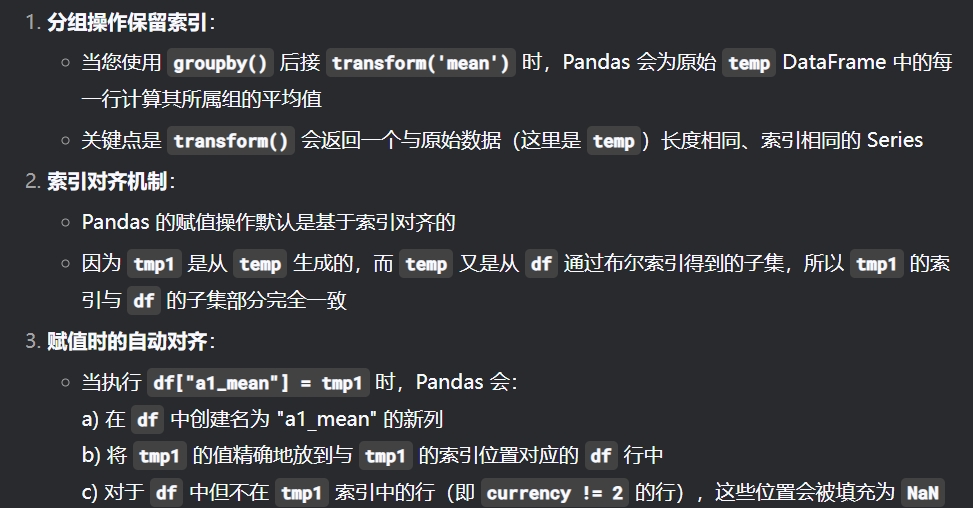
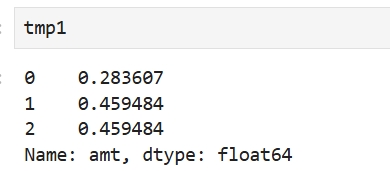
temp分组后返回的是与temp同个数的序列
tmp1 = temp["amt"].groupby(temp["ACCT_NUM"]).transform('mean')
tmp1
temp有三行,tmp1返回的就有三行,其中两行完全一样
并且tmp1的索引与temp完全一致,而temp的索引与df完全一致,
所以tmp1的列全合并后df上时会按索引进行合并
|
|
如果重置索引,或者是两个不同的数表,按索引匹配就会出现错误的结果
acc2 = df[1:]
acc2 = acc2.reset_index()
acc2["bad_index"] = tmp1
acc2
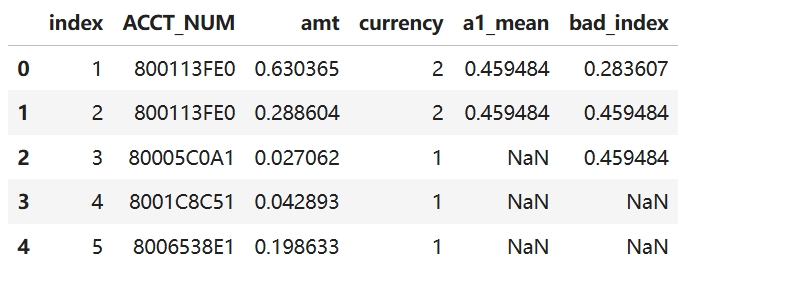
按分组键合并
avg_values = temp.groupby(temp["ACCT_NUM"])["amt"].mean()
acc2['avg received '+str(1)] = acc2["ACCT_NUM"].map(avg_values).fillna(0)
acc2
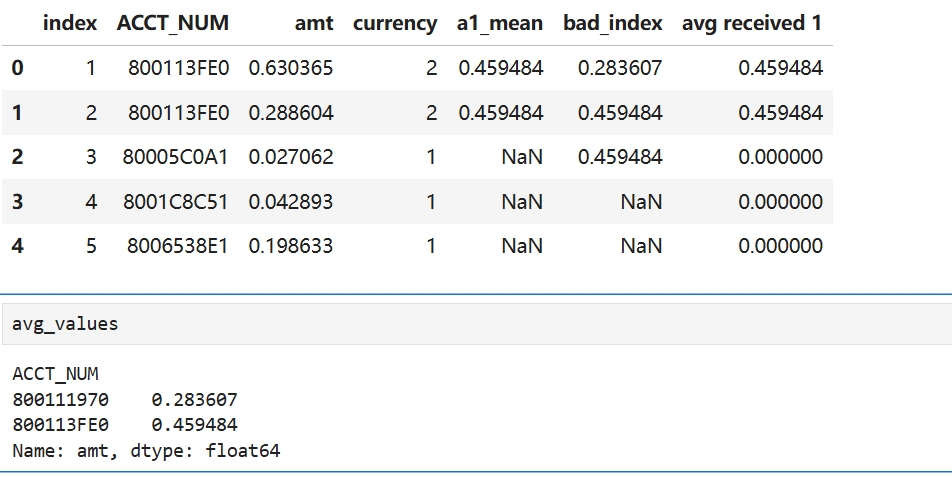
avg_values这种分组方式生成的序列index为分组键,故后面map时可以一一对应
|
|
对df添加列bm25_label,按query_text分组,取每一组中bm25_sim_score的最大值对应的sim_label的值
# 按query_text分组,取每组中bm25_sim_score最大值对应的sim_label
df_max_idx = df.groupby('query_text')['bm25_sim_score'].idxmax()
top1_labels = df.loc[df_max_idx, ['query_text', 'sim_label']].set_index('query_text')['sim_label']
df['bm25_top1_label'] = df['query_text'].map(top1_labels)
|
|
|
|
|
时间处理
data_path = "/wks/datasets/ibm_aml/bb11_train_ibm_small.csv"
df = pd.read_csv(data_path)
df.shape
(5078345, 14)
df.resample('D', on='DT_TIME')
count_per_day = df.resample('D', on='DT_TIME').size().reset_index(name='rows')
count_per_day
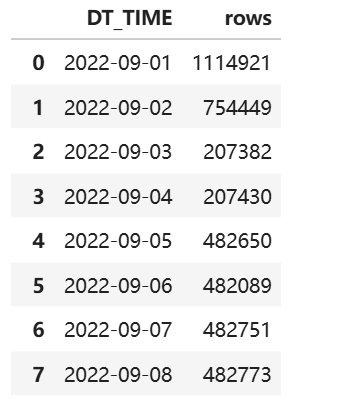
import pandas as pd
# 假设已有 DataFrame: df
# 1) 把 DT_TIME 转成 datetime
df['DT_TIME'] = pd.to_datetime(df['DT_TIME'], format='%Y/%m/%d %H:%M')
# 2) 按“天”统计行数
count_per_day = (
df.groupby(df['DT_TIME'].dt.date) # 按日期分组
.size() # 计数
.reset_index(name='rows') # 变回 DataFrame
)
print(count_per_day)
DT_TIME rows
0 2022-09-01 1114921
1 2022-09-02 754449
2 2022-09-03 207382
3 2022-09-04 207430
4 2022-09-05 482650
5 2022-09-06 482089
6 2022-09-07 482751
7 2022-09-08 482773
8 2022-09-09 654467
9 2022-09-10 208325
10 2022-09-11 396
11 2022-09-12 281
12 2022-09-13 184
13 2022-09-14 121
14 2022-09-15 46
15 2022-09-16 46
16 2022-09-17 23
17 2022-09-18 11
import pandas as pd
# 示例数据
df = pd.DataFrame({
"DT_TIME": ["2022/09/01 00:20", "2022/09/01 12:30", "2022/09/02 01:45"]
})
# 提取日期部分(假设格式是 "YYYY/MM/DD HH:MM")
df["DATE"] = df["DT_TIME"].str.split(" ").str[0]
# 按天统计行数
daily_counts = df["DATE"].value_counts().sort_index()
print(daily_counts)
转换为 datetime 后按日期分组(推荐)
# 转换为 datetime 类型
df["DT_TIME"] = pd.to_datetime(df["DT_TIME"], format="%Y/%m/%d %H:%M")
# 方法 2.1: 使用 dt.date 提取日期
daily_counts = df.groupby(df["DT_TIME"].dt.date).size()
print(daily_counts)
# 方法 2.2: 使用 dt.floor("D") 按天分组(等价于 dt.date)
daily_counts = df.groupby(df["DT_TIME"].dt.floor("D")).size()
print(daily_counts)
直接使用 resample(时间序列专用)
# 将 DT_TIME 设为索引
df = df.set_index("DT_TIME")
# 按天统计行数
daily_counts = df.resample("D").size()
print(daily_counts)
|
有一个pandas数表,列的信息如下
```
class ParamConfig:
#字段列
time14 = "DT_TIME"
id11 = "ACCT_NUM"
id12 = "TCAC"
bank11 = "ORGANKEY"
bank12 = "CFIC"
amt1 = "CRAT" #原币交易金额,付
amt2 = "CRAT" #原币交易金额,收
amt3 = "CNY_AMT"
amt4 = "USD_AMT"
currency1 = "CRTP" #币种
currency2 = "CRTP"
channel = "TSTP"
label = "VOUCHER_NO"
drop_cols = ["TICD","CB_PK","TX_NO","CNY_AMT","USD_AMT"]
dict_file = "dict_file23.txt"
num_scaler_file = "scaler_num23.pkl"
date_scaler_file = "scaler_date23.pkl"
max_date = '2035-01-01'
model_param_path = "ibm_gnn_model_1.pkl"
def __init__(self):
"""
- identity:标识列,需要转str
- date_type:日期列
- classify_type:类型别,需要需要转str
- num_type:数字列,转float64
"""
#字段列分类
self.identity= [self.id11,self.id12,self.bank11,self.bank12]
self.date_type = [self.time14]
self.classify_type = [self.channel,self.currency1]
self.classify_type2 = [[self.bank11,self.bank12]] #一组类别使用同一个字典
self.classify_type_pre = [self.channel, self.currency1, self.bank11, self.bank12] #预测时的类别列
self.num_type = [self.amt1]
self.bool_type = []
pc = ParamConfig()
```
按以下逻辑重新合并数据:
1. pc.id11与pc.id12相同的交易进行合并
2. 日期字段可以按1天合并,也可以按2天合并,还可以按小时合并,该部分配置为参数,可选参数有按小时,按天
3. 合并时判断交易中的类别型字段,cp.classify_type,需要交易按类别分组,相同类别的交易进行合并
4. 分组后相同的类别组合中数字类型字段相加
5. 不用考虑pc.label字段
请实现以上功能
单天多类别
下面给出一段可直接落地的代码,把“时间粒度”做成可配置参数(hour / day),其余规则全部满足。
核心思路:
1. 先把日期截断成指定粒度;
2. 用 `[id11, id12, 截断时间, channel, currency1]` 组成分组键;
3. 数字列求和,其余列保留第一条。
```python
import pandas as pd
def merge_transactions(
df: pd.DataFrame,
time_grain: str = "day" # 'hour' 或 'day'
) -> pd.DataFrame:
"""
按规则合并交易
:param df: 原始 DataFrame
:param time_grain: 'hour' 或 'day'
:return: 合并后的 DataFrame
"""
# ---------- 1. 字段类型处理 ----------
str_cols = pc.identity + pc.classify_type
df[str_cols] = df[str_cols].astype(str)
df[pc.time14] = pd.to_datetime(df[pc.time14], errors='coerce')
# ---------- 2. 构造截断时间 ----------
if time_grain == "hour":
df["time_key"] = df[pc.time14].dt.floor("H")
elif time_grain == "day":
df["time_key"] = df[pc.time14].dt.floor("D")
else:
raise ValueError("time_grain 只能取 'hour' 或 'day'")
# ---------- 3. 分组键 ----------
group_keys = [pc.id11, pc.id12, "time_key"] + pc.classify_type
# ---------- 4. 聚合规则 ----------
# 数字列:求和
num_cols = [c for c in pc.num_type if c in df.columns]
# 其余列:保留第一条
other_cols = [c for c in df.columns if c not in num_cols + group_keys + [pc.label]]
agg_dict = {c: "sum" for c in num_cols}
agg_dict.update({c: "first" for c in other_cols})
# label 明确丢弃,所以不放进聚合规则
# ---------- 5. 合并 ----------
df_out = (
df
.groupby(group_keys, as_index=False, sort=False)
.agg(agg_dict)
)
# 把截断时间列删掉,保持原列
df_out = df_out.drop(columns=["time_key"])
return df_out
# -------------------- 使用示例 --------------------
# df_raw = pd.read_csv("xxx.csv")
# df_merged = merge_transactions(df_raw, time_grain="day") # 或 "hour"
```
使用方式
```python
# 按小时合并
df_hour = merge_transactions(df, time_grain="hour")
# 按天合并
df_day = merge_transactions(df, time_grain="day")
```
代码已满足
1. `id11` + `id12` 相同交易合并
2. 时间粒度可配置:hour / day
3. `classify_type`(即 `TSTP` 与 `CRTP`)同类别再分组
4. 数字列(`amt1` 等)求和
5. 忽略 `label / VOUCHER_NO`。
|
|
封装示例 import pandas as pd data_path = "/wks/datasets/ibm_aml/bb11_train_ibm_small.csv" df = pd.read_csv(data_path) df.shape from dataflow import agg_days from algtu import ParamConfig pc = ParamConfig() results = agg_days(df,pc) results 详细代码 from algtu import ParamConfig pc = ParamConfig() import pandas as pd data_path = "/wks/datasets/ibm_aml/bb11_train_ibm_small.csv" df = pd.read_csv(data_path) df.shape
import pandas as pd
from typing import List, Dict, Any, Literal, Optional
from datetime import datetime, timedelta
class PtimeAgg:
def merge_transactions_with_time_granularity(self,
df: pd.DataFrame,
pc: ParamConfig,
time_granularity: Literal['hour', 'day'] = 'day',
days_interval: int = 1,
time_column: str = None
) -> pd.DataFrame:
"""
按时间粒度合并交易数据
参数:
df: 原始交易数据DataFrame
pc: ParamConfig配置对象
time_granularity: 时间粒度,可选 'hour' 或 'day'
days_interval: 当time_granularity='day'时,指定合并的天数间隔
time_column: 时间列名,如果为None则使用pc.date_type中的第一个时间列
返回:
合并后的DataFrame
"""
# 确保必要的列存在
required_cols = pc.identity_agg + pc.classify_type + pc.date_type
missing_cols = [col for col in required_cols if col not in df.columns]
if missing_cols:
raise ValueError(f"数据框中缺少必要的列: {missing_cols}")
# 设置时间列
if time_column is None:
time_column = pc.date_type[0]
# 复制数据以避免修改原始数据
df_work = df.copy()
# 确保时间列是datetime类型
if not pd.api.types.is_datetime64_any_dtype(df_work[time_column]):
df_work[time_column] = pd.to_datetime(df_work[time_column])
# 根据时间粒度创建时间分组键
if time_granularity == 'hour':
# 按小时分组
df_work[pc.time_group] = df_work[time_column].dt.floor('h')
elif time_granularity == 'day':
if days_interval == 1:
# 按天分组
df_work[pc.time_group] = df_work[time_column].dt.date
else:
# 按多天间隔分组
df_work[pc.time_group] = df_work[time_column].apply(
lambda x: self._get_time_interval_group(x, days_interval)
)
else:
raise ValueError("time_granularity 必须是 'hour' 或 'day'")
# 定义分组键:id11, id12, 类别字段, 时间分组
groupby_cols = pc.identity_agg + pc.classify_type + [pc.time_group]
# 定义聚合规则
aggregation_rules = self._create_aggregation_rules(df_work, pc, time_column)
# 执行分组聚合
merged_df = df_work.groupby(groupby_cols, as_index=False).agg(aggregation_rules)
# 清理临时列
if pc.time_group in merged_df.columns:
merged_df = merged_df.drop(pc.time_group, axis=1)
# 重置索引
merged_df.reset_index(drop=True, inplace=True)
return merged_df
def _get_time_interval_group(self, dt: datetime, days_interval: int) -> str:
"""
根据天数间隔获取时间分组键
参数:
dt: datetime对象
days_interval: 天数间隔
返回:
分组键字符串
"""
if days_interval <= 0:
raise ValueError("days_interval 必须大于0")
# 计算从某个参考点开始的天数间隔
# 这里使用1970-01-01作为参考点
reference_date = datetime(1970, 1, 1)
days_diff = (dt - reference_date).days
group_num = days_diff // days_interval
start_date = reference_date + timedelta(days=group_num * days_interval)
end_date = start_date + timedelta(days=days_interval - 1)
return f"{start_date.strftime('%Y-%m-%d')}_{end_date.strftime('%Y-%m-%d')}"
def _create_aggregation_rules(self, df: pd.DataFrame, pc: ParamConfig, time_column: str) -> Dict[str, Any]:
"""
创建聚合规则字典
参数:
df: 数据框
pc: 配置对象
time_column: 时间列名
返回:
聚合规则字典
"""
aggregation_rules = {}
# 数值型字段 - 求和
for num_col in pc.num_type:
if num_col in df.columns:
aggregation_rules[num_col] = 'sum'
# 时间字段 - 取最小值(表示该时间段的开始时间)
if time_column in df.columns:
aggregation_rules[time_column] = 'min'
# 标识字段 - 取第一个值(因为这些字段在合并后应该相同)
for id_col in pc.identity:
if id_col in df.columns and id_col not in [pc.id11, pc.id12]:
aggregation_rules[id_col] = 'first'
# 类别字段已经在分组键中,不需要额外聚合
# 处理其他字段 - 取第一个值
for col in df.columns:
if (col not in aggregation_rules and
col not in pc.identity_agg + pc.classify_type + [pc.time_group] and
col != pc.label): # 排除label字段
aggregation_rules[col] = 'first'
return aggregation_rules
def merge_transactions_flexible(self,
df: pd.DataFrame,
pc: ParamConfig,
time_config: Optional[Dict[str, Any]] = None
) -> pd.DataFrame:
"""
灵活的合并函数,支持多种配置选项
参数:
df: 原始交易数据DataFrame
pc: ParamConfig配置对象
time_config: 时间配置字典,包含:
- granularity: 'hour', 'day', 'none'(不按时间分组)
- days_interval: 当granularity='day'时的天数间隔
- time_column: 时间列名
返回:
合并后的DataFrame
"""
# 默认时间配置
if time_config is None:
time_config = {
'granularity': 'day',
'days_interval': 1,
'time_column': pc.date_type[0] if pc.date_type else None
}
# 复制数据
df_work = df.copy()
# 设置分组键
groupby_cols = pc.identity_agg + pc.classify_type
# 处理时间分组
if time_config['granularity'] != 'none' and time_config['time_column']:
time_column = time_config['time_column']
# 确保时间列是datetime类型
if not pd.api.types.is_datetime64_any_dtype(df_work[time_column]):
df_work[time_column] = pd.to_datetime(df_work[time_column])
if time_config['granularity'] == 'hour':
# 按小时分组
df_work[pc.time_group] = df_work[time_column].dt.floor('H')
groupby_cols.append(pc.time_group)
elif time_config['granularity'] == 'day':
if time_config['days_interval'] == 1:
# 按天分组
df_work[pc.time_group] = df_work[time_column].dt.date
groupby_cols.append(pc.time_group)
else:
# 按多天间隔分组
df_work[pc.time_group] = df_work[time_column].apply(
lambda x: self._get_time_interval_group(x, time_config['days_interval'])
)
groupby_cols.append(pc.time_group)
# 创建聚合规则
aggregation_rules = self._create_aggregation_rules(df_work, pc, time_config['time_column'] if time_config['time_column'] else None)
# 执行分组聚合
merged_df = df_work.groupby(groupby_cols, as_index=False).agg(aggregation_rules)
# 清理临时列
if pc.time_group in merged_df.columns:
merged_df = merged_df.drop(pc.time_group, axis=1)
# 重置索引
merged_df.reset_index(drop=True, inplace=True)
return merged_df
# 使用示例
def example_usage():
"""
使用示例
"""
# 假设你已经有了数据框 df 和配置对象 pc
# df = pd.read_csv('your_data.csv')
# pc = ParamConfig()
pt = PtimeAgg()
# 示例1: 按天合并
merged_daily = pt.merge_transactions_with_time_granularity(
df, pc, time_granularity='day', days_interval=1
)
# 示例2: 按2天间隔合并
merged_2days = pt.merge_transactions_with_time_granularity(
df, pc, time_granularity='day', days_interval=2
)
# 示例3: 按小时合并
merged_hourly = pt.merge_transactions_with_time_granularity(
df, pc, time_granularity='hour'
)
# 示例4: 使用灵活配置
time_config = {
'granularity': 'day',
'days_interval': 3,
'time_column': pc.time14
}
merged_custom = pt.merge_transactions_flexible(df, pc, time_config)
print("合并完成!")
print(f"原始数据行数: {len(df)}")
print(f"按天合并后行数: {len(merged_daily)}")
print(f"按2天合并后行数: {len(merged_2days)}")
print(f"按小时合并后行数: {len(merged_hourly)}")
print(f"自定义合并后行数: {len(merged_custom)}")
return {
'daily': merged_daily,
'2days': merged_2days,
'hourly': merged_hourly,
'custom': merged_custom
}
results = example_usage()
results
|
|
|
|
|
按指定列更新
按identity_agg作为标识字段对数据按day做了聚合df_days,聚合后的数据df_days没有pc.label字段,现在要为聚合后的数据df_days增加pc.label字段(pc.label字段的值只有0与1),方法如下:
1. 针对原始数据df,按identity_agg作为标识字段 分析pc.label字段,如果pc.label字段存在为1的值,那么聚合后数据的pc.label为1
2. 针对原始数据df,按identity_agg作为标识字段 分析pc.label字段,如果pc.label字段的值皆为0,那么聚合后数据的pc.label为0
请实现以上功能
import pandas as pd
# 假设已有
# pc = ParamConfig()
# df : 原始交易流水
# df_days : 按 identity_agg 聚合后的表(不含 pc.label)
# 1. 计算每个 identity_agg 分组是否出现过 label==1
label_flag = (
df.groupby(pc.identity_agg)[pc.label] # 按标识字段分组
.max() # 只要出现过1,max就是1
.astype(int) # 确保是 0/1 int
.rename(pc.label) # 列名保持统一
.reset_index() # 变回普通列
)
# 2. 把结果合并到聚合后的表
df_days = df_days.merge(label_flag, on=pc.identity_agg, how='left')
# 如果 df_days 里原本就可能有 pc.label,但值全为 NaN,需要覆盖
# df_days[pc.label] = df_days[pc.label].fillna(0).astype(int)
df_days[pc.label].unique()
array([0, 1])
label_flag 中有pc.label为1的数据,df_days中原本是没有pc.label标签的, 但merge之后,df_days中有了pc.label为1的数据可以理解,但pc.label为0的数据是怎么来的?
`label_flag` 这张表 **对每一个** `identity_agg` 组合 **都有一条记录**,
其中 `label_flag[pc.label]` 要么是 1,要么是 0。
在 `merge` 时,`how='left'` 以 `df_days` 为主表,去 `label_flag` 里 **精准匹配** 对应的 `identity_agg` 组合。
- 只要匹配成功,`label_flag` 里对应的 0 或 1 就被带进来;
- 由于 `label_flag` 本身就把所有出现过的组合都算了一遍,**不会出现匹配不到的情况**,因此 **不会留下 NaN**。
所以:
- 在原始 `df` 中 **出现过 1** 的组 → `label_flag` 里就是 1 → merge 后对应行就是 1;
- 在原始 `df` 中 **只有 0** 的组 → `label_flag` 里就是 0 → merge 后对应行就是 0。
这就是 **“pc.label 为 0 的数据是怎么来的”** ——
它们本来就由 `groupby(...).max()` 算出来并放在 `label_flag` 里,再通过 `merge` 带进了 `df_days`。
|
# 假设原始数据为 df,聚合后的数据为 df_days
# 1. 从原始数据df中,针对每个identity_agg分组,计算label的最大值(因为label只有0和1,最大值即为是否存在1)
label_agg = df.groupby(pc.identity_agg)[pc.label].max().reset_index()
# 重命名列,以便后续合并
label_agg.rename(columns={pc.label: pc.label}, inplace=True)
# 2. 将计算得到的label合并到聚合后的数据df_days中
# 注意:df_days中已经按identity_agg聚合(可能包含多列),这里使用left merge以确保df_days的行数不变
df_days = df_days.merge(label_agg, on=pc.identity_agg, how='left')
# 3. 检查是否有缺失值(正常情况下不应该有,因为df_days的identity_agg来自df)
# 如果有缺失,则填充为0(根据业务逻辑:如果原始数据中没有该分组,则标记为0?但通常不会出现)
# 但根据需求,原始数据df中每个identity_agg分组至少有一条记录,所以这里应该没有缺失。
# 为了安全,可以填充0:
df_days[pc.label].fillna(0, inplace=True)
# 4. 确保label列为整数类型(0和1)
df_days[pc.label] = df_days[pc.label].astype(int)
|
|
|
|
|
|
|
参考