特征工程做什么
如果将AI工程分为两块, 数据处理 模型相关 那么,特征工程就是处理数据的,将业务数据转化为模型需要的数据
数据观察
图片类数据看看图片什么样,以便后继标注;这里说的特征工程主要指二维数表,图像处理请移驾CV专栏 二维数据表,则观察不同列的数据分布: 空值处理 编码:字符串转数字 将数据全部转为数字后,后面就观察其分布: 均值,方差,min,max,25%,50%,75%,90%,99%附近的数据 离群点,异常处理数据 如果列比较多,则会分析一下列之间的线性关系,是否有严重重复的,也就是特征选择: 卡方 IV值 共线性 看完数据什么样后,对数据的规模,行数,列数,列的含义等数据特点有所了解之后, 确认业务是分类问题还是回归问题, 标签是什么 以便考虑选择什么样的模型
|
import datetime
import os
from typing import Callable, Optional
import pandas as pd
from sklearn import preprocessing
import numpy as np
import torch
from torch_geometric.data import (
Data,
InMemoryDataset
)
pd.set_option('display.max_columns', None)
data_path = "/wks/datasets/ibm_aml/HI-Small_Trans.csv"
data=pd.read_csv(data_path)
df = data
df[:3]
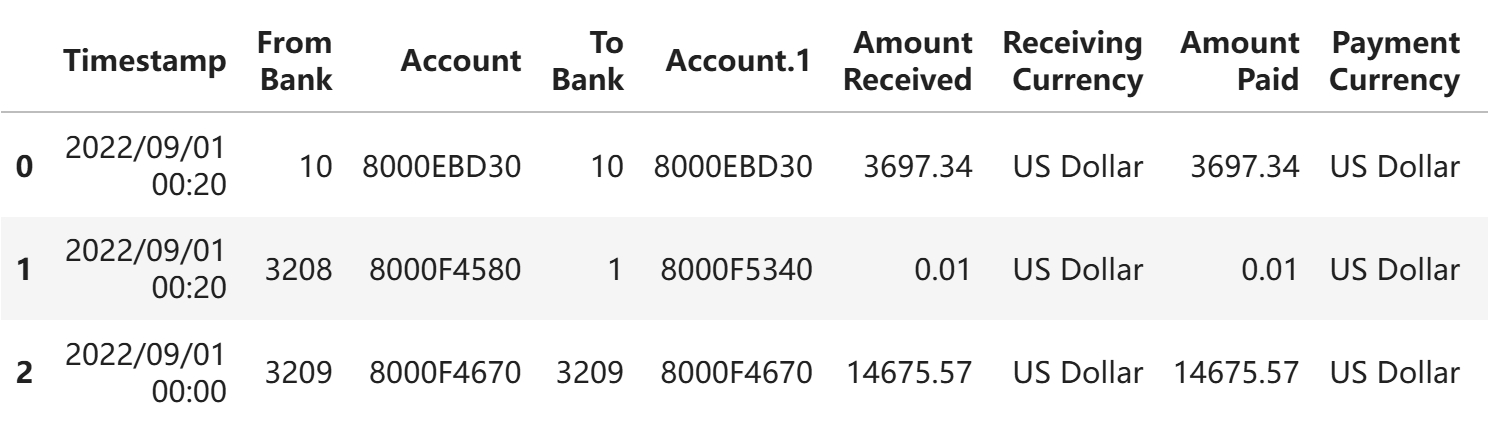
数字类型
df[['Amount Received', 'Amount Paid']].describe()
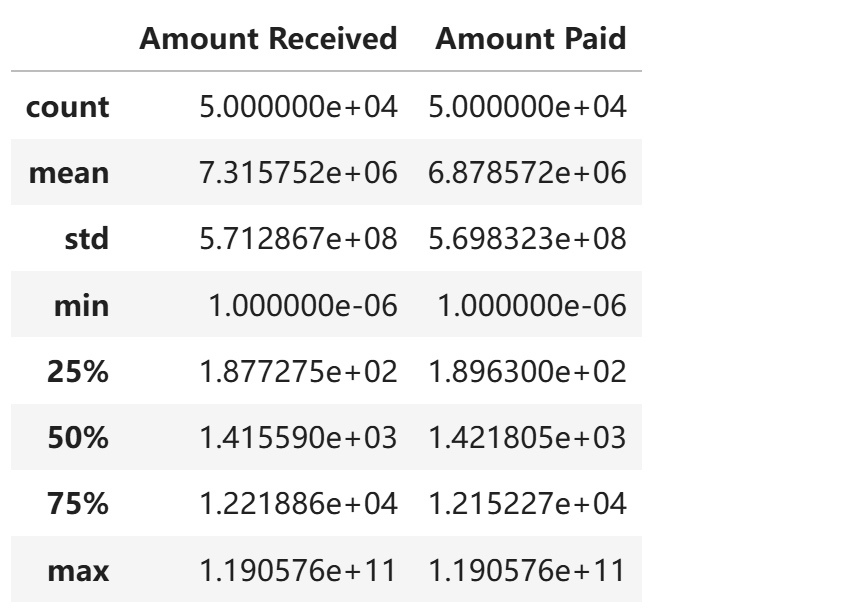
数字看大小分布
类别看频次分布
df[['Account', 'Account.1']].describe()
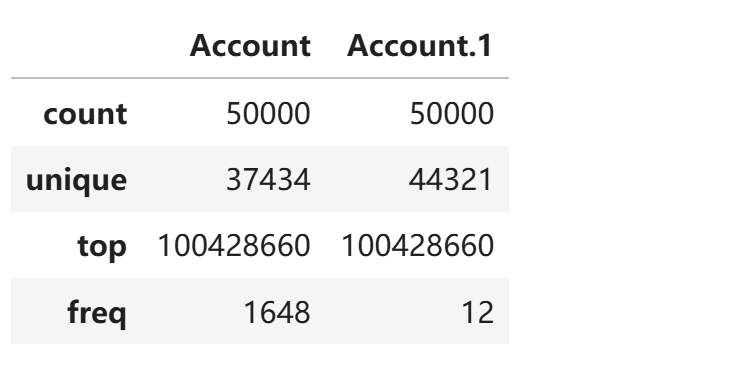
如果列是非数值类型(如字符串或分类类型), describe() 默认只会显示 count、unique(唯一值数量)、 top(出现频率最高的值)和 freq(top 值的出现次数)。
|
df['To Bank'].value_counts()
|
df = raw_df.sample(n=50000, random_state=1) df.shape |
|
|
|
|
数据清洗
df.isnull().sum()
----------------------------------------------------------------------
|
import datetime
import os
import pandas as pd
from sklearn import preprocessing
import numpy as np
import torch
pd.set_option('display.max_columns', None)
data_path = "/wks/datasets/ibm_aml/HI-Small_Trans.csv"
data=pd.read_csv(data_path)
df = data
df[:3]
## Dropping some columns cols_to_drop = ['Timestamp', 'Amount Paid', 'Payment Currency'] df.drop(cols_to_drop, axis=1, inplace=True) df.head(2) |
|
|
|
|
|
|
编码·索引编码
import datetime
import os
from typing import Callable, Optional
import pandas as pd
from sklearn import preprocessing
import numpy as np
import torch
from torch_geometric.data import (
Data,
InMemoryDataset
)
pd.set_option('display.max_columns', None)
data_path = "/wks/datasets/ibm_aml/HI-Small_Trans.csv"
data=pd.read_csv(data_path)
df = data
df[:3]
df.info()
class 'pandas.core.frame.DataFrame'
Index: 50000 entries, 4205263 to 1446591
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Timestamp 50000 non-null object
1 From Bank 50000 non-null int64
2 Account 50000 non-null object
3 To Bank 50000 non-null int64
4 Account.1 50000 non-null object
5 Amount Received 50000 non-null float64
6 Receiving Currency 50000 non-null object
7 Amount Paid 50000 non-null float64
8 Payment Currency 50000 non-null object
9 Payment Format 50000 non-null object
10 Is Laundering 50000 non-null int64
dtypes: float64(2), int64(3), object(6)
memory usage: 4.6+ MB
numeric_cols = df.select_dtypes(exclude="object").columns
numeric_cols
Index(['From Bank', 'To Bank', 'Amount Received', 'Amount Paid',
'Is Laundering'],
dtype='object')
categorical_cols = df.select_dtypes(include="object").columns
categorical_cols
Index(['Timestamp', 'Account', 'Account.1', 'Receiving Currency',
'Payment Currency', 'Payment Format'],
dtype='object')
参考代码 /opt/wks/kejian/zhunbei/dl_kejian/gnn/ibm-aml |
## Unique columns in df
unique_counts = df[categorical_cols].nunique()
print("Unique columns in the DataFrame: \n", unique_counts)
Unique columns in the DataFrame: Timestamp 13001 Account 37434 Account.1 44321 Receiving Currency 15 Payment Currency 15 Payment Format 7 dtype: int64 |
|
LabelEncoder
def df_label_encoder(df, columns):
le = preprocessing.LabelEncoder()
for i in columns:
df[i] = le.fit_transform(df[i].astype(str))
return df
df = df_label_encoder(df,['Payment Format', 'Payment Currency', 'Receiving Currency']) 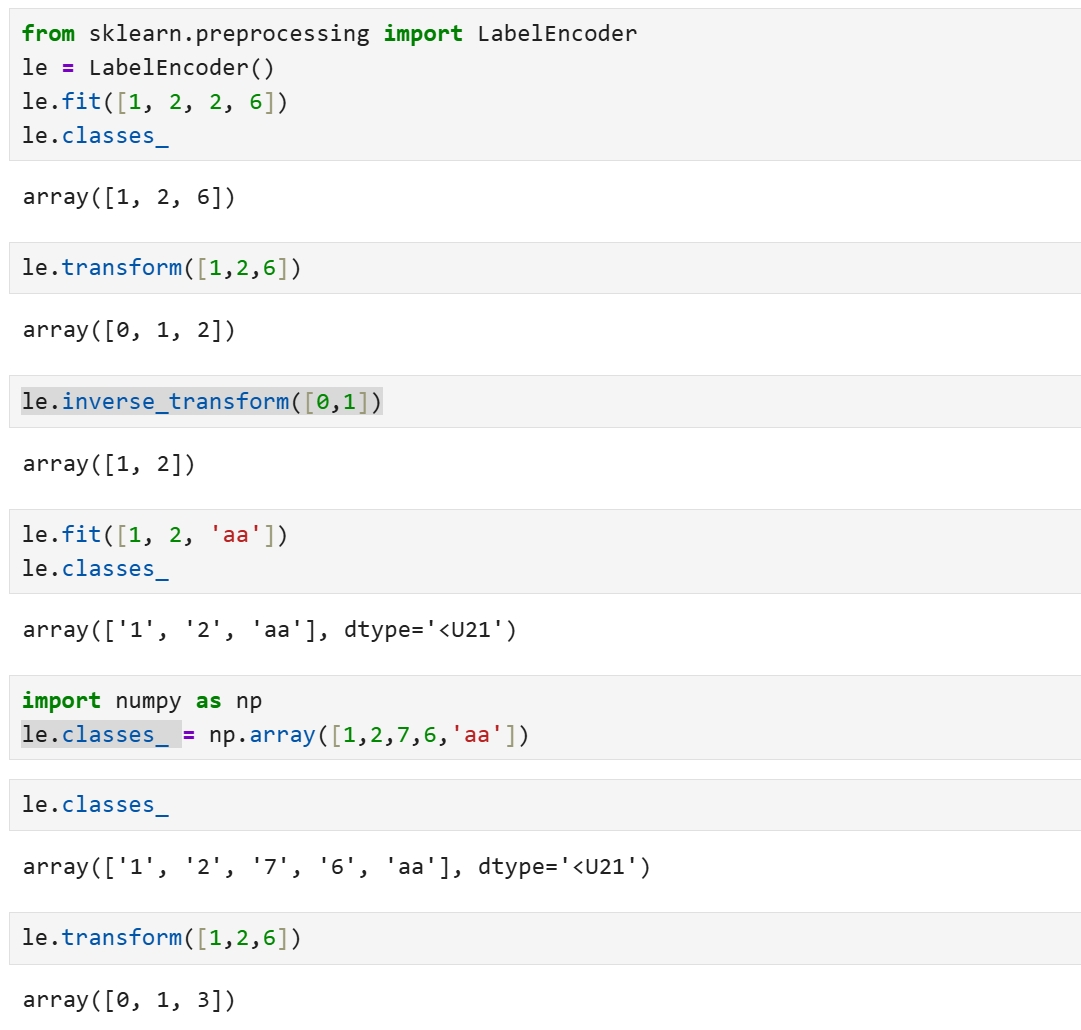
保存类别列表
from sklearn import preprocessing
from tpf import pkl_save,pkl_load
label_encoding_dict_path = "label_encoding_dict.pkl"
def df_label_encoder(df, columns,file_path):
if os.path.exists(file_path):
label_encoding_dict = pkl_load(file_path)
for i in columns:
le = preprocessing.LabelEncoder()
le.classes_ = label_encoding_dict[i]
df[i] = le.transform(df[i].astype(str))
else:
le = preprocessing.LabelEncoder()
label_encoding_dict = {}
for i in columns:
df[i] = le.fit_transform(df[i].astype(str))
label_encoding_dict[i] = le.classes_
pkl_save(label_encoding_dict,file_path=file_path)
return df
df = df_label_encoder(df,['Payment Format', 'Receiving Currency'],label_encoding_dict_path)
df[:3]
|
|
多列共用指定字典,有新类型时自动扩展字典(索引0为未知类型) #IMPORT STATEMENTS import numpy as np import pandas as pd import os BASE_DIR = "/wks/datasets/ibm_aml" data_path = os.path.join(BASE_DIR,"HI-Small_Trans.csv") df=pd.read_csv(data_path) data_test = df.head(2) data_test 
from tpf.d1 import CsvStat st = CsvStat(data=data_test,print_level=2,) cls_dict = st.word2id(["From Bank","Account",'Receiving Currency','Payment Currency', 'Payment Format']) st.head(3) 
银行与账户虽然都是两列,但应该使用同一套索引编码 cls_dict2 = st.word2id(["Account.1"],word2id=cls_dict["Account"]) cls_dict["Account"] = cls_dict2['Account.1'] cls_dict2 = st.word2id(["To Bank"],word2id=cls_dict["From Bank"]) cls_dict["From Bank"] = cls_dict2['To Bank'] st.head(3) 
UNK':0,即每一列的索引0代表未记录的词 |
import pandas as pd
from tpf.link import FeatureEngine
data = {
"c1":["A","B","C"],
"c2":["A","D","E"]
}
df = pd.DataFrame(data)
df
fe = FeatureEngine()
cls_dict = fe.cls2index(df, classify_type=["c1","c2"],word2id={})
cls_dict
{'UNK': 0,
'c1': {'D': 4, 'E': 5, 'A': 1, 'C': 2, 'B': 3},
'c2': {'D': 4, 'E': 5, 'A': 1, 'C': 2, 'B': 3}}
|
import pandas as pd
data = {
"c1":["A","B","C"],
"c2":["A","D","E"]
}
df = pd.DataFrame(data)
print(df)
c1 c2
0 A A
1 B D
2 C E
from tpf.nlp.text import TextEmbedding as tte
tte.col2index(df,classify_type=['c1','c2'],
classify_type2=[],
dict_file="a.dict",
is_pre=False,
word2id=None,)
这是早先的错误版本:所有列做一个字典使用
print(df)
c1 c2
0 1 1
1 3 2
2 4 5
aa = {"a":1}
if "a" in aa:
print(aa["a"])
修正后版本:列与列相互独立,如果需要合并则指定classify_type2
import pandas as pd
data = {
'a1':["a","b","c"],
"c1":["A","B","C"],
"c2":["A","D","E"]
}
df = pd.DataFrame(data)
print(df)
a1 c1 c2
0 a A A
1 b B D
2 c C E
from tpf.nlp.text import TextEmbedding as tte
tte.col2index(df,classify_type=['a1'],
classify_type2=[['c1','c2']],
dict_file="a.dict",
is_pre=False,
word2id=None,)
df
a1 c1 c2
0 3 1 1
1 2 4 3
2 1 2 0
---------------------------------------------------------------------
|
统一量纲
将全体数据集的整个尺度 映射到 [0,1]的范围
或者是[-1,1]这种以0为中心,绝对值在1以内的范围内
最大最小标准化,离散标准化,将数据映射到0-1之间 X = (X - min)/(max - min) 如果最大值 与 最小值中出现异常值,对结果会产生较大的影响 适合 波动不大 的小量数据处理 由于是两个极值想减,有的地方也叫 极差化 也叫线性归一化 折中处理 为了防止min,max出现异常对数据处理造成较大影响 采用99%分位数作为new_max,超出的部分抹去,最大为new_max 采用1%分位数作为new_min ,低于的部分抹去,最小为new_min
from sklearn.preprocessing import MinMaxScaler
preprocess = MinMaxScaler()
raw_data = [[1, 1, 1],
[3, 3, 3],
[1, 2, 3]]
data = preprocess.fit_transform(raw_data)
data
array([[0. , 0. , 0. ],
[1. , 1. , 1. ],
[0. , 0.5, 1. ]])
以向量,向量组的角度看这个矩阵:
第一个向量为
[
1,
3,
1
]
默认是列向量,min=1,max=3,max - min = 2
代入公式,会得到一个
[
0,
1,
0]
的向量
|
(数据-均值)/(标准差 + 1e-6) 标准差就是方差的开平方, 是一个数据分布内部离散量的累加值, 可近似看作 整体数据离“数据中心点”的距离之和 这么一系列操作后,得到的是啥? 将数据转化为均值为0,标准差为1 的正态分布,即标准正态分布 为什么要这么做?为什么呢? 因为数据处理时,处理的多个数据分布,要对比就得有个统一的量纲, 处理方法就是,不管你原来是什么分布,数据的均值多少,离散程度怎么样, 我统一给你转成均值为1方差为1的标准正态分布 这是能够多列一起处理的 基石/起点/前提 这种方法,在数据量大时,异常点对数据处理影响不大 在统计学中,也叫z-score标准化
from sklearn.preprocessing import StandardScaler
preprocess = StandardScaler()
raw_data = [[1, 1, 1],
[3, 3, 3],
[1, 2, 3]]
data = preprocess.fit_transform(raw_data)
data
array([[-0.70710678, -1.22474487, -1.41421356],
[ 1.41421356, 1.22474487, 0.70710678],
[-0.70710678, 0. , 0.70710678]])
海量数据通常都是以正态分布的形式呈现
|
首先是算法层面决定了标签没有归一化的必要 比如, KNN,近邻思想,它取的是训练集X中离样本最近数据的索引, 直接按此索引在标签中取最近n个数 至于这几个数的值是多少,算法根本就不关心,不涉及 又比如决策树,是按某种方法去划分训练集X, 找到一些分支可以更好地分类标签,至于标签的值也不参与计算 再比如神经网络的分类问题,标签onehot编码都是0与1,形成E矩阵, 这是彻底归一了,不需要你再做归一化了 对于连续型变量, 机器学习中基本是近邻思想找到附近的值,取均值 深度学习中,则是会自动计算参数w,该放大就放大,该缩小就缩小, 会自动向标签靠近 另外,除了0与1,其他数据归一后,再返回原形式,前后未必完全相等 比如 >>> 1/3 0.3333333333333333 >>> 1/0.333333 3.0000030000030002 >>> 1/0.3333333 3.00000030000003 >>> 1/333 0.003003003003003003 >>> 1/0.0030030 333.000333000333 标签通常不需要归一化,这主要由算法决定 如果实际场景中需要归一化,也是可以的 |
统一量纲 不是非得归一 重在归于一个统一的数值,1可以,10也可,100也可 由于计算机计算[0,1]之间的数据更容易,两者结合后,归于[0,1] 但思维上不应该限定于1,认为非1不可,可根据场景调整 一些算法将该场景抽离成参数,由用户决定归于一个什么样的数值 大部分情况下,归于0.9完全可行,就是将数据再往下压10%, 这样在计算的过程中数据爆炸的风险就会再低一点 |
虽然对于模型来说,都是在计算数字, 但在输入模型的数据,是会区分哪些特征是连续型,哪此是离散型的 统一量纲只针对连续型特征 对于离散型特征,通常以编码的方式转为数字,然后再决定是否进行归一化处理 |
归一化示例
|
数字的可更新归一化
import pandas as pd
from tpf.link import dtl
# 示例数据
df1 = pd.DataFrame({'A': [1, 2, 3], 'B': [10, 20, 30]})
df2 = pd.DataFrame({'A': [0, 4, 5], 'B': [5, 25, 35]})
df3 = pd.DataFrame({'A': [1.5, 2.5], 'B': [15, 25]})
# 首次执行 (计算并保存 min-max 到 joblib 文件)
processed1 = dtl.min_max_update(df1, num_scaler_file='scaler2.pkl', is_pre=False)
print("Processed df1:\n", processed1)
# 后续执行 (更新 min-max 并重新保存)
processed2 = dtl.min_max_update(df2, num_scaler_file='scaler2.pkl', is_pre=False)
print("Processed df2:\n", processed2)
# 预处理模式 (直接使用保存的 scaler)
processed3 = dtl.min_max_update(df3, num_scaler_file='scaler2.pkl', is_pre=True)
print("Processed df3 (preprocessing mode):\n", processed3)
Processed df1:
A B
0 0.0 0.0
1 0.5 0.5
2 1.0 1.0
Processed df2:
A B
0 0.0 0.000000
1 0.8 0.666667
2 1.0 1.000000
Processed df3 (preprocessing mode):
A B
0 0.3 0.333333
1 0.5 0.666667
深度学习,多次小批量训练时,逐步更新极值
|
|
|
|
|
|
|
|
统一预处理
预处理针对所有数据,包括但不限于训练集,预测集,验证集等
默认训练集的数据包含了业务所需要的全部,
预测集的本意是未来出现的数据,虽然未出现,但它的规律与训练集的规律是一样的
用于归一化的min,max,mean,std等都来自训练集,
将来验证,预测的时候,第一步就是要对数据做同样的预处理
因此,预处理的数据,要做成统一的接口,与模型训练是分开的,是针对所有数据的
|
import numpy as np
np.random.seed(73)
#向量默认为列向量
a1=np.random.randint(low=0,high=10,size=(7,1))
a2=np.random.randint(low=10,high=100,size=(7,1))
a3=np.random.randint(low=100,high=1000,size=(7,1))
#矩阵index=0即第1个维度为列,第2个维度为行
aa = np.concatenate((a1,a2,a3),axis=1)
aa
array([
[ 6, 81, 935],
[ 2, 63, 662],
[ 0, 17, 930],
[ 8, 62, 984],
[ 3, 53, 456],
[ 1, 63, 679],
[ 6, 56, 953]])
min_ = aa.min(axis=0) max_ = aa.max(axis=0) std_ = aa.std(axis=0) min_,max_,std_ ( array([ 0, 17, 456]), array([ 8, 81, 984]), array([ 2.76272566, 18.07806202, 186.85779816]))
#aa是2维矩阵,min_是与aa某个维度相同的向量,这就存在一个广播机制
aa - min_
array([[ 6, 64, 479],
[ 2, 46, 206],
[ 0, 0, 474],
[ 8, 45, 528],
[ 3, 36, 0],
[ 1, 46, 223],
[ 6, 39, 497]])
#这里存在两次广播机制
(aa - min_)/(max_ - min_)
array([[0.75 , 1. , 0.90719697],
[0.25 , 0.71875 , 0.39015152],
[0. , 0. , 0.89772727],
[1. , 0.703125 , 1. ],
[0.375 , 0.5625 , 0. ],
[0.125 , 0.71875 , 0.42234848],
[0.75 , 0.609375 , 0.94128788]])
mean_ = aa.mean(axis=0)
#这里存在3次广播机制,std+1e-6 也是一次
(aa-mean_)/(std_+1e-6)
array([[ 0.82734 , 1.35918481, 0.72323905],
[-0.620505 , 0.36350291, -0.73776499],
[-1.34442751, -2.18101748, 0.69648073],
[ 1.55126251, 0.30818725, 0.98547054],
[-0.25854375, -0.18965369, -1.8402076 ],
[-0.98246626, 0.36350291, -0.64678672],
[ 0.82734 , -0.02370671, 0.81956899]])
|
保留训练集的以下列信息,与模型一起交付: 连续型数据列:最大值,最小值,均值,标准差 离散型数据列:不重复值 以及个数 如果数据量大,需要分批计算后合并 ------------------------------------------------------------ |
|
|
|
|
过拟合
开始训练的时候,模型的精度 在训练集上不断增加 在测试集上不断增加 并且训练集与测试集增长幅度近似 过拟合: 当训练到一定程度,训练集上的精度还在增加, 但测试集上的精度不再增加,甚至出现下降, 此时,模型把不通用的事物也学了,结果在测试集上并不应验...
参考