技术背景
|
2015年 词嵌入技术的普及 技术突破: Word2Vec、GloVe等词嵌入技术被广泛应用。 这些技术通过预训练词向量,将词语映射到低维向量空间, 显著提升了下游自然语言处理任务(如文本分类、情感分析)的效果。 意义: 词嵌入技术为大模型的预训练奠定了基础,使得模型能够更好地捕捉词语的语义信息。 ResNet(残差网络) 由微软研究院提出,它通过引入残差块解决了深层网络训练中的梯度消失问题,极大地推动了深度学习的发展。 - 也就是短接,它让深度学习从几层,十几层的规模,瞬间可以达到上千层 2017年:Transformer架构的诞生
技术突破:
Google在论文《Attention Is All You Need》中提出了Transformer架构,彻底改变了序列建模的方式。
Transformer通过自注意力机制(Self-Attention)解决了循环神经网络(RNN)的长距离依赖问题,
成为大模型的核心技术基础。
意义:
Transformer架构使得模型能够并行处理序列数据,显著提高了训练效率,
并为后续大模型的发展提供了架构支持。
2018年:预训练
OpenAI发布了GPT(Generative Pre-trained Transformer)的第一个版本GPT-1。
Google推出了BERT(Bidirectional Encoder Representations from Transformers),
一种双向训练的语言表示模型,它在多项自然语言处理任务中取得了突破性的成果。
BERT模型的发布
技术突破:Google发布了BERT(Bidirectional Encoder Representations from Transformers)模型,
首次在自然语言处理领域展示了预训练模型的强大潜力。
BERT通过双向Transformer编码器,能够同时利用上下文信息,在多个NLP任务上取得了突破性进展。
意义:
BERT的发布标志着预训练模型成为自然语言处理领域的主流,为大模型的进一步发展提供了方向。
2019-2020年:GPT-3的发布与参数规模的跃升
技术突破:
GPT-2(2019年):OpenAI发布了GPT-2,展示了生成式模型的连贯性和强大的文本生成能力。
GPT-3(2020年):OpenAI发布了GPT-3,模型参数规模达到1750亿,成为当时最大的语言模型。GPT-3在零样本和小样本学习任务上表现出色,能够生成高质量的文本。
意义:
GPT-3的发布标志着大模型参数规模的指数级增长,推动了生成式人工智能的发展,并在多个领域(如内容生成、对话系统)得到了广泛应用。
模型参数彻底放飞自我,当参数达到千亿规模时,
量变产生质变,
开始出现“让人眼前一亮”,甚至让人“惊叹”,远超出任何传统开发程序所表现出的智能!
2022年11月 搭载GPT-3.5的ChatGPT发布,迅速引起了广泛关注,并成为公众讨论的焦点。 - GPT-3.5有大约1750亿个参数,这与GPT-3的参数量相同 多模态大模型与行业应用的深化 技术突破: 多模态大模型:大模型开始从单一模态(如文本)向多模态(文本、图像、音频等)发展。例如,GPT-4V支持图像理解,DALL·E 3能够根据文本生成高质量图像。 行业大模型:大模型开始在特定行业(如金融、医疗、法律)中落地应用,通过行业数据微调,提升模型在专业领域的性能。 意义: 多模态大模型的出现拓展了人工智能的应用场景,而行业大模型则推动了人工智能技术的产业化落地。 2023年至今:模型压缩与效率优化 技术突破: 模型压缩技术: 知识蒸馏、量化、剪枝等技术被广泛应用于大模型, 使得模型能够在保持性能的同时,减少计算资源和存储空间的占用。 混合专家系统(MoE)的优化: MoE架构进一步发展,通过动态路由机制,实现了模型的高效计算。 意义: 模型压缩和效率优化技术降低了大模型的部署成本,推动了其在边缘设备(如手机、物联网设备)上的应用。 2023年3⽉中旬,OpenAI发布GPT-4,增加了多模态(⽀持图⽚的输⼊形式) 这一年,大模型火遍了全球,真正展现出让了人“惊叹”的智能! 2024-2025年:AGI探索与绿色AI,智能体Agent,MCP
技术突破:
通用人工智能(AGI)的探索:
OpenAI的Q*项目等研究暗示,未来模型可能具备初步的“世界模型”构建能力,
推动人工智能向通用智能方向发展。
绿色AI:采用稀疏计算、神经拟态芯片等技术,降低大模型的能耗,推动人工智能技术的可持续发展。
意义:AGI的探索标志着人工智能技术的长期发展方向,而绿色AI则回应了全球对可持续发展的需求。
其实就是如何推广,如何降本增效,如何结合具体的业务进行落地,如何产业化,标准化,如何变现!
|
transformer框架定了大模型的基本架构,之后 调整的方向主要有三个
- 局部调整架构
- 如果寻找大量的数据,更优的数据
- 智能体Agent或程序辅助训练,学习,优化...
初步理解 强化学习 :策略执⾏动作-感知状态-得到奖励 - 背景:寻找来了大量的数据,训练后效果不理想;如何解决? - 化大为小,将一个复杂的问题拆解为一个个小问题,依次解决,这就是策略 - 确保每一小步的执行过程与得到的结果,符合“人”的期望,那么最终就可以得到期望的结果,这就是 强化学习 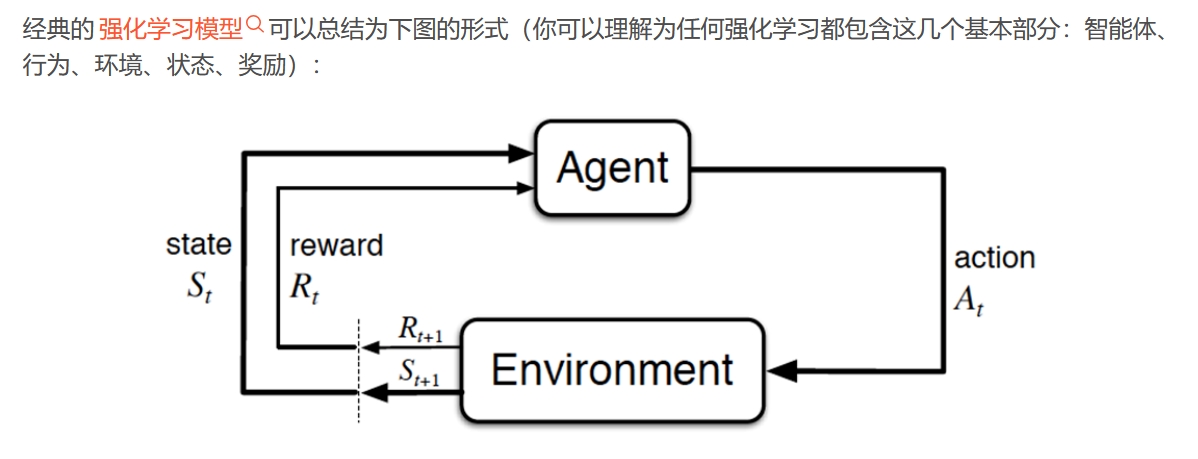
以下为个人理解 可以将边理解为动作与得分,每个动作伴随着状态的切换,同时有一个得分 动作,得分,状态切换 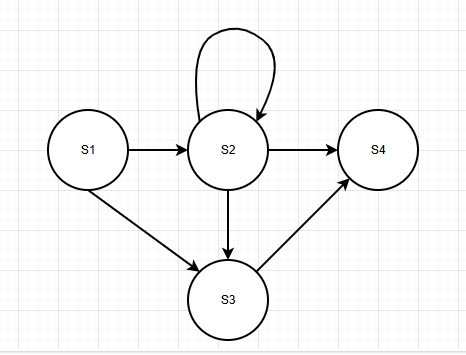
大模型解读
上述理解存在部分偏差,以下从强化学习的核心概念、原理解析以及与描述的对比三个维度展开分析:
一、强化学习的核心概念
强化学习(Reinforcement Learning, RL)
是一种通过智能体(Agent)与环境(Environment)的交互来学习最优策略的机器学习方法。
其核心要素包括:
状态(State):环境在某一时刻的描述。
动作(Action):智能体在某一状态下可执行的行为。
奖励(Reward):环境对智能体动作的即时反馈,用于衡量动作的好坏。
策略(Policy):智能体根据状态选择动作的规则。
价值函数(Value Function):评估长期累积奖励的期望。
强化学习的目标是最大化累积奖励,而非简单拆解问题或符合“人”的期望。
二、原理解析
交互过程:
智能体感知当前状态。
根据策略选择动作。
环境执行动作后,转移到新状态并反馈奖励。
智能体根据奖励更新策略,以优化未来行为。
关键机制:
试错学习:通过不断尝试动作,观察奖励反馈,逐步优化策略。
探索与利用:平衡探索新动作(发现更高奖励)与利用已知最优动作(最大化当前奖励)。
价值评估:通过价值函数评估状态或动作的长期价值,指导策略更新。
三、与描述的对比 “化大为小,将一个复杂的问题拆解为一个个小问题,依次解决,这就是策略”: 偏差:策略并非简单拆解问题,而是定义智能体在状态下的动作选择规则。 强化学习通过试错和价值评估优化策略,而非直接拆解问题。 “确保每一小步的执行过程与得到的结果,符合‘人’的期望,那么最终就可以得到期望的结果,这就是强化学习”: 偏差:强化学习的目标是最大化累积奖励,而非直接符合“人”的期望。 奖励函数由设计者定义,可能反映人类期望,但本质是优化长期累积奖励。 “寻找来了大量的数据,训练后效果不理想;如何解决?”: 偏差:强化学习不依赖大量标注数据,而是通过试错和交互学习。 数据不理想时,可能通过调整奖励函数、探索策略或算法改进来解决,而非直接拆解问题。 四、总结 强化学习通过智能体与环境的交互,优化策略以最大化累积奖励。 描述中的“化大为小”和“符合人期望”偏离了强化学习的核心机制, 可能混淆了问题拆解与策略优化、人类期望与奖励函数的关系。 强化学习的核心是试错学习、探索与利用、价值评估,而非简单的问题拆解或直接符合人类期望。 |
强化学习极简入门:通俗理解MDP、DP MC TD和Q学习、策略梯度、PPO |
|
|
|
|
ChatGPT三阶段
|
|
|
|
|
|
|
|
参考
大模型与ChatGPT系列:原理、论文、代码、应用