GRPO概述
GRPO(Group Relative Policy Optimization,群组相对策略优化) 是 DeepSeek 团队提出的一种新型强化学习算法, 专门用于提升大语言模型(LLM)在复杂推理任务中的表现。
它通过创新的“群组采样+相对评估”机制,
显著降低了传统强化学习算法(如 PPO)在大模型上的计算成本,并提高了训练稳定性。
|
GRPO 的关键创新在于用“组内相对比较”替代传统强化学习中对每个响应的绝对价值评估: 群组采样: 对于同一个 prompt,模型生成多个候选响应(如 4~16 个); 相对评估: 将这些响应视为一个“组”,通过组内奖励的相对高低来估计每个响应的“优势”(advantage); 无需价值网络: 省去 PPO 中必须维护的价值网络(Critic),大幅降低内存和计算开销。
|
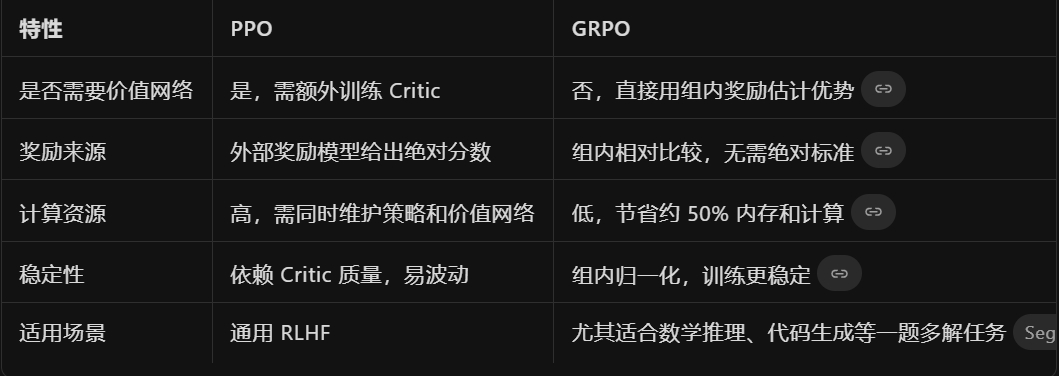
|
以 DeepSeek-R1 的训练为例,GRPO 通常与 SFT(监督微调)交替进行: 生成响应组: 对同一 prompt 采样多个候选答案; 奖励打分: 基于答案正确性、格式规范、逻辑一致性等指标打分; 计算相对优势: 使用组内均值和标准差归一化奖励,得到每个响应的优势值; 策略更新: 以 PPO 风格的目标函数更新模型参数,同时引入 KL 惩罚项防止策略突变 |
高效:无需价值网络,显著降低大模型训练成本; 稳定:组内归一化缓解奖励缩放问题,训练过程更平滑; 灵活:支持任意奖励函数(如规则、编译器、人工打分),不依赖复杂奖励模型; 实用性强:已在 DeepSeek-Math、DeepSeek-R1 等模型中验证,数学推理能力接近 GPT-4 |
数学推理 一题多解,GRPO 能自动比较多种解法优劣 代码生成 通过单元测试奖励模型判断代码正确性 对话系统 多轮对话中生成多个候选回复,择优强化 医疗、法律 结合规则或专家打分,提升专业任务准确性 GRPO 是一种“用相对比较代替绝对评分”的强化学习方法,它让大模型在复杂任务中更高效、更稳定地自我进化。 |
GRPO,即组相对策略优化(Group Relative Policy Optimization), 是DeepSeek团队提出的一种用于大型语言模型(LLMs)微调的强化学习算法。 它旨在通过在一组样本中进行价值估计来提高训练效率和模型性能。 GRPO被认为是DeepSeek-R1模型成功的关键技术之一,该模型在发布时表现出了与当时其他顶级模型相当的能力。 然而,近期的研究表明,使用GRPO训练大型语言模型时可能存在一些问题。 具体来说,Qwen团队指出,在每个token级别应用重要性采样可能会导致长序列中积累高方差,从而造成训练不稳定。 特别是在专家混合模型(Mixture-of-Experts, MoE)中, 这种不稳定性更加明显,因为token级别的路由变化会加剧这一问题。 为了解决这些问题,Qwen团队提出了一个新的算法——组序列策略优化(Group Sequence Policy Optimization, GSPO), 它试图通过将重要性采样从token级别转移到序列级别来解决上述问题,并声称这种方法可以提供更稳定的训练过程。 尽管如此,GRPO仍然是一个重要的里程碑,它展示了如何利用强化学习自动化评估过程, 减少对人工标注的依赖,并且以较低的成本实现高性能模型。这为后续研究提供了新的思路和方向。 不过,随着新方法如GSPO的提出,对于GRPO存在的局限性也有了更清晰的认识,这也推动了相关领域的持续进步和发展。 |
参考
ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
DeepSeek 背后的数学原理:深入探究群体相对策略优化 (GRPO)
一文搞懂大模型强化学习策略:DPO、PPO和GRPO
deepseek GRPO算法保姆级讲解(数学原理+源码解析+案例实战)
MedicalGPT:医疗GPT大模型全流程训练实践指引