AdamW
- 什么是 AdamW?
- AdamW 是对原始 Adam 优化器的一个修正版本,主要改进了 权重衰减(weight decay) 的处理方式。
- 背景问题:
- 在原始的 Adam 优化器中,权重衰减 是与梯度更新一起耦合的,
- 这种方式可能会影响优化器的动量行为,导致性能下降,
- 尤其是在训练 Transformer 模型时。
- AdamW 的改进:
- AdamW 将权重衰减从梯度更新中解耦,使其更像传统的 L2 正则化,
- 但作用于参数更新步骤之外,从而更有效地控制模型复杂度,提升泛化能力。

|
|
AdamW 与 Adam 最关键的区别在于权重衰减的实现方式。
Adam 中的传统做法(L2正则化):
直接将权重衰减项加到损失函数中,或者等价地,在计算梯度时加上权重衰减项。
这在自适应学习率算法中可能会出现问题,
因为衰减量会随着参数的历史梯度而变化,导致正则化效果不纯粹。
AdamW 的解法(解耦权重衰减):
将权重衰减与梯度计算完全分开。
在更新参数时,AdamW 会先像普通 Adam 一样根据梯度移动参数,
然后再独立地、直接地让参数乘以一个略小于1的数(即 1 - lr * weight_decay),从而实现真正的权重衰减。
这种方法被认为更有效,
因为它确保了权重衰减的正则化效果不受自适应学习率的干扰,
能更好地防止模型过拟合。
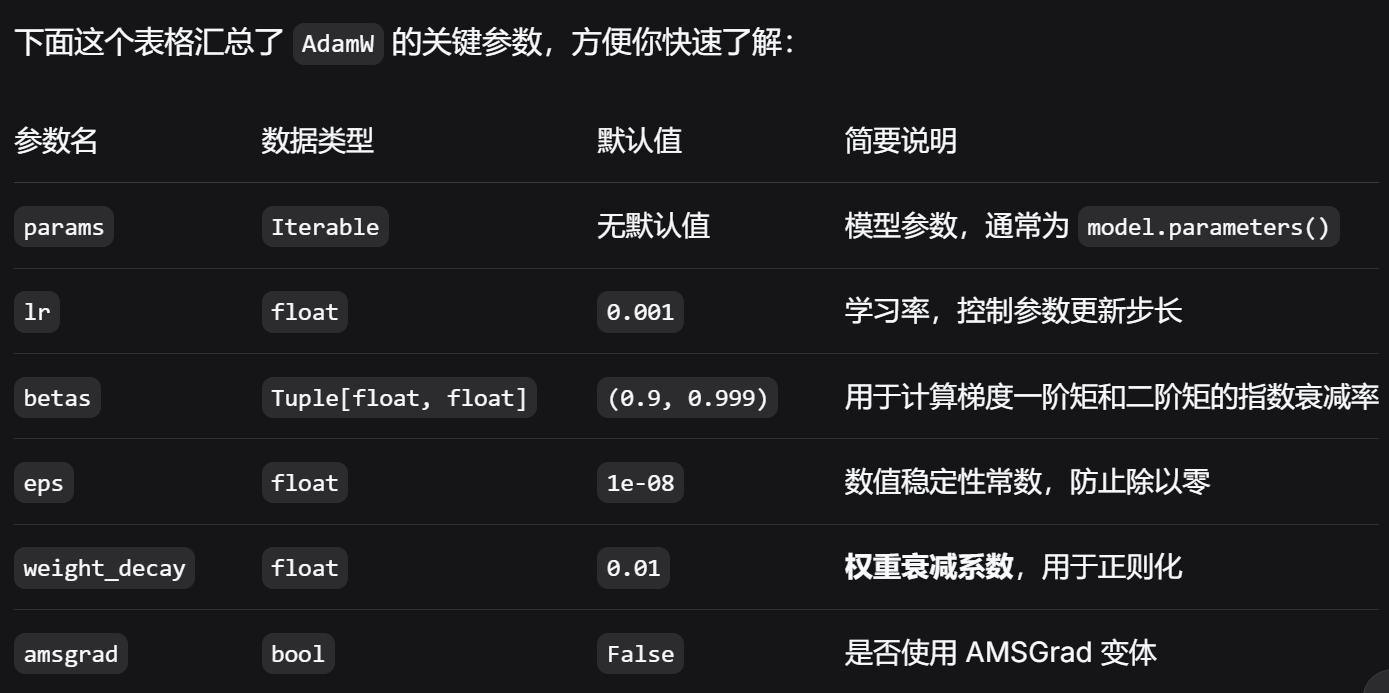
如何选择 AdamW 的参数
学习率 lr:这是最重要的参数之一。
AdamW 通常比 Adam 更能适应较大的学习率。
你可以从默认值 0.001 开始尝试,根据训练情况调整。
权重衰减 weight_decay:这是 AdamW 的另一个关键参数。
由于 AdamW 能更有效地进行权重衰减,你可能需要尝试与使用 Adam 时不同的衰减强度。
一般可以从 0.01、0.1 等值开始实验。
betas:通常使用默认值 (0.9, 0.999) 就能取得不错的效果。
amsgrad:
如果你的训练过程中梯度波动很大,或者遇到收敛不稳定的情况,
可以尝试将 amsgrad 设为 True。
但在许多情况下,保持 False 已经足够。
进阶提示 配合学习率调度器: 为了获得更好的训练效果, 通常建议将 AdamW 与学习率调度器(如 StepLR、CosineAnnealingLR 等)结合使用, 在训练过程中动态调整学习率。 与 SGD 对比:在某些场景下,例如数据分布比较规整或者需要非常精细的调优时, 带动量的 SGD 配合合适的学习率调度,其最终性能有时可能会超过 AdamW。 但在实践中,AdamW 因其强大的自适应能力和较少的超参数调优需求,通常作为首选的优化器。 AdamW 的核心思想:解耦权重衰减
AdamW 将 权重衰减 从梯度更新中分离出来,不再将其视为损失函数的一部分,而是在参数更新步骤中显式地、独立地执行:
```
param = param - lr * (m_t / sqrt(v_t) + weight_decay * param)
```
而不是像 Adam 那样:
```
# Adam(错误地将 weight decay 加入梯度)
grad = grad + weight_decay * param
# 然后用这个 grad 更新 m, v...
```
- 这样做的好处是:
- 权重衰减的强度不再受自适应学习率影响;
- 更符合 L2 正则化的原始意图;
- 在实践中(尤其在训练 Transformer、BERT 等大模型时)表现更稳定、效果更好。
|
```
import torch
import torch.nn as nn
from torch.optim import AdamW
# 1. 定义一个简单的模型
model = nn.Linear(10, 1) # 这里以一个线性模型为例
# 2. 定义损失函数
criterion = nn.MSELoss()
# 3. 初始化 AdamW 优化器,并传入模型参数
optimizer = AdamW(model.parameters(), lr=0.001, weight_decay=0.01)
# 训练循环示例
for epoch in range(100):
# 4. 前向传播
outputs = model(torch.randn(10, 10))
loss = criterion(outputs, torch.randn(10, 1))
# 5. 反向传播前,清零梯度
optimizer.zero_grad()
# 6. 反向传播,计算梯度
loss.backward()
# 7. 优化器更新模型参数
optimizer.step()
```
```
from torch.optim import AdamW
optimizer = AdamW(
model.parameters(),
lr=1e-3,
betas=(0.9, 0.999),
eps=1e-8,
weight_decay=0.01, # 这里设置的是真正的权重衰减值
amsgrad=False
)
```
- lr: 学习率(默认 1e-3) - betas: 用于计算梯度和平方梯度的滑动平均系数(默认 (0.9, 0.999)) - eps: 数值稳定性的小常数(默认 1e-8) - weight_decay: 解耦后的权重衰减系数(默认 0) - amsgrad: 是否使用 AMSGrad 变体(默认 False) 实际建议 - 在训练现代深度学习模型(尤其是 NLP 中的 Transformer 架构)时,优先使用 AdamW 而非 Adam。 - 典型的 weight_decay 值在 0.01 到 0.1 之间(例如 BERT 使用 0.01)。 - 学习率通常配合 warmup 和线性衰减策略使用。 |
|
|
|
|
参考