ROC曲线
|
ROC曲线(Receiver Operating Characteristic Curve)的绘制过程主要涉及几个关键步骤:
准备数据、训练模型、获取预测概率、
计算真正率(TPR)和假正率(FPR),并最终绘制曲线。
以下将以LightGBM模型和breast_cancer数据集为例,详细说明ROC曲线的绘制过程。
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
# 加载数据集
data = load_breast_cancer()
X = data.data
y = data.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
import lightgbm as lgb
# 转换为LightGBM的数据格式
dtrain = lgb.Dataset(X_train, label=y_train)
dtest = lgb.Dataset(X_test, label=y_test, reference=dtrain)
# 设置参数
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': {'binary_logloss', 'auc'},
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'verbose': 0,
'max_depth':2
}
# 训练模型
gbm = lgb.train(params, dtrain, num_boost_round=20, valid_sets=[dtest])
注意:
LightGBM的predict方法默认返回的是预测类别,
如果需要概率,可以设置raw_score=True
(对于二分类问题,这通常返回的是对数几率,需要进一步处理才能得到概率),
但更常见的是使用predict_proba方法直接获取概率。
然而,LightGBM的predict_proba方法在某些版本的API中可能不可用,
这里假设使用的是返回对数几率的版本,
并需要自行转换为概率(这里简化处理,直接使用predict的结果作为示例)。
# 预测概率
y_score = gbm.predict(X_test, num_iteration=gbm.best_iteration)
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_test, y_score)
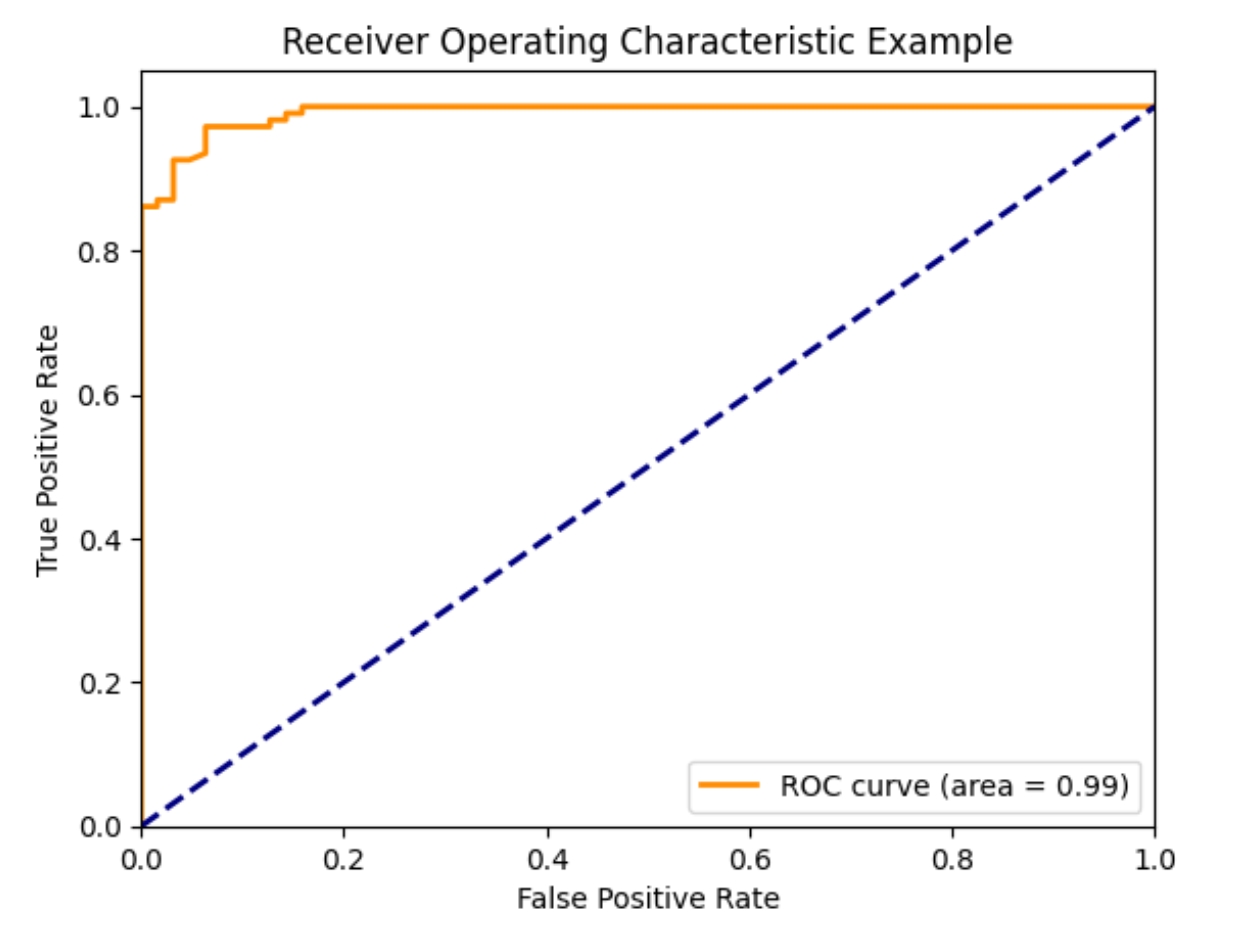
使用matplotlib库绘制ROC曲线,并计算曲线下面积(AUC)。
import matplotlib.pyplot as plt
from sklearn.metrics import auc
# 计算AUC
roc_auc = auc(fpr, tpr)
# 绘制ROC曲线
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic Example')
plt.legend(loc="lower right")
plt.show()
curve 英/kɜːv/ 美/kɜːrv/
n.曲线,弧线;学生成绩分布曲线;弯曲;曲面;(女性优美体型的)曲线轮廓;(投向击球员的)曲线球; (道路的)弯曲处;骗人的把戏, 欺骗;
(图表上表示随参数变化的数据的)曲线,曲线图
v.使弯曲,使成曲线;向 (击球员)投曲线球;(使)沿曲线运动;呈曲线形;把(考试成绩等)标示在曲线图上
|
|
在机器学习中,AUC(Area Under the Curve)是一个重要的评估指标,
用于衡量二分类模型的好坏。
它表示的是ROC曲线(Receiver Operating Characteristic Curve)下的面积。
ROC曲线是以假正率(False Positive Rate, FPR)为横坐标,
真正率(True Positive Rate, TPR)为纵坐标所绘制的曲线。
真正率(TPR)也称为灵敏度(Sensitivity),
表示的是所有实际为正类的样本中,被模型预测为正类的比例。
假正率(FPR)也称为误报率,表示的是所有实际为负类的样本中,
被模型预测为正类的比例。
AUC的值域为[0, 1],AUC越大,说明模型越好。
一个完美的模型的AUC为1,而一个完全随机的模型的AUC为0.5。
在实际应用中,我们通常希望模型的AUC能够尽可能接近1。
在LightGBM等机器学习框架中,AUC常作为评估模型性能的一个重要指标,
帮助我们判断模型在不同阈值下的整体表现。
|
|
|
|
|
|
|
真阳率·假阳率
|
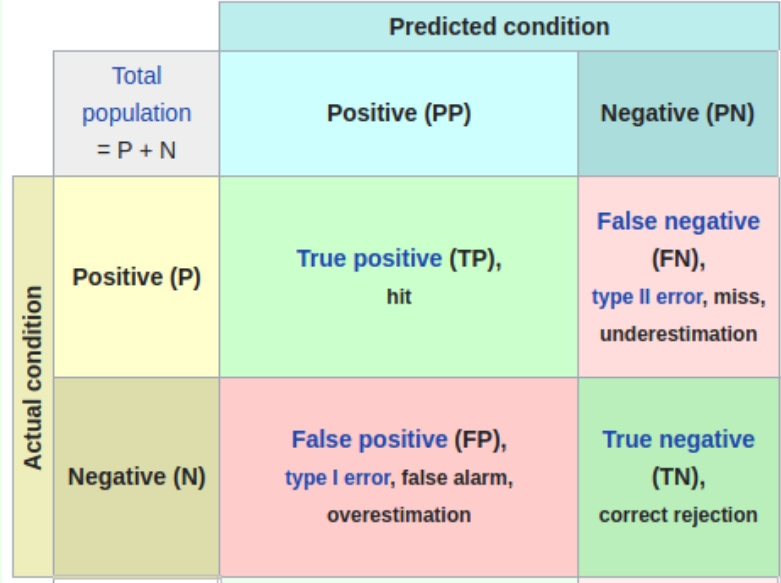
真阳性率(True Positive Rate, TPR)
定义:
真阳性率也称为灵敏度(Sensitivity)或召回率(Recall),
是指在所有实际为正例的样本中,被正确地判断为正例的比例。
或者说是模型预测为正中实际为正的样本占全体正样本的比例
计算公式
TPR = TP / (TP + FN),
其中TP表示真阳性(True Positive),
即实际为正例且被正确判断为正例的样本数量;
FN表示假阴性(False Negative),即实际为正例但被错误判断为负例的样本数量。
应用
真阳性率是评估分类模型性能的重要指标之一,
特别适用于对正例判断的要求较高的场景。
在医学检测中,真阳性率反映了检测方法对真实患病者的识别能力。
|
|
负样本中被误判为正样本的比例
正常数据被 误判为异常数据的比例
假阳性率(False Positive Rate, FPR)
定义:
假阳性率是指在检测或诊断过程中,将实际上没有患病的个体误判为患病的比例。
计算公式:
FPR = FP / (FP + TN),
其中FP表示假阳性(False Positive),
即实际为负例但被错误判断为正例的样本数量;
TN表示真阴性(True Negative),即实际为负例且被正确判断为负例的样本数量。
应用:
假阳性率过高会带来一系列问题,
如给被检测者带来不必要的心理负担、增加医疗成本和潜在风险,以及导致医疗资源的浪费。
在机器学习领域,假阳性率也是评估分类模型性能的重要指标之一,
通常与真阳性率一起用于绘制ROC曲线,以评估模型的分类效率。
|
|
|
|
|
|
|
KS
|
训练
```
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
# from sklearn.metrics import roc_curve
# import matplotlib.pyplot as plt
# 1. 加载乳腺癌数据集
data = load_breast_cancer()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = data.target # 注意:在原始数据集中,0表示恶性(Malignant),1表示良性(Benign)
# 为了方便理解,我们将标签反转,使 1 代表恶性(正样本),0代表良性(负样本)。
# 这是因为在医疗诊断中,我们通常更关心“患病”(正例)的检测。
y = np.where(y == 0, 1, 0)
# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 3. 训练LightGBM模型
model = LGBMClassifier(random_state=42)
model.fit(X_train, y_train)
# 4. 获取测试集的预测概率
# 我们关注的是预测为“恶性”(类别1)的概率
y_pred_proba = model.predict_proba(X_test)[:, 1]
```
通过ROC计算
```
from tpf.mlib import ModelEval as me
me.ks_roc(y_pred_proba, y_test)
```
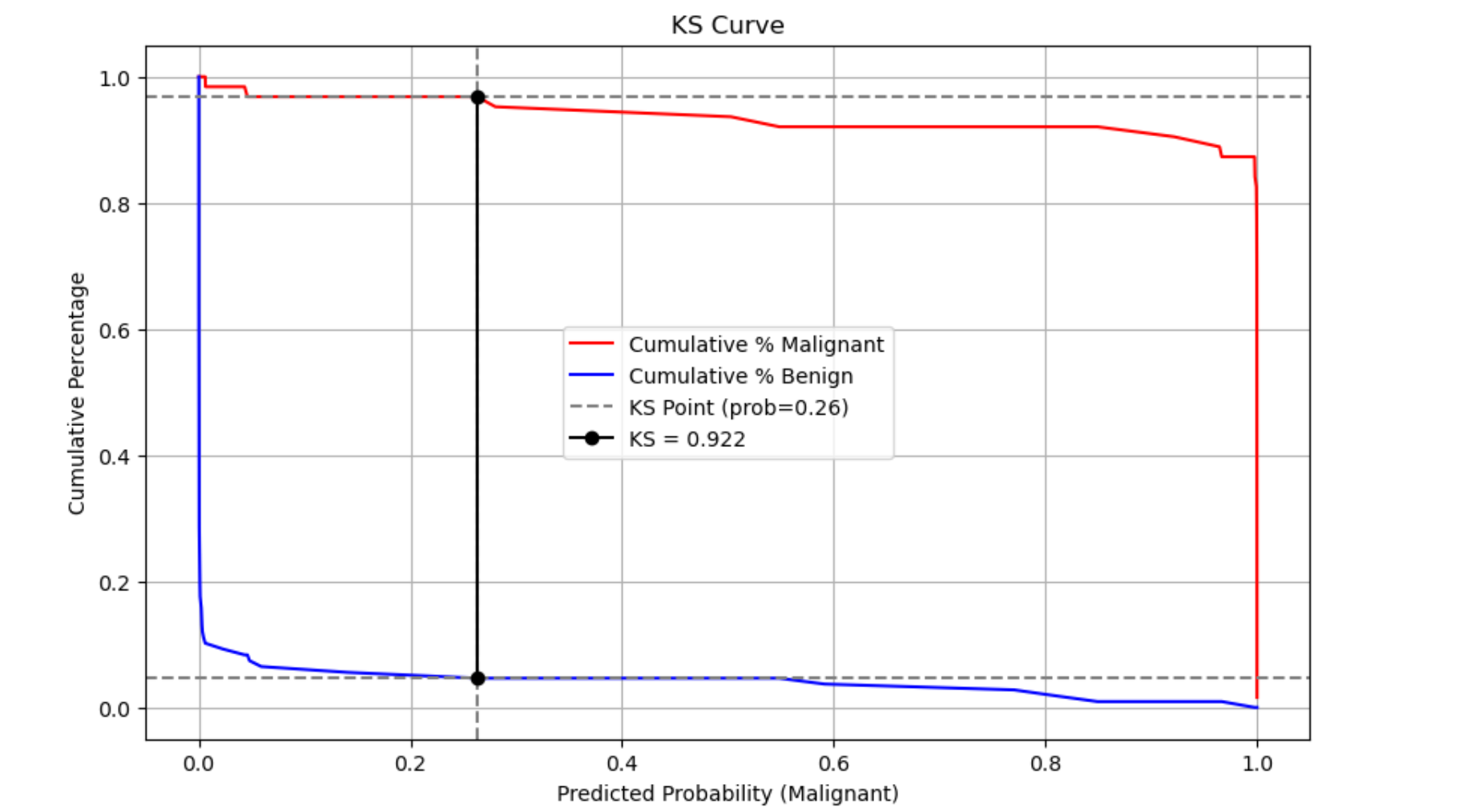
通过SKlearn ROC曲线计算的KS值为: 0.9220
对应的阈值为: 0.2631
(0.922, 0.2631)
自定义计算
```
me.ks(y_pred_proba=y_pred_proba,y_label=y_test)
```
KS值为: 0.922
在概率为 0.2631 的划分点处取得。
(np.float64(0.922), np.float64(0.2631))
出图
```
me.ks(y_pred_proba=y_pred_proba,y_label=y_test,is_show=True)
```
|
|
|
|
|
|
|
|
|