VggNet
VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE -SCALE IMAGE RECOGNITION
arXiv:1409.1556v6 [cs.CV] 10 Apr 2015
Karen Simonyan∗ & Andrew Zisserman+
Visual Geometry Group, Department of Engineering Science, University of Oxford
Table 1: ConvNet configurations (shown in columns).
The depth of the configurations increases from the left (A) to the right (E),
as more layers are added (the added layers are shown in bold).
The convolutional layer parameters are denoted as “convhreceptive field sizei-hnumber of channelsi”.
The ReLU activation function is not shown for brevity.
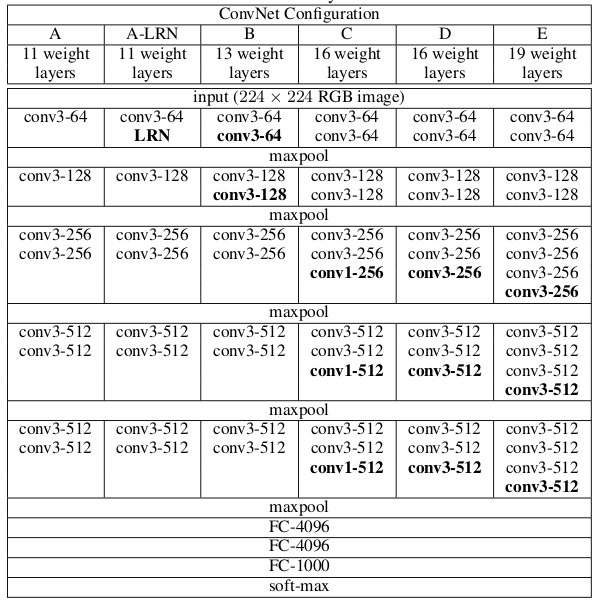
vgg16 D conv3-64:核为3,卷积将特征变换到64,或者说是从64个维度提取数据特征 conv3-64: maxpool:使用maxpool收缩特征图 conv3-128:核为3,卷积将特征变换到128,或者说是从128个维度提取数据特征 总体来说,VGG是用于大量图像识别的,从A到E参数变多,可以识别的图像量就越大 
卷积的层数: 卷积与全连接算一层, maxpool,BN,RuLE等不算层,算组件 conv1-512与conv3-512 1与3表示卷积核为1与3: conv1-512:kernel_size=1,stripe=1,padding=0 conv3-512:kernel_size=3,stripe=1,padding=1 通道变换,in_channels,out_channels,控制特征的变换 卷积核控制滑动取窗,由kernel_size,stripe,padding三个参数控制 其他 LRN是类似于BN功能的一个组件,但没有发展起来 vgg16,19较常用 |
import torch
from torch import nn
class VggNet(nn.Module):
"""
自定义Vgg网络
"""
def __init__(self):
super(VggNet, self).__init__()
# 提取特征
self.features = nn.Sequential(
# stage1
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
# maxpool
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
# stage2
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=128),
nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=128),
nn.ReLU(),
# maxpool
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
# stage3
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=256),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=256),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=256),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=256),
nn.ReLU(),
# maxpool
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
# stage4
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
# maxpool
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
# stage5
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
# maxpool
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
)
# 统一形状
self.avgpool = nn.AdaptiveAvgPool2d(output_size=(7, 7))
# 做分类
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Flatten(),
nn.Linear(in_features=25088, out_features=4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=1000)
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
o = self.classifier(x)
return o
imgs = torch.randn(3,3,224,224) model = VggNet() model(imgs).shape 参数量 sum(x.numel() for x in model.parameters()) 143678248 |
|
主体流程 卷积提取特征:卷啊卷,激活,池化 # 统一形状 self.avgpool = nn.AdaptiveAvgPool2d(output_size=(7, 7)) 全连接分类 Dropout 因为信息量大,dropout起到弱化过拟合的作用 信息量 VGG给出一种提示/暗示/方式,处理数据的信息量大,那么对应的网络层数也多 结构顺序 同时,VGG进一步遵从了 卷积 -- BN - RELU -- MAXPOOL 这种结构顺序 但个人(仅个人观点),认为 卷积 -- MAXPOOL - RELU - BN 更符合各层的含义 |
|
|
|
|
VGG详解
|
## VGG 网络结构
VGGNet 由牛津大学 Visual Geometry Group 于 2014 年提出,核心思想是使用**小卷积核(3×3)堆叠**来替代大卷积核。
### VGG-16 结构
```
输入(224×224×3)
→ Conv(64×2) → MaxPool
→ Conv(128×2) → MaxPool
→ Conv(256×3) → MaxPool
→ Conv(512×3) → MaxPool
→ Conv(512×3) → MaxPool
→ Flatten → FC(4096) → Dropout → FC(4096) → Dropout → FC(1000)
```
**各层详情**:
| 块 | 层 | 配置 | 输出尺寸 |
|---|-----|------|----------|
| 1 | 2×Conv + MaxPool | 64通道, 3×3 | 112×112×64 |
| 2 | 2×Conv + MaxPool | 128通道, 3×3 | 56×56×128 |
| 3 | 3×Conv + MaxPool | 256通道, 3×3 | 28×28×256 |
| 4 | 3×Conv + MaxPool | 512通道, 3×3 | 14×14×512 |
| 5 | 3×Conv + MaxPool | 512通道, 3×3 | 7×7×512 |
| FC | 3×FC | 4096→4096→1000 | - |
### VGG-19 结构
与 VGG-16 类似,但在第3、4、5块中各增加一个卷积层:
- 块3:3→4层
- 块4:3→4层
- 块5:3→4层
|
|
## 核心思想
### 为什么使用 3×3 卷积核?
**两个 3×3 卷积 = 一个 5×5 卷积的感受野**:
$$ receptive\\_field(3×3 + 3×3) = 3 + (3-1) = 5 $$
**三个 3×3 卷积 = 一个 7×7 卷积的感受野**:
$$ receptive\\_field(3×3 + 3×3 + 3×3) = 3 + 2×(3-1) = 7 $$
### 优势
| 特性 | 大卷积核(7×7) | 小卷积核堆叠(3×3×3) |
|------|--------------|---------------------|
| 参数量 | $7×7×C×C = 49C²$ | $3×(3×3×C×C) = 27C²$ |
| 非线性次数 | 1 | 3 |
| 表达能力 | 较弱 | 更强 |
**结论**:更少的参数量,更多的非线性,更强的表达能力!
|
|
## 参数量分析
**VGG-16 参数量**:
| 层类型 | 参数量 | 占比 |
|--------|--------|------|
| 卷积层 | ~14.7M | 10.6% |
| 全连接层 | ~124M | 89.4% |
| **总计** | **~138M** | **100%** |
**关键发现**:
- 虽然 VGG 使用小卷积核减少了卷积层参数量
- 但全连接层仍然占据了绝大部分参数量(89.4%)
- 后续网络(如 GoogLeNet、ResNet)通过全局平均池化替代全连接层来解决这个问题
|
|
## 代码实现
```python
import tensorflow as tf
def vgg_block(num_convs, num_channels):
"""VGG块:num_convs个卷积层 + 1个MaxPool"""
blk = tf.keras.models.Sequential()
for _ in range(num_convs):
blk.add(tf.keras.layers.Conv2D(
num_channels, kernel_size=3,
padding='same', activation='relu'))
blk.add(tf.keras.layers.MaxPool2D(pool_size=2, strides=2))
return blk
# VGG-16
conv_arch = ((2, 64), (2, 128), (3, 256), (3, 512), (3, 512))
def vgg(conv_arch):
net = tf.keras.models.Sequential()
# 卷积层部分
for (num_convs, num_channels) in conv_arch:
net.add(vgg_block(num_convs, num_channels))
# 全连接层部分
net.add(tf.keras.layers.Flatten())
net.add(tf.keras.layers.Dense(4096, activation='relu'))
net.add(tf.keras.layers.Dropout(0.5))
net.add(tf.keras.layers.Dense(4096, activation='relu'))
net.add(tf.keras.layers.Dropout(0.5))
net.add(tf.keras.layers.Dense(1000))
return net
net = vgg(conv_arch)
```
|
参考