特征选择概述
根据思想的不同,或是为取得更好的效果,或是为了节省资源... 集成的思想
随机地选择部分特征,形成一系列弱分类器比如,总共有10个特征,
- 逐次舍弃一个,取其中9个,各计算一次
- 逐次舍弃二个,取其中8个,各计算一次
- ...
- 综合所有计算结果
这充分利用了计算机的计算速度进行暴力破解...
又有集思广义的意思在其中
逐次舍弃这种算法更偏向于传统算法,有着精准,确定的路线 AI中更多的是使用 随机,随机一次是挺随机的,没什么意义... 但AI中的随机是指 大量的随机,随机到一定程度后,会呈现出统计学意义! 说随机并不准确,是大量的随机,具备统计学意义! 比如从100个特征中每次随机提取90个特征,一两次的话,随机性很强, 如果是随机了100次,那么这结果是注定的!注定的!注定的! 很可能三五十就拿到这个注定的结果了 所以集成类算法的迭代次数都是几十次以上,有的上百次迭代 设置这个参数的时候,要回忆一下这个思想,考虑一个特征的个数,预估一个迭代次数看看效果...
|
现实中,百分之七八十的事物是不断在重复,即有很多相似的事物,
同时,AI是为了学习规律,一类事物学其中一个/几个就可以了,
不需要把每个事物都学一下,
确切地说,是已经掌握的事物,不需要再反复去学了
比如,要区分什么是树,什么是草,简单地拿几棵树,几棵草举例一下,就可以,
完全没必要看成百上千棵草与树,没这个必要...
这就需要 有区分相似事物的方法
这实际上涉及到如何去学习...一系列的事物... 这里就是简单粗暴地将事物进行了分类, 重在学习 类 别 之 间 的 差 异 不是要对一个类别研究有多深入,只要学习到这样一种程度就可以了 - 能够区分一个类别与其他类别的差异 - 比如,二分类问题-区分树与草,树比草高,树比草粗,就这两点就可以分区二者了, - 这要比研究明白一棵草的组成简单多了 这实际上是取巧了,因为世界的进步主要取决于对事物研究的深度 ... 对事物本质的把握... - 如果总是在表象上比来比去,会将整个文明困于表象之中,导致文明发展缓慢... - 仅个人看法,如有雷同,纯属巧合... 这好像也不是渺小的我该考虑的问题... 这样的方针,主要是为了尽快达到一个目的 -- 掌握事物的全貌 - 假设一个事物大概由A,B,C三类事物组成 - 第一步主要想办法把A,B,C三为事物都学习一下,而不是先把A研究明白了再去研究B,C... 比如这说人生百年,能自主做事的时间大概也就30年,拿出10-20年研究AI算法 第一步, - 分类: AI算法分机器学习,深度学习,NLP,CV,大模型,多模态 - 拿出半年时间,这六类各花1个月时间,熟悉一下基本代码,就了解了整个AI的全貌 第二步 - 实战,深入研究一个类别 - 从这六类中找出最想做的那个类别,用半年时间深入研究,做练习,做项目 - 注意,这半年只研究其中一个类别,工作要求的是一专多能,必须要先深入研究一个 - 比如你的职位是机器学习,工作中几乎不用深度学习,更不会给你一个深度学习的项目去做... 第三步 - 面试,工作,融入行业 ,重在融入行业 - 这一步快则一个月,慢则半年,就能在自己感兴趣的方向上找到一份工作 - 有些人不是为了找工作,可能是为了兴趣/爱好/下一代/做兼职/随机尝试新事物... - 总之,重点是要融入这个行业... 之后就是实践与理论的相互促进了... - 否则,学而不用,或者由于事先对入行难度评估有误而导致半途而废的话,就是在浪费时间! 有了这个全面的方针之后,想必学习的过程更能保持内心的稳定...
重在全,避免不停地做重复的事情....
|
A,B两个事物非常相似,95%的内容是一样的 这意味着A可以代表B,那么二者取其一就可以了, 这是AI中的常用做法 但个人总是担心,万一A中剩下那5%是有用的呢? 个人这里觉得取A与B的平均值更好一些,就是(A+B)/2去替代A与B二取一的做法 这里没见过有人这么做,仅个人观点 这么做的意思是,你们不是相似么, 取你们的平均值,取一类事物的中心值,不是更能代表这类事物吗? 相似者取其中 |
特征与特征两两之间相似,取其一 特征与标签之间相似,保留,与标签不相关的特征,舍弃 |
|
|
变量聚类
在机器学习中,变量聚类(也称为R型聚类分析)是一种特定的聚类分析方法,它主要用于对样本的特征或变量进行分类,而不是直接对样本本身进行分类。这种方法在系统分析或数据预处理阶段特别有用,尤其是在处理包含大量相似或相关特征的数据集时。
变量聚类的定义
变量聚类是通过分析变量之间的相似性(如相关性)来将变量分组的过程。其目的是将高度相关或相似的变量归为一类,以便在后续的分析或建模过程中能够更有效地处理这些变量。
变量聚类的应用
数据预处理:在构建机器学习模型之前,通过变量聚类可以帮助识别并合并那些高度相关的变量,从而减少模型的复杂性,提高模型的泛化能力。
特征选择:在特征工程中,变量聚类可以用于识别那些对目标变量影响最大或最具代表性的特征子集,从而提高模型的性能。
数据可视化:通过将变量聚类与降维技术(如PCA)结合使用,可以更容易地可视化高维数据集的结构和关系。
变量聚类的步骤
变量聚类的过程通常包括以下几个步骤:
数据准备:收集和整理待聚类的变量数据,确保数据的质量和完整性。
相似性度量:选择适当的相似性度量方法(如相关系数、协方差等)来计算变量之间的相似度。
聚类算法选择:根据数据的特点和聚类的目的选择合适的聚类算法(如K-means、层次聚类等)。
聚类执行:应用选定的聚类算法对变量进行聚类。
结果解释:分析聚类结果,解释不同聚类中变量的共性和差异,并根据需要进行后续处理。
注意事项
变量聚类的结果可能受到相似性度量方法和聚类算法选择的影响,因此在实际应用中需要根据具体情况进行选择和调整。
变量聚类并不是万能的,它并不能解决所有与变量相关的问题。在某些情况下,可能需要结合其他统计方法或机器学习技术来共同解决问题。
综上所述,变量聚类是机器学习中一种重要的数据预处理和特征选择技术,它通过对变量进行分类来简化数据集、提高模型性能,并为后续的分析和建模工作提供有力支持。
|
|
|
|
|
|
|
|
皮尔逊相关系数
皮尔逊相关系数(Pearson correlation coefficient) 主要用于衡量两个连续型变量之间的线性相关程度。 它计算的是两个变量与其各自平均值的离差(即变量值与平均值的差)的乘积的平均值, 这些乘积的平均值除以两个标准差之积即为皮尔逊相关系数。 因此,皮尔逊相关系数主要适用于连续型变量的相关性分析。
对于离散型变量,尤其是名义变量(nominal variables),皮尔逊相关系数并不适用,
因为这些变量的值通常不代表大小或数量,而是代表类别或分类。
对于这类变量,通常会使用其他的相关性度量,
如点双列相关系数(Point-Biserial Correlation)、
Phi系数(Phi Coefficient,用于2x2列联表)或
Cramer's V(用于更大尺寸的列联表)等。
然而,当离散型变量实际上是等距或等比的(例如,分数、等级等),
并且可以被视为连续变量的近似时,
有时也可以计算皮尔逊相关系数来评估它们之间的线性关系。
但这种情况下需要谨慎解释结果,因为离散化可能会引入一些不连续性,影响相关性的真实反映。
总的来说,皮尔逊相关系数是专为连续型变量设计的,
但在某些条件下也可以用于近似连续的离散型变量。
对于真正的离散型或分类变量,应考虑使用其他更适合的相关性度量。
|
|
|
|
|
|
|
|
卡方验证
|
机器学习中,皮尔逊相关系数是从线性的角度评估两个的变量之间的相关性,那卡方验证是从线性的角度评估的吗?还是从其他什么角度评估的? 在机器学习中,皮尔逊相关系数(Pearson correlation coefficient) 确实是从线性的角度评估两个变量之间的相关性。 它衡量的是两个变量之间线性关系的强度和方向, 取值范围从-1到1,其中1表示完全正相关,-1表示完全负相关,0表示无线性相关。
相比之下,卡方验证(卡方检验,Chi-Square Test)
并不是从线性的角度评估两个变量之间的相关性。
卡方检验主要用于评估观察频数与期望频数之间的差异是否显著,
从而推断两个分类变量之间是否独立或存在某种关联。
它属于非参数检验的范畴,适用于分类数据,
特别是当数据不满足正态分布或方差齐性等参数检验的前提条件时。
卡方检验的基本原理是
比较 观察频数 与 基于某种假设(如两个变量独立)计算出的期望频数 之间的差异。
如果这种差异足够大,以至于在统计学上被认为是显著的,
那么就可以拒绝原假设,认为两个变量之间存在某种关联。
这种关联并不一定是线性的,而可能是任何形式的关联,
只要它导致了观察频数与期望频数之间的显著差异。
因此,可以说卡方验证是从更一般的相关性角度,而不是线性的角度,
来评估两个分类变量之间的关系的。
在机器学习中,卡方检验常用于特征选择,
通过计算特征变量与响应变量之间的卡方统计量来评估它们之间的相关性,
从而选择出对预测目标最有用的特征。
|
import pandas as pd
from scipy.stats import chi2_contingency
# 示例数据
data = {
'用户ID': [1, 2, 3, 4, 5],
'年龄分组': ['青年', '青年', '中年', '老年', '中年'],
'性别': ['男', '女', '男', '女', '女'],
'收入等级': ['中等', '低', '高', '低', '中等'],
'地区': ['A区', 'B区', 'A区', 'C区', 'B区'],
'是否购买': ['是', '否', '是', '否', '是']
}
df = pd.DataFrame(data)
from tpf import DataDeal as dt
label = df['是否购买']
X = df.drop(columns=["是否购买"])
col_name,col_value=dt.feature_select_chi2(X=X,y=label,threshold=4)
for k,v in zip(col_name,col_value):
print(k,v)
用户ID 5.000000000000001
收入等级 5.0
相比年龄,性别,收入等级与是否购物的相关性更大
|
|
|
|
|
|
|
多重共线性
连续型变量肯定可以
离散型变量需要先转换为数字,再判断它们之间是否具有共线性
- 比如,多表关联时,会出现多个类型字段描述相近事物,
- 实则只是描述类型不一样,本质还是一一对应的关系
- 这时,它们是100%共线的
作为数据挖掘工程师,对于共线性分析有着深入的了解,以下是对该问题的详细解答: 共线性分析并非只针对连续型变量,它对类别型变量(分类变量)也同样适用。不过,需要注意的是,共线性的本质是自变量之间不能有高度的相互影响,即一个自变量的值不能强烈地受另一个自变量的影响。这种影响通常通过方差膨胀因子(VIF)或者相关系数来衡量。 对于连续型变量,可以直接计算它们之间的相关系数和VIF值来评估共线性问题。然而,对于类别型变量,由于它们无法直接作为因变量(在一般线性模型中)以及VIF值的计算原理限制,因此不能直接计算其VIF值来评估共线性。但这并不意味着类别型变量之间不存在共线性问题。如果类别型变量之间彼此强烈影响,或者类别型变量和数值变量彼此强烈影响,这同样会被视为共线性问题,并可能影响回归结果。
为了解决这一问题,在R等统计软件中,可以通过特定的包(如collinear包)将类别型变量转化为数值变量,然后计算其VIF值来评估共线性。这种转化方法允许数据挖掘工程师和统计学家在处理包含类别型变量的数据集时,也能有效地识别和解决共线性问题。
综上所述,共线性分析不仅适用于连续型变量,也适用于类别型变量。在处理包含不同类型变量的数据集时,需要综合考虑各种因素,以确保分析结果的准确性和可靠性。
|
|
|
|
|
|
|
|
特征选择示例
import numpy as np
import pandas as pd
from tpf.link.featureselect import feature_selection
from sklearn.datasets import make_classification
# 生成示例数据
X, y = make_classification(
n_samples=1000,
n_features=500,
n_informative=10,
n_redundant=5,
random_state=42
)
# 转换为DataFrame(可选)
X_df = pd.DataFrame(X, columns=[f'feature_{i}' for i in range(X.shape[1])])
# 使用特征选择
result_df = feature_selection(
X_df,
y,
feature_eval_nums=5,
num_boost_round=20,
max_feature_selected_num=100,
corr_line=0.9,
debug=True
)
print("特征选择结果(包含重要性分数和出现频次):")
print(result_df.head(10))
print(f"\n总共选择了 {len(result_df)} 个特征")
print(f"最高重要性分数: {result_df['importance'].max():.4f}")
print(f"最高出现频次: {result_df['occurrence_count'].max()}")
特征选择结果(包含重要性分数和出现频次):
feature importance occurrence_count
0 feature_8 49 5
1 feature_445 47 5
2 feature_399 38 5
3 feature_33 27 5
4 feature_455 20 5
5 feature_293 17 5
6 feature_43 15 5
7 feature_68 15 5
8 feature_158 12 5
9 feature_45 11 5
总共选择了 200 个特征
最高重要性分数: 49.0000
最高出现频次: 5
|
|
|
|
|
|
|
|
特征选择·封装
```
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
# 加载乳腺癌数据集
data = load_breast_cancer()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = pd.DataFrame(data.target,columns=['target'])
```
```
from tpf.data.feature.selected import feature_selection_lgbm
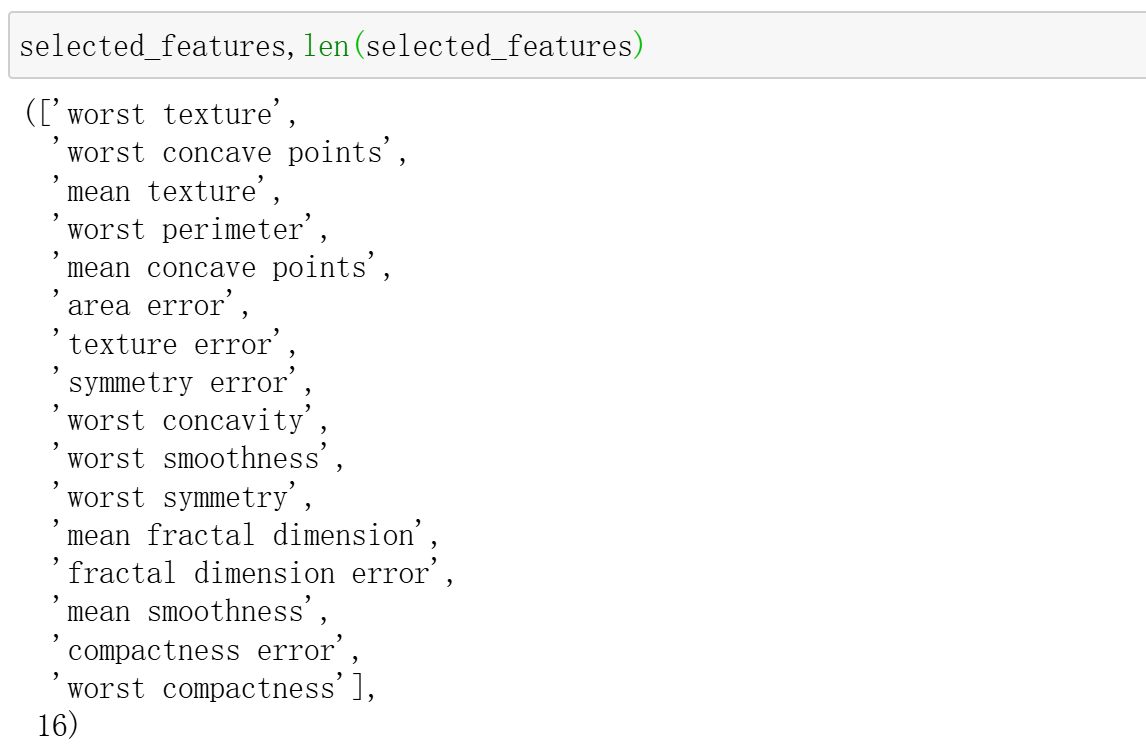
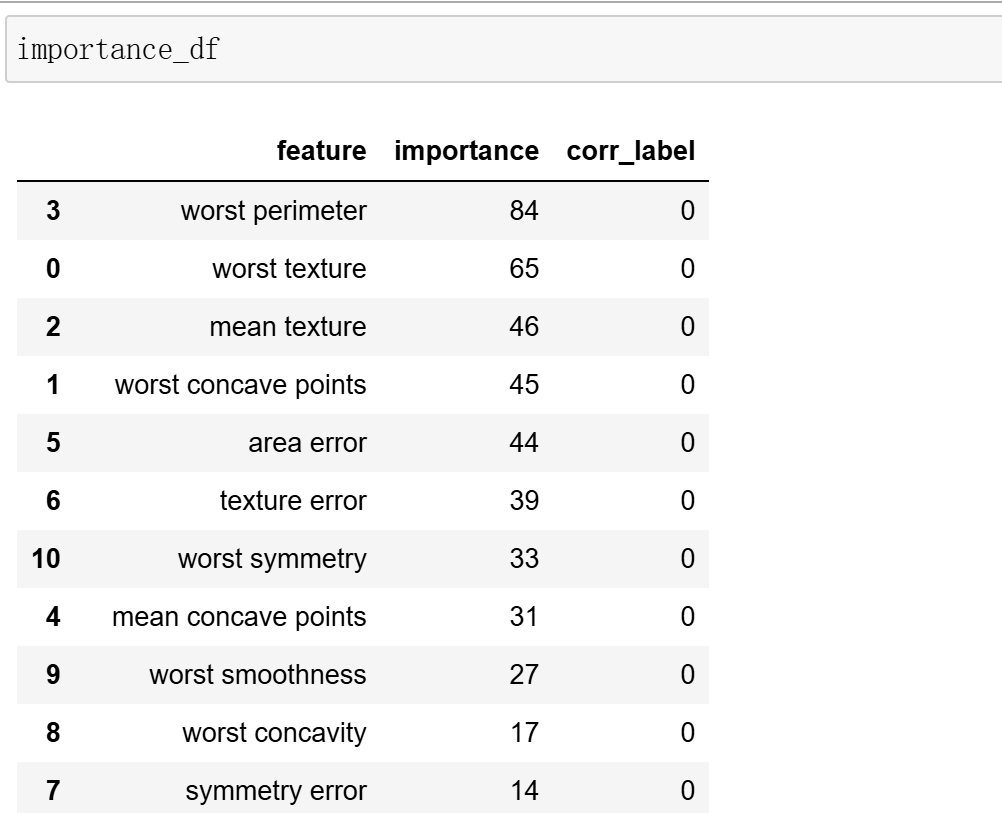
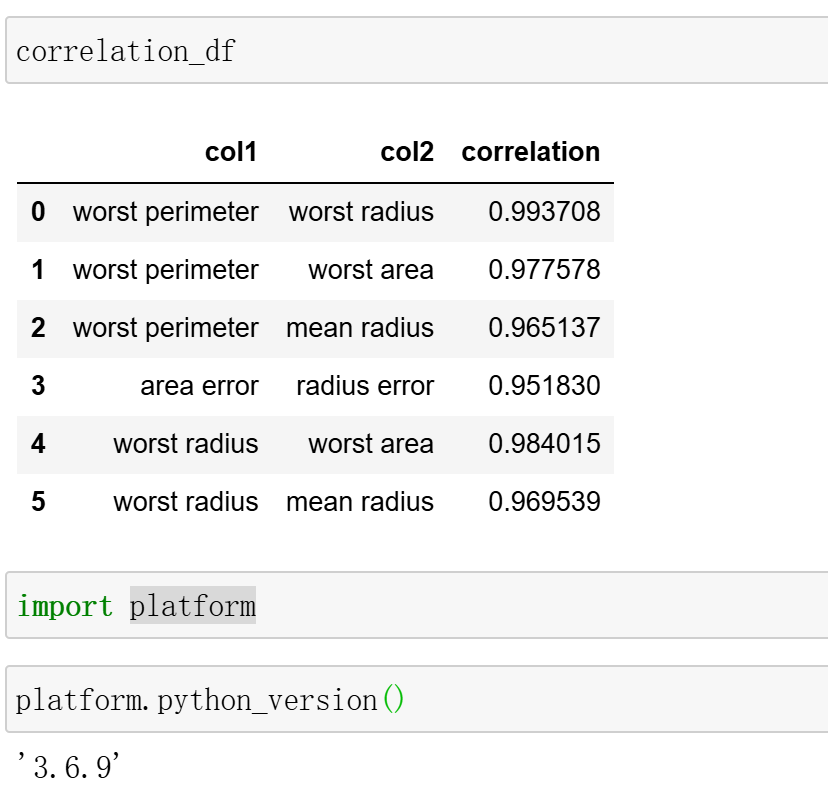
selected_features, importance_df, correlation_df = feature_selection_lgbm(X,y,
feature_eval_nums=10,
num_boost_round=30,
max_feature_selected_num=10,
corr_line=0.95,)
```
```
============================================================
Step 1: Feature Selection using FeatureSelected
============================================================
==================================================
Feature Selection Summary
==================================================
Original feature count: Unknown
Final selected feature count: 16
Top 10 important features:
feature importance corr_label
worst perimeter 84 0
worst texture 65 0
mean texture 46 0
worst concave points 45 0
area error 44 0
texture error 39 0
worst symmetry 33 0
mean concave points 31 0
worst smoothness 27 0
worst concavity 17 0
High correlation feature pairs (threshold > 0.95):
col1 col2 correlation
worst perimeter worst radius 0.993708
worst perimeter worst area 0.977578
worst perimeter mean radius 0.965137
area error radius error 0.951830
worst radius worst area 0.984015
worst radius mean radius 0.969539
Selected feature list:
1. worst texture
2. worst concave points
3. mean texture
4. worst perimeter
5. mean concave points
6. area error
7. texture error
8. symmetry error
9. worst concavity
10. worst smoothness
11. worst symmetry
12. mean fractal dimension
13. fractal dimension error
14. mean smoothness
15. compactness error
16. worst compactness
Selected feature importance details:
feature importance corr_label
worst perimeter 84 0
worst texture 65 0
mean texture 46 0
worst concave points 45 0
area error 44 0
texture error 39 0
worst symmetry 33 0
mean concave points 31 0
worst smoothness 27 0
worst concavity 17 0
symmetry error 14 0
worst compactness 12 0
fractal dimension error 10 0
compactness error 10 0
mean smoothness 9 0
mean fractal dimension 6 0
```
|
|
|
|
|
|
|
|
参考
sklearn数据集分割方法汇总