交易·转序列对
|
|
|
|
|
|
|
|
交易·模型设计
import math
import torch
from torch import nn
class pc:
batch_size = 64
max_seq_len=100
col_nums = 13
embedding_dim=128
#[B,L,C],一个序列100条交易,一条交易13个特征/列
data = torch.randn(pc.batch_size,pc.max_seq_len,pc.col_nums)
from tpf.seq import PositionLinear2
embed = PositionLinear2(seq_len=pc.max_seq_len, in_feature=pc.col_nums, embedding_dim=pc.embedding_dim)
res = embed(data)
res.shape #torch.Size([64, 100, 128])
from tpf.seq import PositionLinear embed = PositionLinear2(seq_len=pc.max_seq_len, in_feature=pc.col_nums, embedding_dim=pc.embedding_dim) res = embed(data) res.shape #torch.Size([64, 100, 128])
PositionLinear2是自定义的线性模型且增加了LayerNorm
PositionLinear 是torch线性模型,无LayerNorm
|
一种为只使用编码器提取特征,转到类别维度 一种为 多模型合作 模型1: - 编码器提取特征 -- 维度A(200) --对应类别 模型2: - 生成器预测正常数据的序列 -- 维度B(200) - 真实数据为维度C(200) - 无监督,无类别,只是生成预测,且是正常数据的生成预测,无异常数据 - 只生成一笔交易 模型3: - 维度A与维度B,C 共三列,映射到类别01 预测 - 输入一笔交易的前100笔,来预测来第101笔 - 然后再结合这第101笔 - 代入模型,得到第101笔是0还是1
|
from tpf.seq import PositionLinear embed_x = PositionLinear(seq_len=pc.max_seq_len, in_features=pc.col_nums, out_features=pc.embedding_dim) x = embed_x(data) x.shape from tpf.layer import Encoder encoder = Encoder(features=pc.embedding_dim,head_num=4) x = encoder(x, None) x.shape |
import torch
from torch import nn
from tpf.nlp.ts12 import Transformer12
class pc:
batch_size = 64
min_seq_len=40 #暂时没有使用,还没有完成开发
max_seq_len=50
col_nums = 13
embedding_dim=128
class_nums = 2
padding_index = 0
data = torch.randn(pc.batch_size,pc.max_seq_len,pc.col_nums)
transformer = Transformer12(pc)
y_out = transformer(data)
y_out.shape #torch.Size([64, 50, 2])
交易数据矩阵[batch_size,seq_len,col_nums] -- 位置编码 [batch_size,seq_len,embedding_dim] -- 编码器 维度变换/特征提取 [batch_size,seq_len,embedding_dim] -- 全连接映射到类别标签维度 [batch_size,seq_len,class_nums] |
|
|
交易·损失函数
在 PyTorch 框架中,MSE(均方误差)损失函数是处理回归任务的核心指标, 其数学本质为预测值与真实值之间平方差的均值计算。 torch.nn.MSELoss(reduction='mean')
import torch
import torch.nn as nn
# 生成模拟数据
input = torch.randn(3, 2, requires_grad=True) # 预测值张量(3样本×2特征)
target = torch.randn(3, 2) # 真实值同维度张量
# 损失函数实例化
mse_loss = nn.MSELoss()
# 前向计算
loss = mse_loss(input, target)
print(f"Mean Squared Error: {loss.item():.4f}") #Mean Squared Error: 3.8325
# 梯度反向传播
loss.backward()
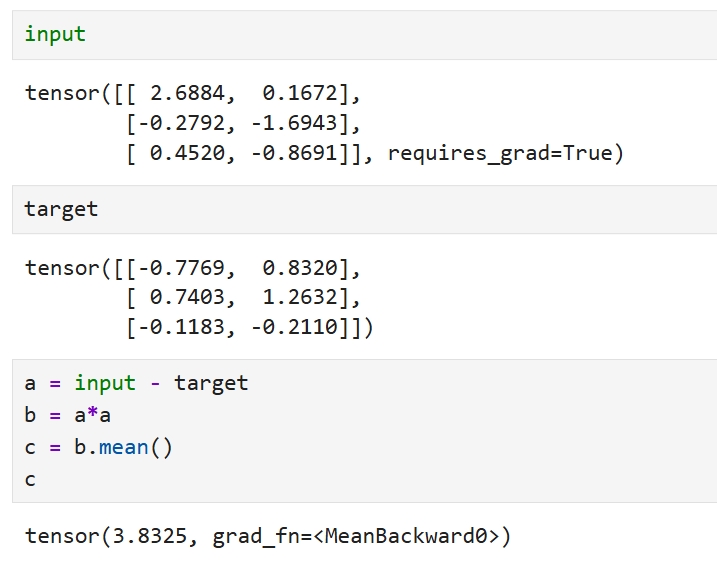
只要shape相同,就可以做差,平方,求均值
- 同位置元素一一对应,做差,平方
- 所有元素求均值
- 这就是均方误差

梯度特性: 误差较大时梯度幅值显著增大,可能导致梯度爆炸, 实际应用中需配合梯度裁剪(torch.nn.utils.clip_grad_norm_)使用 应用场景: 适用于数值预测类任务(如房价预测、设备指标预测), 对异常值敏感的特性使其在噪声较多的场景需谨慎使用
|
import torch
import torch.nn as nn
batch_size = 10
seq_len = 100 #一个序列数据中,交易的个数
embedding_dim = 256 #一个交易数据中,特征维度的个数,二维数表中列的个数
#[low,high)
#这里一个交易对应一个类别,一个序列中有seq_len条交易,这个类别也形成一个序列
target = torch.randint(low=0,high=2,size=(batch_size,seq_len))
X = torch.randn(batch_size,seq_len,embedding_dim, requires_grad=True)
# 全连接变换前一个样本化为一个1维向量,感觉只变换embedding_dim保留序列维度更合适一些
x = X.reshape(batch_size,-1)
#变换到序列的维度,一个交易与一个类别对应
linear = nn.Linear(in_features=seq_len*embedding_dim,out_features=seq_len)
x = linear(x)
# 损失函数实例化
mse_loss = nn.MSELoss()
y = target.float()
loss = mse_loss(x,y)
print(f"Mean Squared Error: {loss.item():.4f}") #Mean Squared Error: 0.8101
loss.backward()
|
|
|
|
|
|
|
参考