torch nn.Embedding 举例
|
依据最大索引转向量:在最后一维上增加一个维度,将索引转化为一个浮点向量
import torch
from torch import nn
embedding = nn.Embedding(num_embeddings=8,
embedding_dim=3,
padding_idx=0)
index = torch.tensor([1,3,5,7])
print(embedding(index).shape) #torch.Size([4, 3])
|
import torch
from torch import nn
embedding = nn.Embedding(num_embeddings=8,
embedding_dim=3,
padding_idx=0)
index = torch.tensor([[1,3,5,7],[1,3,0,0]])
index=index.permute(1,0)
print(embedding(index).shape) #torch.Size([4, 2, 3])
|
|
manual_seed
import torch
from torch import nn
# 固定随机种子(关键步骤)
torch.manual_seed(42) # 可以是任意整数,但选定后要保持一致
embedding = nn.Embedding(num_embeddings=8,
embedding_dim=3,
padding_idx=0)
# 此时 embedding 的权重是固定的
index = torch.tensor([1, 3, 5, 7])
embed = embedding(index)
print(embed.shape) # torch.Size([4, 3])
embed
torch.Size([4, 3])
tensor([[-2.1055, 0.6784, -1.2345],
[-0.6866, -0.4934, 0.2415],
[-0.2168, -0.3097, -0.3957],
[-0.0631, -0.8286, 0.3309]], grad_fn=EmbeddingBackward0)
直接初始化 nn.Embedding 的权重(更精确控制)
import torch
from torch import nn
# 自定义固定的初始化权重(示例:简单递增的值)
fixed_weight = torch.tensor([
[0.0, 0.0, 0.0], # padding_idx=0 的向量(全零)
[0.1, 0.1, 0.1], # index=1
[0.2, 0.2, 0.2], # index=2
[0.3, 0.3, 0.3], # index=3
[0.4, 0.4, 0.4], # index=4
[0.5, 0.5, 0.5], # index=5
[0.6, 0.6, 0.6], # index=6
[0.7, 0.7, 0.7], # index=7
])
embedding = nn.Embedding(num_embeddings=8,
embedding_dim=3,
padding_idx=0)
embedding.weight.data = fixed_weight # 直接赋值
index = torch.tensor([1, 3, 5, 7])
embed = embedding(index)
print(embed.shape) # torch.Size([4, 3])
print(embed)
关键点说明 torch.manual_seed(seed) 设置随机种子后,nn.Embedding 的权重初始化会固定,但每次修改代码或运行环境变化时可能仍会不同。 直接赋值 weight.data 完全控制权重值,适合需要可重复实验的场景(例如论文复现)。 padding_idx 的影响 如果指定了 padding_idx(如本例的 0),对应索引的向量会始终为全零,不受随机种子影响。 |
|
|
|
nn.Embedding
|
num_embeddings nn.Embedding中num_embeddings理论上指索引的个数, 但这有个前提,索引编码从0开始,并且一个连一个, 不能跳跃,一般情况下也不会跳跃,但跳跃也没有关系 实际上num_embeddings指提供的索引中的最大值 比如,本例如果num_embeddings低于8将报错,而实际上的索引个数只有4个 正常情况下索引编码都是从0开始,也无跳跃
|
|
nn.Embedding模板类生成的对象 import torch from torch import nn embedding = nn.Embedding(num_embeddings=6,embedding_dim=3,padding_idx=0) batch_vec = torch.arange(start=0,end=6,step=1).reshape(2,3) embedding(batch_vec).shape # torch.Size([2, 3, 3]) 该对象将索引矩阵升了一维,所升的这一维就是索引所转向量的维度, pytorch的维度是这样的(dim=0,dim=1), 升的这一维默认放在更高的维度,就是(dim=0,dim=1,dim=2)
|
|
随机性与有效性:起点是随机的,终点是有效的(但不一定是最好的,)
import torch
from torch import nn
embedding = nn.Embedding(num_embeddings=6,embedding_dim=3,padding_idx=0)
batch_vec = torch.arange(start=0,end=6,step=1).reshape(2,3)
embedding(batch_vec)
tensor([[[ 0.0000, 0.0000, 0.0000],
[-0.9986, 0.2995, -1.3050],
[-0.8627, 0.4689, -0.1170]],
[[-0.3458, 1.2517, -0.7372],
[ 0.4307, -0.3824, 0.1640],
[-1.2211, 1.0763, 1.4638]]], grad_fn=EmbeddingBackward0)
AI所要训练的参数是在定义nn.Embedding模板类时初始化的 nn.Embedding模板类在初始化参数时,是随机的, 这样随机地将一个整数索引转换为n维浮点向量,有效吗? 其实它的思想跟神经网络层的思想是一样的,参数随机初始化, 在训练时梯度下降,逐步向不随机的方向,就是标签的方向靠近 随机当然是无效的,训练后才有效 |
|
|
|
索引Embedding
import numpy as np
from tpf.nlp import IndexEmbed
embed = IndexEmbed()
index = np.array([1,2,3])
embed.embedding(index,embedding_dim=2)
tensor([[ 0.7980, -0.0897],
[ 0.0561, 0.2836],
[-0.5602, 1.4158]])
embed.embedding(index,embedding_dim=5)
tensor([[-0.8093, -2.0782, -1.1509, 0.5586, -3.9801],
[-0.6414, -1.3621, 0.1242, -1.0882, 0.4275],
[ 0.5396, -0.7445, 0.6825, 0.5504, -1.4078]])
embedding_dim 映射到6维及以上维度时,还需要指定 num_embeddings
或者说,需要更加灵活的映射关系时,指定embedding_dim,num_embeddings
本功能的关键是
- 记录参数文件,格式为 f"embed_{num_embeddings}_{embedding_dim}"
- 第二次加载时,相同的索引会生成相同的向量
embed.embedding(index, embedding_dim=6, num_embeddings=100000)
指定文件前缀
import numpy as np
from tpf.nlp import IndexEmbed
embed = IndexEmbed(file_pre="/tmp/embed")
index = np.array([1,2,3])
embed.embedding(index,embedding_dim=2)
生成文件 $ ls -ltrh /tmp/embed_* -rw-rw-r-- 1 llm llm 2.1K Jul 4 17:15 /tmp/embed_9_2 -rw-rw-r-- 1 llm llm 3.2K Jul 4 17:15 /tmp/embed_99_3 -rw-rw-r-- 1 llm llm 18K Jul 4 17:15 /tmp/embed_999_4 -rw-rw-r-- 1 llm llm 20M Jul 4 17:15 /tmp/embed_999999_5 -rw-rw-r-- 1 llm llm 2.3M Jul 4 17:15 /tmp/embed_100000_6 可以看到num_embeddings越大时,参数占用的空间也是越大的 file_pre为None则表示不记录文件
import numpy as np
from tpf.nlp import IndexEmbed
embed = IndexEmbed()
index = np.array([1,2,3])
embed.embedding(index,embedding_dim=2)
tensor([[ 0.7980, -0.0897],
[ 0.0561, 0.2836],
[-0.5602, 1.4158]])
此时生成随机向量仍然是固定的,因为设置了随机种子,但这种固定没有存储为文件靠谱
- 可能重启服务或修改代码生成的随机向量就变了
|
|
添加forward方法
import numpy as np
from tpf.nlp import IndexEmbed
embed = IndexEmbed()
index = np.array([1,2,3])
embed(index)
tensor([[ 0.7980, -0.0897],
[ 0.0561, 0.2836],
[-0.5602, 1.4158]])
embed(index,embedding_dim=3)
tensor([[-0.0369, -1.0962, 0.0523],
[ 1.1494, 0.5489, 0.6164],
[ 0.9435, -0.7968, -2.2954]])
embed(index,embedding_dim=3,num_embeddings=1000)
tensor([[-0.0369, -1.0962, 0.0523],
[ 1.1494, 0.5489, 0.6164],
[ 0.9435, -0.7968, -2.2954]])
---------------------------------------------------------------------------------- |
import numpy as np
import pandas as pd
import torch
from torch import nn
# 设置随机种子以便结果可复现
np.random.seed(42)
columns = ['feature_value_1', 'is_feature_value_535', 'is_feature_value_536']
data = {
col: np.random.randint(0, 10, size=5) for col in columns
}
df = pd.DataFrame(data)
df
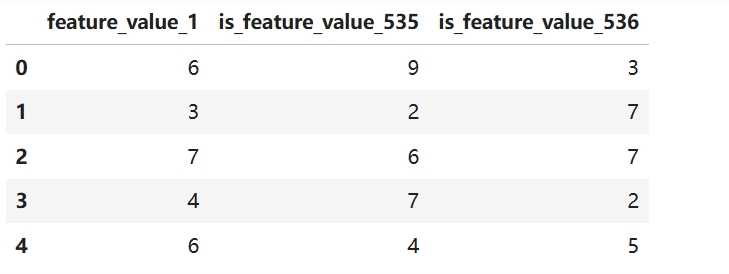
from tpf.nlp import ClsIndexEmbed
cls_dim_dict = {
'is_feature_value_535': 3,
'is_feature_value_536': 2
}
cie = ClsIndexEmbed()
df =cie(df,cls_dim_dict)
df
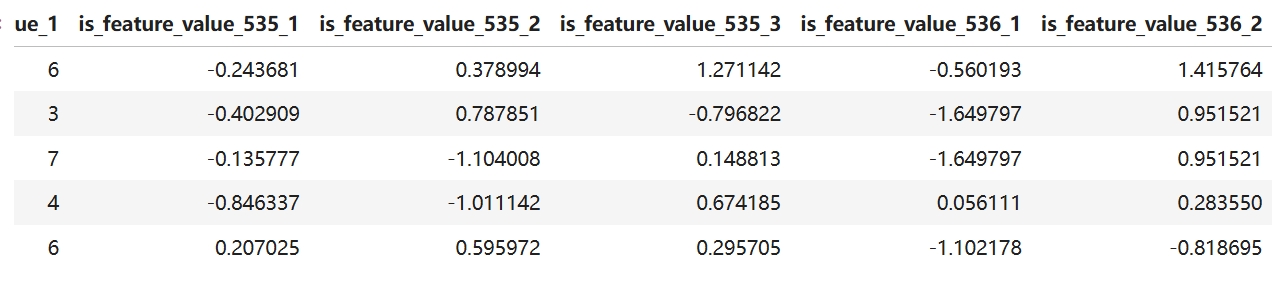
指定文件前缀:如此索引编码永久固定 cie = ClsIndexEmbed(file_pre="/tmp/aa/embed") df =cie(df,cls_dim_dict) df llm@ii:/opt/wks/aitpf$ ls -ltrh /tmp/aa/ total 20M -rw-rw-r-- 1 llm llm 2.1K Jul 9 16:15 embed_10_2 -rw-rw-r-- 1 llm llm 3.2K Jul 9 16:15 embed_100_3 -rw-rw-r-- 1 llm llm 18K Jul 9 16:15 embed_1000_4 -rw-rw-r-- 1 llm llm 20M Jul 9 16:15 embed_1000000_5 |
|
|
|
|
参考