bm25
```
from tpf.nlp.text import BM25Reranker
import pandas as pd
data_path = "/ai/wks/alg/data/tousu/label10_sum_key_yshi.csv"
df = pd.read_csv(data_path)
print(df.columns.tolist()) # ['text', 'label', 'label_text_count', 'text_len', 'label_len']
use_cols = ['text', 'label']
df = df[use_cols]
print(df.shape)
# 将df按行复制100倍,然后取前10万行
df = pd.concat([df] * 100, ignore_index=True)
df = df.iloc[:100100]
print(f"复制后的数据形状: {df.shape}")
query_texts = df.iloc[:100]['text']
df = df.iloc[100:]
import time
# 统计BM25初始化和相似度计算的执行时间
start_time = time.time()
bm25 = BM25Reranker(df, use_cols=use_cols)
init_time = time.time() - start_time
print(f"BM25初始化耗时: {init_time:.3f}秒")
# 统计所有查询的总耗时和平均耗时
total_sim_time = 0
query_count = 0
for idx, query_text in enumerate(query_texts, 1):
print(f"[{idx}/{len(query_texts)}] {query_text}")
start_time = time.time()
scores = bm25.sim_scores(query_text)
sim_time = time.time() - start_time
total_sim_time += sim_time
query_count += 1
print(f" 相似度计算耗时: {sim_time:.3f}秒")
# 计算统计数据
avg_sim_time = total_sim_time / query_count if query_count > 0 else 0
total_time = init_time + total_sim_time
print("\n" + "="*60)
print("性能统计:")
print(f" BM25初始化耗时: {init_time:.3f}秒")
print(f" 查询总耗时: {total_sim_time:.3f}秒")
print(f" 查询次数: {query_count}")
print(f" 平均每次查询耗时: {avg_sim_time:.3f}秒")
print(f" 总耗时: {total_time:.3f}秒")
print("="*60)
print(type(scores),scores[:3])
```
============================================================
性能统计:
BM25初始化耗时: 17.095秒
查询总耗时: 132.396秒
查询次数: 100
平均每次查询耗时: 1.324秒
总耗时: 149.490秒
============================================================
|
|
按进程
$ ps aux --sort=-%mem
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
xt 11227 99.9 4.1 5927072 1345176 pts/7 Rl+ 16:04 1:11 python demo1.py
$ ps aux --sort=-%mem | head -20
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
xt 11227 99.9 4.1 5927072 1345176 pts/7 Rl+ 16:04 1:11 python demo1.py
真正“占了多少物理内存”直接看 RSS 字段即可;
如果想换算成“多少 GB”:RSS ÷ 1024 ÷ 1024 ≈ GB。
(你的例子:1 345 176 KB ≈ 1.28 GB)
``` 字段从左到右依次是: USER 进程所属用户名 PID 进程号(唯一标识) %CPU 过去一段时间内该进程占用 单核 CPU 的百分比(>100% 表示用了多核) %MEM 该进程实际物理内存(RSS)占 整机总内存 的百分比 VSZ Virtual Set Size,进程申请的 虚拟地址空间 总量(KB),包含未实际分配的页 RSS Resident Set Size,进程当前 真正占用的物理内存(KB),包含共享库实际映射的部分 TTY 进程关联的终端(? 表示守护进程或无终端;pts/7 表示伪终端第 7 号) STAT 进程状态码: R 正在运行或可运行 l 多线程 + 前台进程组 组合起来 Rl+ 表示“多线程、正在运行、前台组” START 进程启动时刻(16:04 即今天 16:04) TIME 累计占用的 CPU 时间(1:11 = 1 分 11 秒) COMMAND 启动命令行(这里看到是 python demo1.py) 以你的输出为例: 进程 11227 是用户 xt 运行的 Python 脚本,目前 CPU 打满(99.9%),占 整机内存 4.1%(约 1.3 GB RSS)。 ```
| 口径 | 来源字段 | 含义 | 是否包含共享库 | 是否含未分配页 | 适用场景 |
| ---------- | -------------- | --------------- | -------------- | ------- | ------------ |
| **物理常驻** | `RSS` | 进程**实际占用的物理内存** | 含共享库**实际映射部分** | 不含 | 快速看“吃掉了多少内存” |
| **虚拟地址空间** | `VSZ` | 进程申请的总地址空间大小 | 含 | 含未分配页 | 看“有没有申请过大地址” |
| **比例分摊** | `smem` 的 `PSS` | 把共享库按使用人数均摊后的大小 | 均摊 | 不含 | 更公平地比较多个进程 |
| **整机百分比** | `%MEM` | `RSS / 机器总物理内存` | 已包含在 RSS 里 | 不含 | 一眼看占整机比例 |
- top -o %MEM -d 3 - htop |
|
|
|
|
|
|
|
|
|
|
|
|
gensim简介
Gensim是一个开源的Python库,专门用于处理文本数据和主题建模。
它提供了强大的工具来实现Word2Vec等词嵌入模型。
pip install gensim
中文举例
import jieba
from gensim.models import Word2Vec
text = "我爱自然语言处理,自然语言处理很有趣。"
# 使用jieba进行分词
words = list(jieba.cut(text))
# 将分词结果转换为列表形式,因为Word2Vec模型需要以句子(单词列表)的形式输入
sentences = [words] #[['我', '爱', '自然语言', '处理', ',', '自然语言', '处理', '很', '有趣', '。']]
Word2Vec参数
vector_size:词向量的维度,这里设置为100。
window:上下文窗口大小,表示当前单词和周围单词的关联范围,这里设置为5。
min_count:单词最少出现的次数,小于该次数的单词会被忽略,这里设置为1。
workers:训练时使用的线程数,这里设置为4。
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4) vector = model.wv['自然语言'] print(vector)
[-8.6196875e-03 3.6657380e-03 5.1898835e-03 5.7419385e-03
7.4669183e-03 -6.1676754e-03 1.1056137e-03 6.0472824e-03
-2.8400505e-03 -6.1735227e-03 -4.1022300e-04 -8.3689485e-03
-5.6000124e-03 7.1045388e-03 3.3525396e-03 7.2256695e-03
6.8002474e-03 7.5307419e-03 -3.7891543e-03 -5.6180597e-04
2.3483764e-03 -4.5190323e-03 8.3887316e-03 -9.8581640e-03
6.7646410e-03 2.9144168e-03 -4.9328315e-03 4.3981876e-03
-1.7395747e-03 6.7113843e-03 9.9648498e-03 -4.3624435e-03
-5.9933780e-04 -5.6956373e-03 3.8508223e-03 2.7866268e-03
6.8910765e-03 6.1010956e-03 9.5384968e-03 9.2734173e-03
7.8980681e-03 -6.9895042e-03 -9.1558648e-03 -3.5575271e-04
-3.0998408e-03 7.8943167e-03 5.9385742e-03 -1.5456629e-03
1.5109634e-03 1.7900408e-03 7.8175711e-03 -9.5101865e-03
-2.0553112e-04 3.4691966e-03 -9.3897223e-04 8.3817719e-03
9.0107834e-03 6.5365066e-03 -7.1162102e-04 7.7104042e-03
-8.5343346e-03 3.2071066e-03 -4.6379971e-03 -5.0889552e-03
3.5896183e-03 5.3703394e-03 7.7695143e-03 -5.7665063e-03
7.4333609e-03 6.6254963e-03 -3.7098003e-03 -8.7456414e-03
5.4374672e-03 6.5097557e-03 -7.8755023e-04 -6.7098560e-03
-7.0859254e-03 -2.4970602e-03 5.1432536e-03 -3.6652375e-03
-9.3700597e-03 3.8267397e-03 4.8844791e-03 -6.4285635e-03
1.2085581e-03 -2.0748770e-03 2.4403334e-05 -9.8835090e-03
2.6920044e-03 -4.7501065e-03 1.0876465e-03 -1.5762246e-03
2.1966731e-03 -7.8815762e-03 -2.7171839e-03 2.6631986e-03
5.3466819e-03 -2.3915148e-03 -9.5100943e-03 4.5058788e-03]
len(vector) # 100
|
import jieba
from gensim.models import Word2Vec
# 示例文本
texts = ["我喜欢学习自然语言处理", "机器学习和深度学习是人工智能的一部分", "自然语言处理很有意思"]
# 使用jieba进行分词
cut_texts = [list(jieba.cut(text)) for text in texts]
# 训练Word2Vec模型
model = Word2Vec(cut_texts, vector_size=100, window=5, min_count=1, workers=4)
# 查找与'学习'最相似的词
similar_words = model.wv.most_similar('学习')
print(similar_words)
[('深度', 0.21617145836353302), ('喜欢', 0.0931011214852333), ('人工智能', 0.09291722625494003), ('机器', 0.07963486760854721), ('和', 0.06285078078508377), ('是', 0.027064507827162743), ('的', 0.01613466814160347), ('处理', -0.010839181020855904), ('很', -0.027750367298722267), ('我', -0.041253406554460526)]
按相似程序降序排序,可以看到,前五个词都是喜欢附近出现过的词,离“学习”这个单词的距离较近
|
Word2Vec 是 gensim 库中用于训练词向量的模型, 它基于 Skip-gram 或 CBOW 架构,将单词映射到低维稠密向量空间。 以下是其核心参数的解释,特别是 negative 和 compute_loss 的详细说明:
参数 默认值 说明
vector_size 100 词向量的维度(通常 50-300)。
window 5 上下文窗口大小(左右各取 window 个词)。
min_count 5 忽略词频低于此值的单词。
workers 3 并行训练线程数。
sg 0 训练算法:0 = CBOW(默认)1 = Skip-gram。
hs 0 是否使用 Hierarchical Softmax:0 = 禁用(默认),1 = 启用。
negative 5 负采样数(仅当 hs=0 时生效)。
negative 作用: 指定负采样(Negative Sampling)的数量,用于优化训练效率。 原理: 传统 Softmax 计算所有词的得分,计算量大。 负采样仅对 目标词(正样本) 和随机采样的 negative 个负样本 计算损失。 负样本从词频分布中采样(高频词更易被选为负样本)。 如何设置: 小数据集:negative=5~20。 大数据集:negative=2~5(太多负样本会降低性能)。 model = Word2Vec(sentences, negative=10) # 使用10个负样本 compute_loss 作用: 是否在训练过程中计算并存储损失值(可通过 model.get_latest_training_loss() 获取)。 原理: 启用后会略微增加计算开销,但便于监控训练过程。 损失值反映模型对正/负样本的区分能力。 model = Word2Vec(sentences, compute_loss=True) print(model.get_latest_training_loss()) # 输出当前损失 其他重要参数
参数 说明
alpha 初始学习率(默认 0.025)。
min_alpha 学习率衰减下限(线性衰减到该值)。
epochs 迭代次数(默认 5)。
sample 高频词随机下采样的阈值(如 1e-3)。
cbow_mean CBOW 中是否对上下文词向量取平均(默认 1)。
完整示例
from gensim.models import Word2Vec
sentences = [["I", "love", "NLP"], ["Word2Vec", "is", "powerful"]]
model = Word2Vec(
sentences,
vector_size=200, # 词向量维度
window=5, # 上下文窗口
min_count=1, # 忽略低频词
sg=1, # 使用 Skip-gram
hs=0, # 禁用 Hierarchical Softmax
negative=10, # 负采样数
compute_loss=True, # 记录损失
workers=4 # 并行线程
)
# 获取词向量
print(model.wv["NLP"])
# 获取训练损失
print(model.get_latest_training_loss())
|
|
核心思想 用上下文单词预测中心词(适合小型数据集和频繁词)。 输入:周围上下文单词(例如窗口内的词)。 输出:预测中心词。 结构: 上下文单词的词向量 求平均(或拼接)→ 输入隐藏层 → Softmax 输出目标词概率。 数学表达 
特点 优点: 训练速度快(尤其对高频词)。 对小型数据集更鲁棒。 缺点: 上下文词的平均操作会丢失位置信息。 对低频词表现较差。 |
|
核心思想 用中心词预测周围上下文单词(适合大型数据集和稀有词)。 输入:中心词。 输出:预测窗口内的每个上下文词。 结构: 中心词的词向量 → 隐藏层 → 多个 Softmax 输出(每个上下文词独立预测) 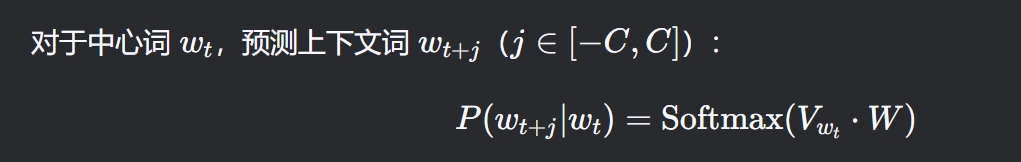
特点 优点: 能更好地捕捉稀有词的语义。 适合大规模数据。 缺点: 训练速度较慢(需预测多个上下文词)。 关键对比 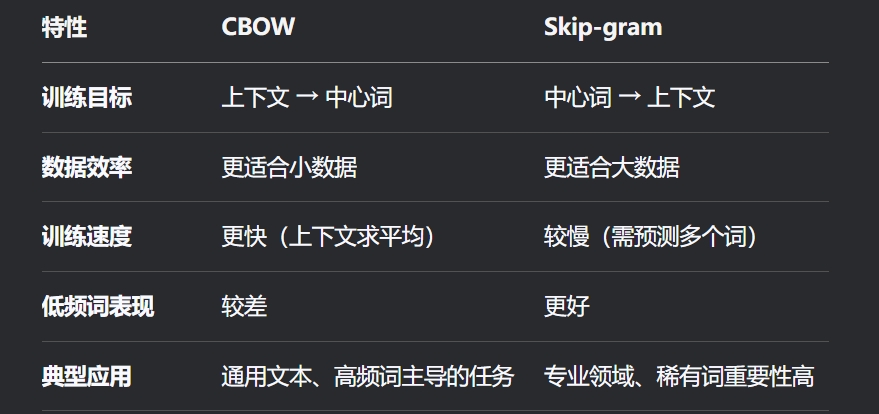
|
数据量小 → 优先用 CBOW(更快收敛)。 数据量大或关注稀有词 → 优先用 Skip-gram(效果更好)。 超参数建议: Skip-gram: sg=1, window=10, negative=5~15 CBOW: sg=0, window=5, negative=2~5 代码示例(Gensim 实现)
from gensim.models import Word2Vec
sentences = [["natural", "language", "processing"], ["word", "embeddings", "are", "powerful"]]
# Skip-gram 模型
model_sg = Word2Vec(sentences, sg=1, vector_size=100, window=5, min_count=1)
# CBOW 模型
model_cbow = Word2Vec(sentences, sg=0, vector_size=100, window=5, min_count=1)
# 获取词向量
print("Skip-gram 向量:", model_sg.wv["language"])
print("CBOW 向量:", model_cbow.wv["language"])
|
|
|
gensim·API
|
使用Word2Vec训练一个模型 1. 分词生成单词列表,这是Word2Vec的数据输入 2. 超参数建议: Skip-gram: sg=1, window=10, negative=5~15 - 大规模数据集 CBOW: sg=0, window=5, negative=2~5 - 小规模数据集
Word2Vec根据输入单词的顺序训练模型,位置相近的单词相似度高
import jieba
from gensim.models import Word2Vec
text = "我爱自然语言处理,自然语言处理很有趣。"
words = list(jieba.cut(text))
sentences = [words] # [['我', '爱', '自然语言', '处理', ',', '自然语言', '处理', '很', '有趣', '。']]
# vector_size:词向量的维度,这里设置为100。
# window:上下文窗口大小,表示当前单词和周围单词的关联范围,这里设置为5。
# min_count:单词最少出现的次数,小于该次数的单词会被忽略,这里设置为1。
# workers:训练时使用的线程数,这里设置为4。
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)
|
|
取单词的向量
type(model.wv) # gensim.models.keyedvectors.KeyedVectors
相当于python dict
vector = model.wv['自然语言'] vector.shape # (100,) type(vector) # numpy.ndarray |
|
model.wv.most_similar import jieba from gensim.models import Word2Vec texts = ["我喜欢学习自然语言处理", "机器学习和深度学习是人工智能的一部分", "自然语言处理很有意思"] cut_texts = [list(jieba.cut(text)) for text in texts] model = Word2Vec(cut_texts, vector_size=100, window=5, min_count=1, workers=4)
similar_words = model.wv.most_similar('学习')
similar_words
[('深度', 0.21617145836353302),
('喜欢', 0.0931011214852333),
('人工智能', 0.09291722625494003),
('机器', 0.07963486760854721),
('和', 0.06285078078508377),
('是', 0.027064507827162743),
('的', 0.01613466814160347),
('处理', -0.010839181020855904),
('很', -0.027750367298722267),
('我', -0.041253406554460526)]
相似度从高到低,从正到负排列 |
|
|
|
|
jieba
|
三种模式
- 精确模式 试图将句子最精确地切开,适合文本分析(默认模式)
- 全模式 把句子中所有可能的词语都扫描出来,速度快但不能解决歧义
- 搜索引擎模式 在精确模式基础上,对长词再次切分,提高召回率,适用于搜索引擎分词
- pip install jieba
```
import jieba
text = "我来到北京清华大学"
# 精确模式
print("精确模式:", "/".join(jieba.cut(text, cut_all=False))) #默认模式
# 全模式
print("全模式:", "/".join(jieba.cut(text, cut_all=True)))
# 搜索引擎模式
print("搜索引擎模式:", "/".join(jieba.cut_for_search(text)))
```
```
精确模式: 我/来到/北京/清华大学
全模式: 我/来到/北京/清华/清华大学/华大/大学
搜索引擎模式: 我/来到/北京/清华/华大/大学/清华大学
```
|
|
jieba.add_word(word, freq=None, tag=None)
```
import jieba
text = "Moonshot AI 是一家致力于大模型研发的公司"
# 添加自定义词
jieba.add_word("Moonshot AI")
jieba.add_word("大模型")
# 分词
print("/".join(jieba.cut(text)))
```
```
添加前: Moonshot/ AI/ 是/ 一家/ 致力于/ 大/ 模型/ 研发/ 的/ 公司
添加后: Moonshot AI/ 是/ 一家/ 致力于/ 大模型/ 研发/ 的/ 公司
```
加载自定义词典文件(适合批量添加)
- 创建一个文本文件,比如 my_dict.txt,每行一个词,格式如下:
```
jieba.load_userdict("my_dict.txt")
```
- 添加单个词 jieba.add_word("词")
- 批量添加 jieba.load_userdict("文件路径")
- 删除词 jieba.del_word("词")
- 调整词频 jieba.suggest_freq("词", tune=True)
|
|
|
|
|
|
|
hanlp
HanLP 是一个功能全面、性能高效的自然语言处理工具包,支持包括中文分词、词性标注、命名实体识别以及自动摘要在内的多种任务。借助其内置的 TextRank 等算法,HanLP 可以方便地从长文本中提取关键句,生成简洁的摘要 - pip install pyhanlp - https://hanlp.hankcs.com/install.html - 首次使用时,它需要下载数据包和模型
```
from pyhanlp import *
# 准备你的文本
document = (
"自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。"
"它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。"
"自然语言处理是一门融语言学、计算机科学、数学于一体的科学。"
"因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,"
"所以它与语言学的研究有着密切的联系,但又有重要的区别。"
"自然语言处理并不是一般地研究自然语言,"
"而在于研制能有效地实现自然语言通信的计算机系统,"
"特别是其中的软件系统。因而它是计算机科学的一部分。"
)
# 使用 HanLP 提取摘要
# extractSummary 函数用于从文本中提取最重要的几个句子作为摘要
# 参数 document: 待摘要的文本
# 参数 3: 指定要提取的摘要句子的数量
summary_sentences = HanLP.extractSummary(document, 3)
# 打印生成的摘要
print("生成的摘要:")
for sentence in summary_sentences:
print("-", sentence)
```
|
- https://hanlp.com/semantics/functionapi/participle
- https://github.com/hankcs/HanLP/tree/doc-zh
```
# 建议新建虚拟环境
python -m venv venv && source venv/bin/activate
pip install -U hanlp # 基础包
# 如需 GPU 加速(可选)
pip install hanlp[gpu] # 会自动安装 cuda 版 onnxruntime-gpu [^14^]
```
抽取式摘要(TextRank,最快)
- HanLP 采用“即用即下”策略,脚本里第一次 hanlp.load() 会自动缓存到 ~/.hanlp/(约 1.1 GB)。
生成式摘要( fine-tuned BART,最自然)
|
```
from tpf.lgg.hlp import HLP
lp = HLP()
text="""
客户致电反馈自己有我行记卡,但卡片被我行冻结已经有一周多的时间,之前客户去了网点,要求我行出具具体的冻结说明,但我行告知客户无法出具,后来客户表示我行给其打了电话,态度特别不好,之前有反馈过,但是没有解决问题,现在客户要求继续投诉,不要协商,只要明确的解决方案,请协助处理,谢谢客户姓名:刘联系方式***0*8*6***涉及支行:大连分行营业部证件号和卡号2*028*********64**
"""
ll = lp.summary(text,top=5)
for l in ll:
print(l)
```
``` 客户致电反馈自己有我行记卡 要求我行出具具体的冻结说明 但我行告知客户无法出具 之前客户去了网点 之前有反馈过 ``` |
```
import os
import jpype
# 检查JAVA_HOME是否配置
java_home = os.environ.get('JAVA_HOME')
print(f"JAVA_HOME: {java_home}")
# 尝试手动启动JVM - 使用最简单的方式
try:
if not jpype.isJVMStarted():
# 添加JPype的jar包路径到环境变量
import jpype.config
print(f"JPype版本: {jpype.__version__}")
# 使用最简单的启动方式,让JPype自动查找JVM和jar包
print("尝试启动JVM...")
jpype.startJVM()
print("JVM启动成功")
else:
print("JVM已经启动")
# 测试基本的Java功能
print("测试基本Java功能...")
java_lang_System = jpype.JClass("java.lang.System")
java_lang_String = jpype.JClass("java.lang.String")
print(f"Java版本: {java_lang_System.getProperty('java.version')}")
test_str = java_lang_String("测试字符串")
print(f"Java String测试成功: {test_str.toString()}")
# 测试HanLP功能
try:
from pyhanlp import HanLP
result = HanLP.segment("你好,世界!")
print(f"HanLP分词结果: {result}")
except ImportError as e:
print(f"导入pyhanlp失败: {e}")
print("这可能是因为pyhanlp未正确安装或配置")
except Exception as e:
print(f"HanLP调用失败: {e}")
except Exception as e:
print(f"JVM启动失败: {str(e)}")
print("\n可能的解决方案:")
print("1. 重新安装JPype: pip uninstall jpype1 && pip install JPype1")
print("2. 检查Java版本兼容性")
print("3. 设置CLASSPATH环境变量")
print("4. 尝试使用pyhanlp内置的JVM管理")
# 尝试使用pyhanlp的方式启动
try:
print("\n尝试使用pyhanlp自动启动JVM...")
import pyhanlp
result = pyhanlp.HanLP.segment("你好,世界!")
print(f"pyhanlp自动启动成功: {result}")
except Exception as e2:
print(f"pyhanlp自动启动也失败: {e2}")
finally:
try:
if jpype.isJVMStarted():
# 延迟关闭,避免某些版本的bug
import time
time.sleep(0.1)
jpype.shutdownJVM()
print("JVM已关闭")
except Exception as e:
print(f"关闭JVM时出错: {e}")
print("这通常是JPype版本兼容性问题,可以忽略")
```
- 原来的JDK8是可用的,但现在不行了,报org.jpype.com包找不到 - 本次安装使用openjdk-21,就不报这个错了 |
```
'ner/msra': [('张三', 'PERSON', 1, 2),
('刘', 'PERSON', 91, 92),
('***0*8', 'DECIMAL', 94, 95),
('6', 'INTEGER', 96, 97),
('大连分行营业部', 'ORGANIZATION', 103, 106),
('2*', 'INTEGER', 109, 110),
('028', 'INTEGER', 110, 111),
('64', 'INTEGER', 120, 121)],
'ner/pku': [('张三', 'nr', 1, 2),
('刘', 'nr', 91, 92),
('大连分行营业部', 'nt', 103, 106)],
'ner/ontonotes': [('张三', 'PERSON', 1, 2),
('一周', 'DATE', 16, 18),
('刘', 'PERSON', 91, 92),
('6', 'CARDINAL', 96, 97),
('大连分行', 'ORG', 103, 105),
('2*', 'CARDINAL', 109, 110),
('028', 'CARDINAL', 110, 111),
('64', 'CARDINAL', 120, 121)],
```
- pip install hanlp
```
import hanlp
HanLP = hanlp.load(hanlp.pretrained.mtl.CLOSE_TOK_POS_NER_SRL_DEP_SDP_CON_ELECTRA_SMALL_ZH) # 世界最大中文语料库
text="""
客户张三致电反馈自己有我行记卡,但卡片被我行冻结已经有一周多的时间,之前客户去了网点,要求我行出具具体的冻结说明,但我行告知客户无法出具,后来客户表示我行给其打了电话,态度特别不好,之前有反馈过,但是没有解决问题,现在客户要求继续投诉,不要协商,只要明确的解决方案,请协助处理,谢谢客户姓名:刘联系方式***0*8*6***涉及支行:大连分行营业部证件号和卡号2*028*********64**
"""
res = HanLP(text)
```
- res['ner/msra'],可以利用这个将客户名称与卡号,手机号等数字全部提取出来,然后抹去
```
res['ner/msra']
[('张三', 'PERSON', 1, 2),
('刘', 'PERSON', 91, 92),
('***0*8', 'DECIMAL', 94, 95),
('6', 'INTEGER', 96, 97),
('大连分行营业部', 'ORGANIZATION', 103, 106),
('2*', 'INTEGER', 109, 110),
('028', 'INTEGER', 110, 111),
('64', 'INTEGER', 120, 121)]
```
NER/MSRA 中的 MSRA 是 Microsoft Research Asia(微软亚洲研究院)的缩写。
在中文自然语言处理领域,MSRA 发布了一个广泛用于命名实体识别(NER)任务的数据集,
通常就被简称为“MSRA 数据集”或“MSRA NER 数据”。
这个数据集专注于中文文本,包含人名(PER)、地名(LOC)和机构名(ORG)三类实体,
是中文 NER 研究的重要基准之一 。
一个完整的基于 Transformers 库的 MSRA NER 训练代码:
```
import os
import numpy as np
from datasets import load_dataset
from transformers import (
AutoTokenizer,
AutoModelForTokenClassification,
TrainingArguments,
Trainer,
DataCollatorForTokenClassification
)
from transformers.trainer_utils import set_seed
import torch
from seqeval.metrics import classification_report, f1_score
# 设置随机种子
set_seed(42)
class MSRA_NER_Trainer:
def __init__(self, model_name="hfl/chinese-bert-wwm-ext", output_dir="./msra-ner-output"):
self.model_name = model_name
self.output_dir = output_dir
self.tokenizer = None
self.model = None
self.dataset = None
# MSRA NER 标签映射 (BIO格式)
self.label_list = ['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC']
self.label2id = {label: i for i, label in enumerate(self.label_list)}
self.id2label = {i: label for i, label in enumerate(self.label_list)}
def load_and_preprocess_data(self):
"""加载和预处理MSRA NER数据集"""
print("正在加载MSRA NER数据集...")
# 方法1: 使用HuggingFace datasets(如果可用)
try:
self.dataset = load_dataset("msra_ner")
print("数据集加载成功!")
except:
# 方法2: 手动加载(需要本地数据文件)
print("在线加载失败,使用本地数据加载方式...")
self.dataset = self._load_local_data()
# 加载tokenizer
self.tokenizer = AutoTokenizer.from_pretrained(self.model_name)
# 预处理数据
print("正在预处理数据...")
self.dataset = self.dataset.map(
self.tokenize_and_align_labels,
batched=True,
remove_columns=self.dataset["train"].column_names
)
print(f"训练集大小: {len(self.dataset['train'])}")
print(f"测试集大小: {len(self.dataset['test'])}")
def _load_local_data(self):
"""本地数据加载的替代方案"""
# 这里需要你有本地的MSRA数据文件
# 假设数据格式为CoNLL格式
def read_conll_file(file_path):
sentences, labels = [], []
current_sentence, current_labels = [], []
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
if not line: # 空行表示句子结束
if current_sentence:
sentences.append(current_sentence)
labels.append(current_labels)
current_sentence, current_labels = [], []
else:
parts = line.split()
if len(parts) >= 2:
current_sentence.append(parts[0])
current_labels.append(parts[1])
return {"tokens": sentences, "ner_tags": labels}
# 这里需要替换为你的实际文件路径
train_data = read_conll_file("msra_train.conll")
test_data = read_conll_file("msra_test.conll")
from datasets import DatasetDict, Dataset
return DatasetDict({
"train": Dataset.from_dict({"tokens": train_data["tokens"], "ner_tags": train_data["ner_tags"]}),
"test": Dataset.from_dict({"tokens": test_data["tokens"], "ner_tags": test_data["ner_tags"]})
})
def tokenize_and_align_labels(self, examples):
"""tokenize文本并对齐标签"""
tokenized_inputs = self.tokenizer(
examples["tokens"],
truncation=True,
padding=False,
is_split_into_words=True,
max_length=512,
return_tensors=None
)
labels = []
for i, label in enumerate(examples["ner_tags"]):
word_ids = tokenized_inputs.word_ids(batch_index=i)
previous_word_idx = None
label_ids = []
for word_idx in word_ids:
if word_idx is None:
# CLS, SEP等特殊token
label_ids.append(-100)
elif word_idx != previous_word_idx:
# 当前单词的第一个子词
label_name = label[word_idx]
label_ids.append(self.label2id[label_name])
else:
# 当前单词的后续子词
label_name = label[word_idx]
# 如果是B-标签,后续子词改为I-标签
if label_name.startswith("B-"):
label_name = "I-" + label_name[2:]
label_ids.append(self.label2id[label_name])
previous_word_idx = word_idx
labels.append(label_ids)
tokenized_inputs["labels"] = labels
return tokenized_inputs
def compute_metrics(self, eval_pred):
"""计算评估指标"""
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=2)
# 移除padding和特殊token的标签(-100)
true_predictions = [
[self.id2label[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
true_labels = [
[self.id2label[l] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
# 使用seqeval计算指标
return {
"f1": f1_score(true_labels, true_predictions),
}
def setup_model(self):
"""初始化模型"""
print("正在初始化模型...")
self.model = AutoModelForTokenClassification.from_pretrained(
self.model_name,
num_labels=len(self.label_list),
id2label=self.id2label,
label2id=self.label2id,
ignore_mismatched_sizes=True
)
# 打印模型参数数量
total_params = sum(p.numel() for p in self.model.parameters())
trainable_params = sum(p.numel() for p in self.model.parameters() if p.requires_grad)
print(f"总参数数: {total_params:,}")
print(f"可训练参数数: {trainable_params:,}")
def train(self):
"""训练模型"""
print("开始训练...")
# 创建输出目录
os.makedirs(self.output_dir, exist_ok=True)
# 设置训练参数
training_args = TrainingArguments(
output_dir=self.output_dir,
overwrite_output_dir=True,
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
learning_rate=2e-5,
weight_decay=0.01,
warmup_ratio=0.1,
logging_dir=f"{self.output_dir}/logs",
logging_steps=100,
eval_steps=500,
save_steps=500,
evaluation_strategy="steps",
save_strategy="steps",
load_best_model_at_end=True,
metric_for_best_model="f1",
greater_is_better=True,
report_to=None, # 禁用wandb等记录
dataloader_pin_memory=False,
)
# 数据收集器
data_collator = DataCollatorForTokenClassification(
tokenizer=self.tokenizer,
padding=True,
max_length=512,
return_tensors="pt"
)
# 创建Trainer
trainer = Trainer(
model=self.model,
args=training_args,
train_dataset=self.dataset["train"],
eval_dataset=self.dataset["test"],
data_collator=data_collator,
tokenizer=self.tokenizer,
compute_metrics=self.compute_metrics,
)
# 开始训练
print("启动训练过程...")
train_result = trainer.train()
# 保存最终模型
trainer.save_model()
trainer.save_state()
# 评估模型
print("正在评估模型...")
eval_results = trainer.evaluate()
print(f"最终评估结果: {eval_results}")
return trainer, train_result
def predict(self, text, trainer):
"""使用训练好的模型进行预测"""
# 分词
tokens = list(text) # 中文按字符分词
inputs = self.tokenizer(
tokens,
is_split_into_words=True,
return_tensors="pt",
truncation=True,
max_length=512
)
# 预测
with torch.no_grad():
outputs = trainer.model(**inputs)
predictions = torch.argmax(outputs.logits, dim=-1)[0].cpu().numpy()
# 对齐标签
word_ids = inputs.word_ids()
entities = []
current_entity = None
for i, (word_idx, pred_idx) in enumerate(zip(word_ids, predictions)):
if word_idx is not None:
label = self.id2label[pred_idx]
token = self.tokenizer.convert_ids_to_tokens(inputs["input_ids"][0][i])
if label.startswith("B-"):
if current_entity:
entities.append(current_entity)
current_entity = {
"entity": label[2:],
"score": torch.softmax(outputs.logits[0][i], dim=-1)[pred_idx].item(),
"word": token,
"start": i,
"end": i
}
elif label.startswith("I-") and current_entity and current_entity["entity"] == label[2:]:
current_entity["word"] += token.replace("##", "")
current_entity["end"] = i
elif label == "O" and current_entity:
entities.append(current_entity)
current_entity = None
if current_entity:
entities.append(current_entity)
return entities
def main():
"""主函数"""
# 初始化训练器
trainer = MSRA_NER_Trainer(
model_name="hfl/chinese-bert-wwm-ext", # 中文BERT模型
output_dir="./msra-ner-model"
)
# 加载数据
trainer.load_and_preprocess_data()
# 设置模型
trainer.setup_model()
# 训练模型
trained_trainer, train_result = trainer.train()
# 测试预测
test_texts = [
"姚明在北京的新闻发布会上表示将继续支持中国篮球事业。",
"微软亚洲研究院位于北京海淀区。",
"张三和李四在清华大学学习计算机科学。"
]
print("\n" + "="*50)
print("预测测试:")
print("="*50)
for text in test_texts:
entities = trainer.predict(text, trained_trainer)
print(f"\n文本: {text}")
print("识别出的实体:")
for entity in entities:
print(f" - {entity['entity']}: {entity['word']} (置信度: {entity['score']:.4f})")
if __name__ == "__main__":
# 检查依赖
try:
import datasets
import transformers
import seqeval
print("所有依赖已安装,开始训练...")
main()
except ImportError as e:
print(f"缺少依赖: {e}")
print("请安装所需依赖:")
print("pip install datasets transformers seqeval torch")
```
|
Data2CorrScore
|
这里以train指代已有数据,test指代将来要预测的数据
```
import pandas as pd
df = pd.read_csv("data_rank_11.csv")
df = df[['text','label']]
df = df.drop_duplicates()
print(df.shape)
df[:3]
```
fit中仅bm25需要提前加载数据
```
from tpf.data.feature.text import Data2CorrScore
tc = Data2CorrScore(model_path_rerank="/wks/models/bge-reranker-large",
model_path_ms="/wks/models/ms-marco-MiniLM-L6-v2",
feature_sim_top_k=5,
feature_label_top_k=3)
train,test = tc.data_split(df,label_name='label')
tc.fit(df=train, use_cols=['text', 'label'])
```
```
df = tc.transform(df=test,
is_train=True,
is_train_datasets_only=False,
label_name='match')
```
- 每个query_text下有三个sim_label,每个sim_label下有5条文本


- 完整示例 - text_feature_scores.ipynb |
```
import pandas as pd
df = pd.read_csv("data_label10_sum_key_yshi.csv")
df[:3]
df = df[['text','label']]
df = df.drop_duplicates()
print(df.shape)
df[:3]
```
相关性得分
```
from tpf.data.feature.text import Data2CorrScore
tc = Data2CorrScore(model_path_rerank="/wks/models/bge-reranker-large",
model_path_ms="/wks/models/ms-marco-MiniLM-L6-v2",
feature_sim_top_k=5,
feature_label_top_k=3)
```
- 仅一个数据集自身相互求分数
```
df_feature = tc.score_self(df)
```
以指定数据集自我求分数验证效果
- 生成的数据行数为df.shape[0] @ feature_sim_top_k @ feature_label_top_k
- transform是将data拆分为train,test
- train给fit,test给tranform, 是求text相对train的分数
- score_self是直接取data的第i行与剩下的第n-1行计算分数,取feature_sim_top_k,feature_label_top_k
- 全代码在 text_feature_lr.ipynb
|
|
|
|
|
|
|
|
|
|
|
|
|
参考