数值计算
GPU加速的NumPy替代品(需NVIDIA GPU),相同API但速度提升10-100倍。
适用场景:大规模数值计算、矩阵运算。
安装:pip install cupy-cuda11x(根据CUDA版本选择)
|
支持自动微分、GPU/TPU加速,兼容NumPy API,适合高性能数值计算和机器学习。
优势:即时编译(JIT)、自动并行化。
安装:pip install jax jaxlib
|
并行计算库,可处理大于内存的数据集,兼容Pandas/NumPy API。 适用场景:分布式计算或内存不足时。 安装:pip install dask |
|
|
|
|
数据框处理(替代Pandas)
基于Rust编写,多核并行处理,比Pandas快5-10倍,内存效率更高。
API类似Pandas,支持惰性评估。
安装:pip install polars
|
惰性计算、零内存复制,适合超大数据集(如TB级)。
优势:虚拟列、快速聚合。
安装:pip install vaex
|
分布式Pandas后端(基于Ray或Dask),无需修改代码即可加速。 适用场景:透明扩展Pandas到多核/集群。 安装:pip install modin |
|
|
|
|
高性能计算
将Python函数编译为机器码,加速数值计算(需装饰器标注)。
适用场景:优化循环或数学密集型函数。
安装:pip install numba
|
虽然主要用于深度学习,但其张量操作在CPU/GPU上远超NumPy。
适用场景:矩阵运算、自动微分。
|
|
|
|
|
|
|
列式存储 & 超大数据 & 优化建议
提供高效内存格式,与Polars/Vaex等集成,加速I/O操作。 安装:pip install pyarrow
|
|
性能对比示例 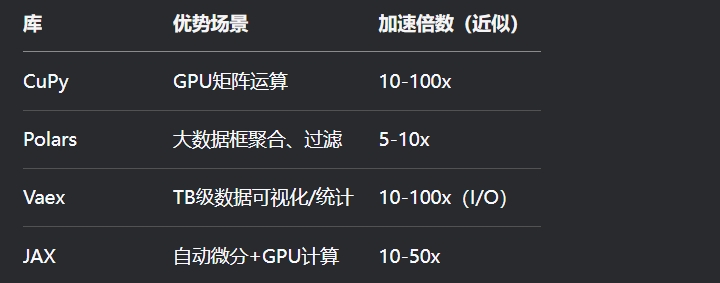
选择建议
GPU可用 → 优先尝试 CuPy 或 JAX。
大数据处理 → 选 Polars(单机)或 Dask(分布式)。
无需改代码 → 用 Modin 无缝替换Pandas。
数学密集型函数 → Numba 编译优化。
这些库通常通过并行化、惰性计算、内存优化
最好设计成可插拔的方式,可以方便地切换某个工具 |
|
|
|
|
|
|
参考文章