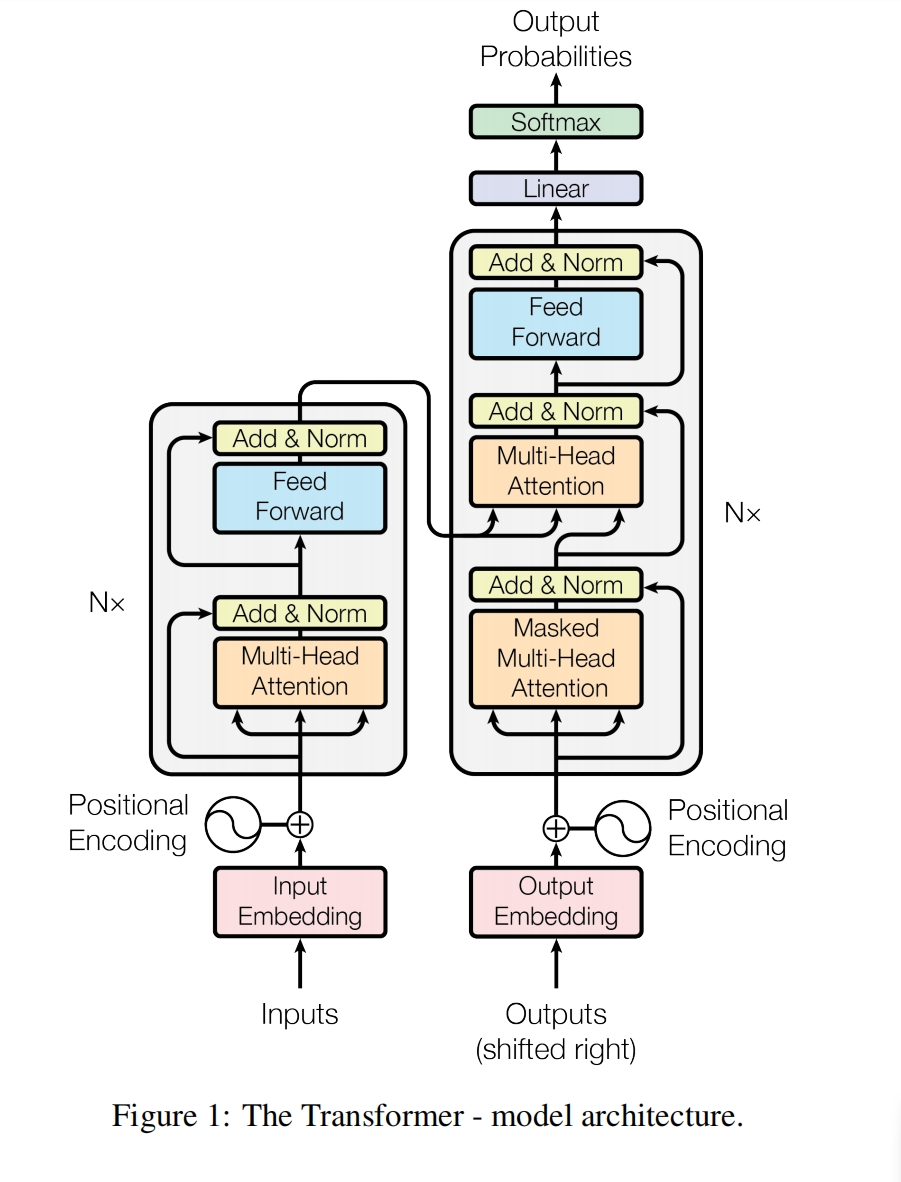
总体流程图
|
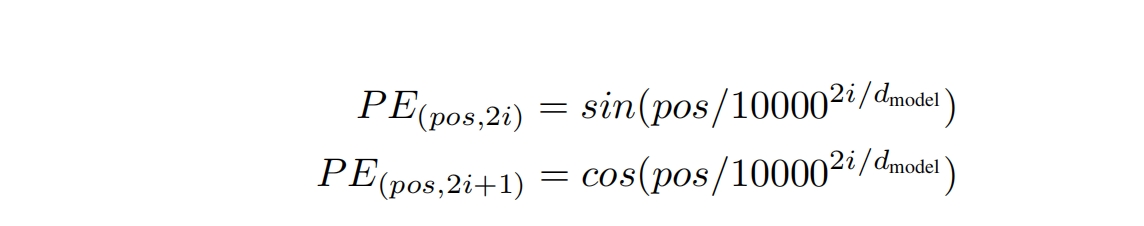
加入周期性变化的位置信息 L 一句话中有多少个单词, pos 表示第几个单词,范围[0,L-1],pos为单词在句子中的位置 单词向量的维度为embedding_dim,i属于[0,embedding_dim-1] i 表示向量维度的位置,第几维 transformer网络中向量特征个数通常是固定的,比如512维 每个小区域会从512变大,但最后小区域结束时,会收缩到512维, 然后不断地循环重复这一系列的小区域, 参数在网络中的特征变化为,在某个特定的维度附近,一张一收,循环往复 这个固定的维度就是d 优点/作用
可以处理任何⻓度的序列:
- 因为编码是通过函数⽣成的,所以理论上可以为任何⻓度的序列⽣成位置编码。
可以捕捉相对位置信息:
- 这种编码⽅式能够让模型捕捉词与其周围词之间的相对位置关系。
可以轻易加到词向量上:
- 这些编码是添加到词嵌⼊向量上的,⽽不是与之相乘,这样简化了模型。
这种位置编码⽅法为模型提供了词在序列中相对位置的信息,
这对于许多NLP任务(如翻译、摘要等)来说是⾮常有⽤的。
下面的部分为个人猜测,如有雷同,纯属巧合
参数在网络中的特征变化为,在某个特定的维度附近,一张一收,循环往复
特别像跳动的音符,音乐播放时那个在一定范围内跳动的曲线,
但语音通常有五个主峰频率,但tranformer的model维度通常一个,d=512,
个人猜测,tranformer后续要想有更强大的表征能力,
这个model维度也应该能够随数据规律而增加/变化才是
|
生成模式 解码训练是一个序列生成一个单词,然后再生成下一个,是一上下三角矩阵 |
编码器X提供KV,解码器为Q X是整个编码器的最终输出 y则是解码器每个小模块(注意力+残差+归一化)的输入 即解码器所有小模块 共用同一个x |
注意力是求特征的,残差是解决梯度消失问题的,整个小模块就是为了能够多次循环求特征 前馈神经网络,线性变换+激活函数,是为了特征变换,将一个维度的特征映射到另外一个维度 注意力中是没有激活函数的,是纯线性变换,且不注重特征在不同维度的变换, 注意力的线性变换是模型维度d的变换, 要求的是相对重要性,侧重于百分比,概率的计算,再与V相乘,化为具体的值 注意力是要分个高下,称一称到底几斤几两,划分成三六九等, 让差异清晰明了...这样方便后续特征变换 其实这就是一个评分模型,通常内积/相似度运算,让重要维度上的数值/评分 大/高一点 前馈神经网络的特征变换,是不同维度的变换 通常是模型维度d -- 2d/4d -- 模型维度d,是有一个一张一收的过程的 特征维度先大后小,这也是神经网络特征变换的一个基本思想 所以,这里的神经网络通常是两层, 一层将特征维度变大,一层将之收缩回来,每层+一个激活函数 |
注意力
|
自注意力
import torch
from torch import nn
class pc:
batch_size=64
seq_len= 32
embedding_dim = 128
head_num = 4
x = torch.randn(pc.batch_size,pc.seq_len,pc.embedding_dim)
from tpf.att import MultiHead
mhead = MultiHead(n_features=pc.embedding_dim,head_num=pc.head_num)
x = mhead(x,x,x,mask=None)
x.shape #torch.Size([64, 32, 128])
mask矩阵补码矩阵,其值为0与1,PAD所在位置为1
|
mask主要是为了确定PAD的位置
在多头注意力中
[batch_size,seq_len1,embedding_dim] -- [batch_size,head_num,seq_len1,head] ,embedding_dim= head_num*head
[batch_size,seq_len2,embedding_dim] -- [batch_size,head_num,seq_len2,head] ,embedding_dim= head_num*head
[batch_size,head_num,seq_len1,head] @ [batch_size,head_num,head,seq_len2] -- [batch_size,head_num,seq_len1,seq_len2]
- score = torch.matmul(Q, K.permute(0, 1, 3, 2))
mask就是要标记出 [batch_size,head_num,seq_len1,seq_len2] 中 PAD的位置
在自注意力中,seq_len2=seq_len1 mask就是要标记出 [batch_size,head_num,seq_len1,seq_len1] 中 PAD的位置
原始数据是[batch_size,seq_len1],元素为单词
设seq_len1 = 3,以"你好"为例
["你","好","PAD"] --补码-- [1,2,0]
这是两句话,
是序列1“你好”相对序列2“你好”的自注意力
对于序列1中的元素 “你”来说,序列2中最后一个元素为补码PAD,为0,可以不计算该元素,--补码-- [1,2,0]
对于序列1中的元素 “好”来说,序列2中最后一个元素为补码PAD,为0,可以不计算该元素,--补码-- [1,2,0]
对于序列1中的元素 “PAD”来说,序列2中最后一个元素为补码PAD,为0,可以不计算该元素,--补码-- [1,2,0]
对于序列1中的每个元素来说,它的补码都是一样的,相当于复制了seq_len1份
于是mask的shape为[batch_size,seq_len1,seq_len1]
|
import torch
from torch import nn
from tpf.vec3 import mask_pad
x = torch.tensor([[1,2,0]])
mask = mask_pad(x,padding_index=0)
mask.shape #torch.Size([1, 1, 3, 3])
mask
tensor([[[[False, False, True],
[False, False, True],
[False, False, True]]]])
class pc:
batch_size = 1
seq_len = 3
embedding_dim = 128
num_embeddings = 3
head_num = 4
# 单词编码
print(x.shape) #torch.Size([1, 3])
embed = torch.nn.Embedding(pc.num_embeddings, pc.embedding_dim)
x = embed(x)
x.shape # torch.Size([1, 3, 128])
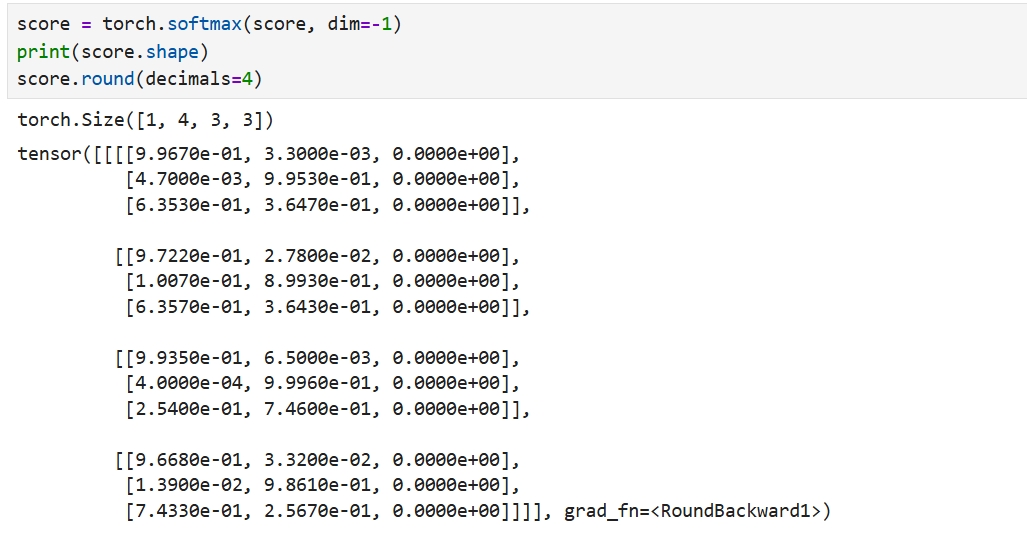
# 拆分多头 dk = pc.embedding_dim//pc.head_num Q = x.reshape(pc.batch_size, pc.seq_len, pc.head_num, dk).permute(0, 2, 1, 3) K = x.reshape(pc.batch_size, pc.seq_len, pc.head_num, dk).permute(0, 2, 1, 3) Q.shape #torch.Size([1, 4, 3, 32]) #分数计算 score = torch.matmul(Q, K.permute(0, 1, 3, 2)) score.shape #torch.Size([1, 4, 3, 3]) # 归一约束 score /= dk ** 0.5 score.shape #torch.Size([1, 4, 3, 3]) 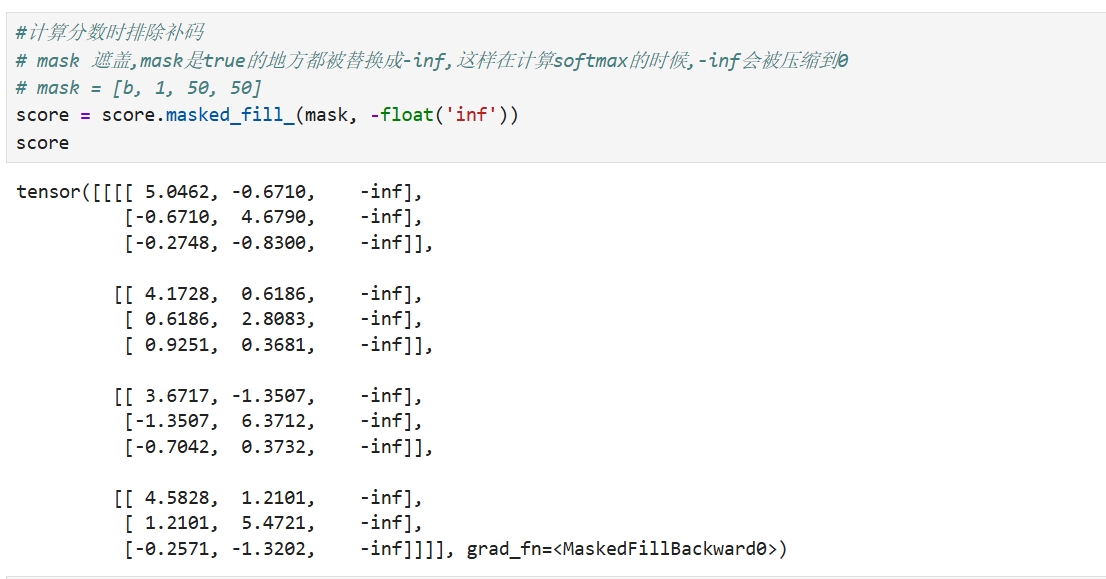
单词索引编码为shape为[batch_size,seq_len] 下面是[batch_size,seq_len] 扩展到 [batch_size,1,seq_len,seq_len]的过程 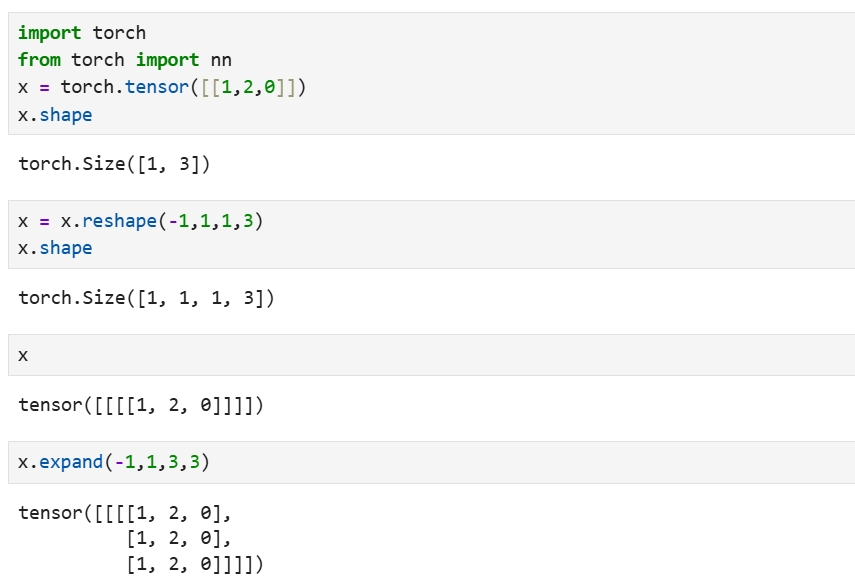
|
|
|
|
|
数据集·字母转换-2
## 字母转换
- 0-9,1-8,2-7...
- 小写转大写
是一种一对一的映射
- 严格来说,没有位置之间的关系
封装调用示例
import numpy as np
import torch
from tpf.datasets import ZiMu11
# 数据加载器
loader = torch.utils.data.DataLoader(dataset=ZiMu11(min_seq_len=40,max_seq_len = 50),
batch_size=8,
drop_last=True,
shuffle=True,
collate_fn=None)
for (X,y) in loader:
print(X.shape,y.shape) #torch.Size([8, 50]) torch.Size([8, 50])
print(X[0])
print(y[0])
break
torch.Size([8, 50]) torch.Size([8, 50])
tensor([ 1, 50, 8, 5, 53, 8, 30, 3, 50, 29, 50, 20, 14, 61, 21, 3, 31, 30,
8, 59, 19, 58, 40, 5, 8, 62, 20, 5, 59, 16, 53, 54, 13, 61, 8, 50,
59, 54, 5, 54, 19, 10, 50, 63, 61, 13, 2, 0, 0, 0])
tensor([ 1, 38, 52, 25, 35, 52, 32, 28, 38, 49, 38, 10, 23, 15, 37, 28, 45, 32,
52, 41, 18, 60, 17, 25, 52, 47, 10, 25, 41, 24, 35, 39, 51, 15, 52, 38,
41, 39, 25, 39, 18, 20, 38, 26, 15, 51, 2, 0, 0, 0])
----------------------------------------------------
|
# import os
# 解决mac系统OMP: Error #15: Initializing libiomp5.dylib, but found libomp.dylib already initialized.
# os.environ['KMP_DUPLICATE_LIB_OK']='True'
str_x = '0,1,2,3,4,5,6,7,8,9,q,w,e,r,t,y,u,i,o,p,a,s,d,f,g,h,j,k,l,z,x,c,v,b,n,m'
str_y = str_x.upper()
ss = str_x+","+str_y
# 定义字典,数据是0-9数字+小写字母,以及 三个标记
word_list = ['<PAD>','<SOS>','<EOS>']+list(set(ss.split(',')))
import random
import numpy as np
import torch
word_dict = {word: i for i, word in enumerate(word_list)}
print(word_dict["<PAD>"]) #0
class pc:
min_seq_len = 30
max_seq_len = 50
def get_data():
"""获取一对x,y
"""
# 单词集合,没有标记
words = [
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'q', 'w', 'e', 'r',
't', 'y', 'u', 'i', 'o', 'p', 'a', 's', 'd', 'f', 'g', 'h', 'j', 'k',
'l', 'z', 'x', 'c', 'v', 'b', 'n', 'm'
]
# 每个词被选中的概率
p = np.array([
1, 2, 3, 4, 5, 6, 7, 8, 9, 10,
1, 2, 3, 4, 5, 6, 7, 8, 9, 10,
11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26
])
# 转概率,所有单词的概率之和为1
p = p / p.sum()
# 随机选n个词
# Return random integer in range [a, b], including both end points.
n = random.randint(pc.min_seq_len, pc.max_seq_len-2) #有开始标记与结束标记
x = np.random.choice(words, size=n, replace=True, p=p)
# 采样的结果就是x
x = x.tolist()
# y是对x的变换得到的
# 字母大写,数字取10以内的互补数
def f(i):
i = i.upper()
if not i.isdigit():
return i
i = 9 - int(i)
return str(i)
y = [f(i) for i in x]
# 每个标签结尾的字母重复2次,增加任务难度
# y = y + [y[-1]]
# # 逆序
# y = y[::-1]
# 加上首尾符号
x = ['<SOS>'] + x + ['<EOS>']
y = ['<SOS>'] + y + ['<EOS>']
# 补pad到固定长度
# 48+2,序列最大长度为50,不足50的补到50
# y由于重复了一个字母,最大长度为51,不足51的补到51
x = x + ['<PAD>'] * pc.max_seq_len
y = y + ['<PAD>'] * pc.max_seq_len
x = x[:pc.max_seq_len]
y = y[:pc.max_seq_len]
# 单词序列转 索引列表
x = [word_dict[i] for i in x]
y = [word_dict[i] for i in y]
# 转tensor
x = torch.LongTensor(x)
y = torch.LongTensor(y)
return x, y
# 定义数据集
class Dataset(torch.utils.data.Dataset):
def __init__(self):
super(Dataset, self).__init__()
def __len__(self):
return 100000
def __getitem__(self, i):
return get_data()
# 数据加载器
loader = torch.utils.data.DataLoader(dataset=Dataset(),
batch_size=8,
drop_last=True,
shuffle=True,
collate_fn=None)
if __name__ == '__main__':
for (X,y) in loader:
print(X.shape,y.shape) #torch.Size([8, 50]) torch.Size([8, 50])
print(X[0])
"""
tensor([ 1, 14, 23, 37, 59, 37, 39, 21, 7, 39, 11, 13, 54, 40, 17, 54, 23, 3,
42, 39, 32, 11, 32, 49, 4, 3, 33, 60, 30, 42, 56, 11, 23, 56, 40, 22,
3, 62, 56, 23, 19, 2, 0, 0, 0, 0, 0, 0, 0, 0])
"""
print(y[0])
"""
tensor([ 1, 53, 12, 50, 18, 50, 31, 17, 9, 31, 44, 4, 36, 29, 21, 36, 12, 61,
15, 31, 47, 44, 47, 63, 13, 61, 26, 10, 41, 15, 45, 44, 12, 45, 29, 27,
61, 58, 45, 12, 46, 2, 0, 0, 0, 0, 0, 0, 0, 0])
"""
break
|
|
|
|
|
|
|
损失函数
数据输入:[batch_size,seq_len]
模型输出:[batch_size,seq_len,embedding_dim]
字典是单词的字典,最终的映射到单词的批次为[batch_size2,embedding_dim]
使用交叉熵损失函数对应的标签为[batch_size2],其元素为字典索引
这就需要做一下维度上的转换,代码片段如下:
# 在训练时,是拿y的每一个字符输入,预测下一个字符,所以不需要最后一个字
# 主要还是因为y是51,x是50,二者要保持一致
# [8, 50, 39]
pred = model(x, y[:, :-1])
# [8, 50, 39] -> [400, 39]
# 多少个单词,展平到单词维度,准备按批次计算偏差
pred = pred.reshape(-1, 39)
# [8, 51] -> [400]
# y[:,0]为SOS标记的索引
y = y[:, 1:].reshape(-1)
# 忽略pad,忽略一个批次中所有的PAD
select = y != dict_y['PAD']
pred = pred[select] #选出pred中所有单词位置的向量
y = y[select] #选出y中所有单词的索引,形成一个新的全是单词索引的向量
#pred[-1,dict_count],y单词索引向量
#比如,y[0]=2,one hot转标签向量为[0,0,1],期望模型输出的向量为[0,0.2,0.8],最好是[0,0.1,0.9],
#损失减少的方向就是index=2位置上的数据尽量接近1,其他位置尽量逼近0
loss = loss_func(pred, y)
|
|
|
|
|
|
|
|
编码器提取特征
字母转换
- 0-9,1-8,2-7...
- 小写转大写
新准备的数据集是一对一的转换,并没有生成什么
编码器的设计足以完成这一特征的变换
- 并且编码器的功能远不止如此
- 编码器使用了注意力,每个元素除了有自己的信息,还带有全序列的信息,并且重点突出
-
完整示例代码,封装好的示例
/opt/wks/aitpf/src/tpf/nlp/ts11.py
|
import numpy as np
import torch
from tpf.datasets import ZiMu11
class pc:
min_seq_len=40
max_seq_len=50
embedding_dim=32
flag_eos = '<EOS>'
# 数据加载器
datasets = ZiMu11(min_seq_len=pc.min_seq_len,max_seq_len = pc.max_seq_len)
pc.word_dict = datasets.word_dict
pc.padding_index = pc.word_dict["<PAD>"]
pc.num_embeddings = len(pc.word_dict)
def index2word(index):
d = {pc.word_dict[key]:key for key in pc.word_dict.keys()}
return d[index]
pc.index2word = index2word
def index2seq(indexs):
ll = [pc.index2word(i) for i in indexs]
eos_index = ll.index(pc.flag_eos)
res = ''.join(ll[1:eos_index])
return res
print(index2word(0)) #<PAD>
loader = torch.utils.data.DataLoader(dataset=datasets,
batch_size=8,
drop_last=True,
shuffle=True,
collate_fn=None)
for (X,y) in loader:
print(X.shape,y.shape) #torch.Size([8, 50]) torch.Size([8, 50])
print(X[0])
print(y[0])
break
|
from tpf.vec3 import mask_pad
from tpf.seq import PositionEmbedding
from tpf.layer import Encoder
# 主模型
class Transformer(torch.nn.Module):
"""Transformer主流程
模型定义参数
- in_features:输入元素向量特征数,比如单词的embedding_dim
- out_features:输出向量特征数,比如标签的维度,词典单词个数
"""
def __init__(self, pc=None):
super().__init__()
in_features=pc.embedding_dim
out_features=pc.num_embeddings
# 位置编码和词嵌入层
self.embed_x = PositionEmbedding(seq_len=pc.max_seq_len,num_embeddings=len(pc.word_dict),embedding_dim=pc.embedding_dim)
self.embed_y = PositionEmbedding(seq_len=pc.max_seq_len,num_embeddings=len(pc.word_dict),embedding_dim=pc.embedding_dim)
self.encoder = Encoder(features=pc.embedding_dim,head_num=4)
# self.decoder = Decoder()
self.fc_out = torch.nn.Linear(pc.embedding_dim, pc.num_embeddings)
def forward(self, x, y=None):
"""
# x = [8, 50]
# y = [8, 51]
"""
# [b, 1, 50, 50]
mask_pad_x = mask_pad(x, padding_index=pc.padding_index)
# mask_tril_y = mask_tril(y)
# 编码,添加位置信息
# x = [b, 50] -> [b, 50, 32]
# y = [b, 50] -> [b, 50, 32]
x = self.embed_x(x) #索引转向量
# x, y = self.embed_x(x), self.embed_y(y)
# 编码层计算
# x: [b, 50, 32] -> [b, 50, 32]
# mask_pad_x:[b,1,50,50]
x = self.encoder(x, mask_pad_x)
# 解码层计算
# [b, 50, 32],[b, 50, 32] -> [b, 50, 32]
# y = self.decoder(x, y, mask_pad_x, mask_tril_y)
# 全连接输出,维度改变
# [b, 50, 32] -> [b, 50, 39]
y = x
y = self.fc_out(y)
return y
# 构建模型
model = Transformer(pc)
# 定义损失函数
loss_func = torch.nn.CrossEntropyLoss()
# 优化器
optim = torch.optim.Adam(model.parameters(), lr=2e-3)
|
for epoch in range(3):
for i, (X, y) in enumerate(loader):
# print(X.shape,y.shape) #torch.Size([8, 50]) torch.Size([8, 50])
# print(X[0])
# print(y[0])
y_out = model(X)
# print(y_out.shape,y_out[0][0][:3])
pred = y_out.reshape(-1, pc.num_embeddings)
# print(pred.shape)
y = y.reshape(-1)
# print(y.shape)
# 忽略pad,忽略一个批次中所有的PAD
select = y != pc.padding_index
pred = pred[select] #选出pred中所有单词位置的向量
y = y[select] #选出y中所有单词的索引,形成一个新的全是单词索引的向量
#损失减少的方向就是index=2位置上的数据尽量接近1,其他位置尽量逼近0
loss = loss_func(pred, y)
optim.zero_grad()
loss.backward()
optim.step()
if i % 1000 == 0:
# [select, 39] -> [select]
pred = pred.argmax(1)
correct = (pred == y).sum().item()
accuracy = correct / len(pred)
lr = optim.param_groups[0]['lr']
print(epoch, i, lr, loss.item(), accuracy)
# break
2 6000 0.002 4.899007421954593e-09 1.0 2 7000 0.002 7.94727483821589e-09 1.0 2 8000 0.002 3.3674937838235053e-10 1.0 2 9000 0.002 0.0 1.0 2 10000 0.002 0.0 1.0 2 11000 0.002 0.0 1.0 2 12000 0.002 6.549960018809031e-10 1.0 |
# 预测函数
def predict1(x):
# x = [1, 50]
model.eval()
# [1, 1, 50, 50]
mask_pad_x = mask_pad(x)
with torch.no_grad():
# x编码,添加位置信息
# [1, 50] -> [1, 50, 32]
x = model.embed_x(x)
# 编码层计算,维度不变
# #[batch_size,seq_len,embedding_dim]
x = model.encoder(x, mask_pad_x)
y_out = model.fc_out(x) #[batch_size,seq_len,num_embeddings]
out = y_out.argmax(dim=2).detach()
return out
for i, (X, y) in enumerate(loader):
print(X.shape,y.shape) #torch.Size([8, 50]) torch.Size([8, 50])
print(index2seq(X[0].tolist()))
print(index2seq(y[0].tolist()))
pred = predict1(X)
print(index2seq(pred[0].tolist()))
break
torch.Size([8, 50]) torch.Size([8, 50]) vvbpkipnymdaech9hhekbanzi4qbczbkfqsxwvl5 VVBPKIPNYMDAECH0HHEKBANZI5QBCZBKFQSXWVL4 VVBPKIPNYMDAECH0HHEKBANZI5QBCZBKFQSXWVL4 |
参考