Mod
oracle sql ,交易流水表,
判断一个金额刚好是10000的整数倍,是则按客户进行sum,否则为0
transactions (
customer_id NUMBER,
amount NUMBER
)
SELECT
customer_id,
SUM(
CASE
WHEN MOD(amount, 10000) = 0 THEN amount
ELSE 0
END
) AS total_amount
FROM
transactions
GROUP BY
customer_id;

MOD(amount, 10000) = 0:判断金额是否为 10000 的整数倍。
CASE WHEN ... THEN amount ELSE 0 END:符合条件则保留金额,否则返回 0。
SUM(...):对每个客户进行汇总求和。
GROUP BY customer_id:按客户分组统计。
|
|
|
|
|
|
|
|
select
SELECT [DISTINCT] column1, column2, ...
FROM table_name
[WHERE condition]
[GROUP BY column1, column2, ...]
[HAVING group_condition]
[ORDER BY column1 [ASC|DESC], ...];
DISTINCT:去重,针对整个select语句中的所有列形成的向量进行去重
- 即一个select语句中最多有一个distinct
---------------------------------------------------------------------------------
|
|
|
|
|
|
|
|
with
WITH cte_name1 AS (
SELECT column1, column2, ...
FROM table1
WHERE condition1
),
cte_name2 AS (
SELECT columnA, columnB, ...
FROM table2
WHERE condition2
)
SELECT * FROM cte_name1
JOIN cte_name2 ON cte_name1.column1 = cte_name2.columnA;
WITH dept_salaries AS (
SELECT department_id, SUM(salary) AS total_salary
FROM employees
GROUP BY department_id
),
avg_salary AS (
SELECT AVG(total_salary) AS avg_total_salary
FROM dept_salaries
)
SELECT d.department_id, d.total_salary
FROM dept_salaries d
JOIN avg_salary a ON 1=1 -- 这里只是为了演示,实际中可能需要更复杂的连接条件
WHERE d.total_salary > a.avg_total_salary;
|
WITH a AS (
SELECT id, new_value
FROM some_table
WHERE some_condition -- 定义你的条件
)
UPDATE b
SET value = (
SELECT a.new_value
FROM a
WHERE a.id = b.id
)
WHERE EXISTS (
SELECT 1
FROM a
WHERE a.id = b.id
);
----------------------------------------------------------------- |
|
|
|
|
|
|
聚合函数
函数 描述 示例
COUNT() 计数 SELECT COUNT(*) FROM employees;
SUM() 求和 SELECT SUM(salary) FROM employees;
AVG() 平均值 SELECT AVG(salary) FROM employees;
MAX() 最大值 SELECT MAX(salary) FROM employees;
MIN() 最小值 SELECT MIN(salary) FROM employees;
LISTAGG() 字符串聚合
SELECT LISTAGG(name, ',') WITHIN GROUP (ORDER BY name) FROM employees;
将name列中的值按 "," 串为一行
|
|
有无ELSE的区别
SELECT
COUNT(
CASE
WHEN CURR_CD='1' AND LENGTH(NVL(T.TRAN_IP, '') ) > 0
THEN 1
END
) AS count1,
COUNT(
CASE
WHEN CURR_CD='1' AND LENGTH(NVL(T.TRAN_IP, '') ) > 0
THEN 1 ELSE 0
END
) AS count2 , count(*) AS count_all
FROM TRANS_SMALL_01 t ;
第一个 COUNT(无 ELSE 0)
COUNT(
CASE
WHEN CURR_CD='1' AND LENGTH(NVL(T.TRAN_IP, '')) > 0
THEN 1
END
)
逻辑: 只计算满足 WHEN 条件的行(即 CURR_CD='1' 且 TRAN_IP 非空), 不满足条件的行会被忽略(即 NULL,不计入 COUNT)。 结果:返回 满足条件的行数。 第二个 COUNT(带 ELSE 0)
COUNT(
CASE
WHEN CURR_CD='1' AND LENGTH(NVL(T.TRAN_IP, '')) > 0
THEN 1
ELSE 0 -- 这里的关键区别!
END
)
逻辑: 满足条件的行返回 1(计入 COUNT)。 不满足条件的行返回 0(仍然计入 COUNT)。 结果: 返回 所有行的数量(因为 COUNT 会计算所有非 NULL 值,而 0 是非 NULL 的)。 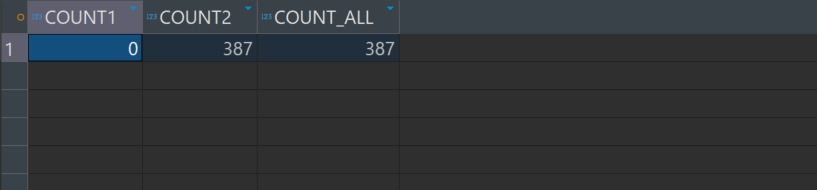
where条件位置的区别 SELECT t.PARTY_ID, /** 我行客户号 */ COUNT(CASE WHEN t.CURR_CD = '1' THEN 1 END) AS CNY_TRANS_COUNT, /** 本币交易次数 */ COUNT(CASE WHEN t.CURR_CD = '2' THEN 1 END) AS FOR_TRANS_COUNT /** 外币交易次数 */ FROM TRANS_SMALL_01 t WHERE t.TRCD_COUNTRY != 'CHN' /** IP归属地国别不等于中国 */ GROUP BY t.PARTY_ID 
SELECT t.PARTY_ID, /** 我行客户号 */ COUNT(CASE WHEN t.CURR_CD = '1' AND t.TRCD_COUNTRY != 'CHN' THEN 1 END) AS CNY_TRANS_COUNT, /** 本币交易次数 */ COUNT(CASE WHEN t.CURR_CD = '2' AND t.TRCD_COUNTRY != 'CHN' THEN 1 END) AS FOR_TRANS_COUNT /** 外币交易次数 */ FROM TRANS_SMALL_01 t GROUP BY t.PARTY_ID 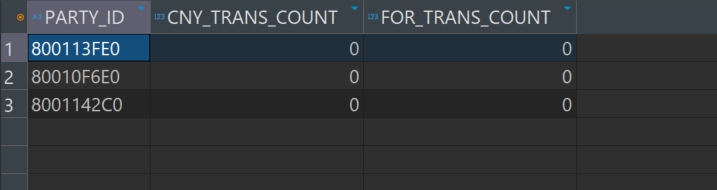
|
|
|
|
|
|
|
分组查询 (GROUP BY)
SELECT department_id, COUNT(*) as emp_count
FROM employees
GROUP BY department_id;
|
SELECT department_id, AVG(salary) as avg_salary FROM employees GROUP BY department_id HAVING AVG(salary) > 5000;
|
SELECT department_id, job_id, COUNT(*) as emp_count FROM employees GROUP BY department_id, job_id; |
|
|
|
|
分析函数 (窗口函数)
SELECT employee_id, first_name, salary,
ROW_NUMBER() OVER (ORDER BY salary DESC) as rank
FROM employees;
select student_id, row_number() over(partition by student_id order by sumbit_data desc) RN from students;
row_number() 为每组中的每行数据分一个行号,不管它们的值是否相同,就是单纯地按行编号
|
|
RANK()
RANK() 根据指定的排序条件为结果集中的每一行分配一个排名。
如果两行或多行的排序值相同,则它们会获得相同的排名。
但是,排名会跳过,后续的排名会根据相同值的行数递增。
例如,如果有两行并列第1名,下一行的排名将是第3名(跳过第2名)。
RANK() OVER (PARTITION BY column_name ORDER BY column_name [ASC|DESC])
- PARTITION BY:可选,用于将数据分组。如果不指定,则对整个结果集进行排名。
- ORDER BY:指定排序的列和顺序。
salesperson | sales_amount
------------|-------------
Alice | 500
Bob | 700
Charlie | 700
David | 400
SELECT salesperson, sales_amount,
RANK() OVER (ORDER BY sales_amount DESC) AS rank
FROM sales;
salesperson | sales_amount | rank
------------|-------------|-----
Bob | 700 | 1
Charlie | 700 | 1
Alice | 500 | 3
David | 400 | 4
Bob 和 Charlie 的销售额相同,因此它们共享第1名。
Alice 的排名是第3名(跳过了第2名)。
DENSE_RANK() DENSE_RANK() 的行为与 RANK() 类似,也是根据指定的排序条件为每一行分配排名。 如果两行或多行的排序值相同,则它们会获得相同的排名。 但排名不会跳过,后续的排名会紧接在相同排名值之后。 例如,如果有两行并列第1名,下一行的排名将是第2名。
DENSE_RANK() OVER (PARTITION BY column_name ORDER BY column_name [ASC|DESC])
参数与 RANK() 相同
SELECT salesperson, sales_amount,
DENSE_RANK() OVER (ORDER BY sales_amount DESC) AS dense_rank
FROM sales;
salesperson | sales_amount | dense_rank
------------|-------------|-----------
Bob | 700 | 1
Charlie | 700 | 1
Alice | 500 | 2
David | 400 | 3
Bob 和 Charlie 的销售额相同,因此它们共享第1名。
Alice 的排名是第2名(没有跳过第2名)
PARTITION BY:分组
SELECT TICD, CNY_AMT,
RANK() OVER (PARTITION BY CNY_AMT ORDER BY CNY_AMT ) AS rn
from TRANS WHERE rownum < 7;
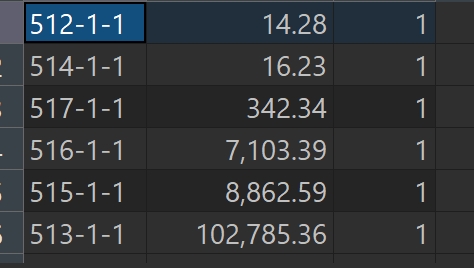
SELECT TICD, CNY_AMT,
RANK() OVER (ORDER BY CNY_AMT ) AS rn
from TRANS WHERE rownum < 7;
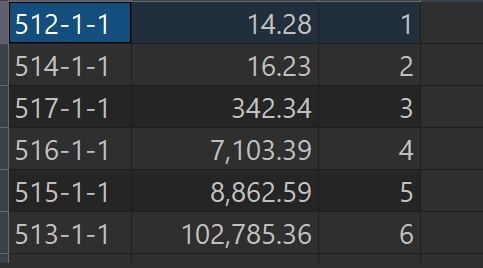
使用场景 RANK(): 适用于需要跳过排名的场景,例如计算“前N名”时,可能会忽略中间跳过的排名。 DENSE_RANK(): 适用于需要连续排名的场景,例如分组统计中,排名需要连续递增。
|
SELECT department_id, employee_id, first_name, salary,
AVG(salary) OVER (PARTITION BY department_id) as dept_avg_salary
FROM employees;
|
|
|
|
|
字符函数
CONCAT() 连接字符串
SELECT CONCAT(first_name, ' ', last_name) FROM employees;
SUBSTR() 子字符串
SELECT SUBSTR('Oracle', 2, 3) FROM dual; → 'rac'
INSTR() 查找位置
SELECT INSTR('Oracle', 'a') FROM dual; → 3
LENGTH() 字符串长度
SELECT LENGTH('Oracle') FROM dual; → 6
UPPER()/LOWER() 大小写转换
SELECT UPPER('Oracle') FROM dual; → 'ORACLE'
TRIM() 去除空格
SELECT TRIM(' Oracle ') FROM dual; → 'Oracle'
--------------------------------------------------------------------------------------
|
|
前导0
SQL> select to_char(11111,'0000000000000009999') nn from dual;
NN
--------------------
0000000000000011111
参考
https://www.php.cn/faq/490026.html
|
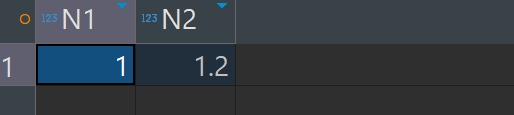
SELECT to_number('1') n1,to_number('1.2') n2 FROM dual;
|
|
REPLACE() 替换字符串
SELECT REPLACE('Oracle', 'a', 'i') FROM dual; -→ 'Oricle'
SELECT REPLACE('Oracle', 'Ora', '') FROM dual; -→ cle
REGEXP_REPLACE
REGEXP_REPLACE(
source_string,
pattern,
replacement_string,
[position],
[occurrence],
[match_parameter]
)
source_string: 要搜索的源字符串。
pattern: 正则表达式模式,用于匹配需要替换的部分。
replacement_string: 替换匹配部分的字符串。
position(可选):从源字符串的哪个位置开始搜索,默认为 1。
occurrence(可选):
- 指定替换第几次出现的匹配项,
- 默认为 0(替换所有匹配项)。
match_parameter(可选):
匹配参数,如 'i'(不区分大小写)、'c'(区分大小写)、'n'(允许 . 匹配换行符)等。
occurrence 英/əˈkʌrəns/ 美/əˈkɜːrəns/ n. 发生;出现;存在;发生的事情;存在的事物
替换所有数字为 X
SELECT REGEXP_REPLACE('Oracle 123 is fun!', '[0-9]+', 'X') AS result
FROM dual;
Oracle X is fun!
[0-9]+ 匹配一个或多个连续的数字。
所有匹配的数字都被替换为 X
替换第一个匹配项
SELECT REGEXP_REPLACE('Hello World', '[AEIOUaeiou]', '*', 1, 1) AS result
FROM dual;
H*llo World
[AEIOUaeiou] 匹配任意元音字母。
1, 1 表示从第一个字符开始,只替换第一个匹配项。
不区分大小写替换
将字符串中的所有字母 o 替换为 0(不区分大小写)。
SELECT REGEXP_REPLACE('Oracle Oops!', 'o', '0', 1, 0, 'i') AS result
FROM dual;
0racle 00ps!
'i' 参数表示不区分大小写
所有 o 和 O 都被替换为 0
occurrence(可选):
- 指定替换第几次出现的匹配项,
- 默认为 0(替换所有匹配项)。
从特定位置开始替换
从字符串的第 7 个字符开始,将所有字母替换为 #。
SELECT REGEXP_REPLACE('Oracle Database', '.*', '#', 7) AS result
FROM dual;
Oracle #####
.* 匹配任意字符(贪婪匹配)。
从第 7 个字符开始,剩余的部分被替换为 #。
替换特定模式的字符串
将字符串中的 abc 或 xyz 替换为 123。
SELECT REGEXP_REPLACE('abc def xyz ghi', 'abc|xyz', '123') AS result
FROM dual;
123 def 123 ghi
abc|xyz 使用 | 表示“或”的关系,匹配 abc 或 xyz
所有匹配的部分都被替换为 123
格式化电话号码
将电话号码格式化为 (XXX) XXX-XXXX 的形式。
SELECT REGEXP_REPLACE('1234567890', '(\d{3})(\d{3})(\d{4})', '(\1) \2-\3') AS formatted_phone
FROM dual;
(123) 456-7890
(\d{3}) 捕获三个数字,\1、\2、\3 分别引用捕获的组。
将捕获的组重新组合为 (XXX) XXX-XXXX 的格式。
|
|
|
日期函数
SYSDATE 当前日期时间
SELECT SYSDATE FROM dual;
ADD_MONTHS() 添加月份
SELECT ADD_MONTHS(SYSDATE, 3) FROM dual;
MONTHS_BETWEEN() 月份差
SELECT MONTHS_BETWEEN('01-JAN-2023', '01-MAR-2023') FROM dual; → -2
LAST_DAY() 月份最后一天
SELECT LAST_DAY(SYSDATE) FROM dual;
NEXT_DAY() 下一个周几
SELECT NEXT_DAY(SYSDATE, 'FRIDAY') FROM dual;
EXTRACT() 提取日期部分
SELECT EXTRACT(YEAR FROM SYSDATE) FROM dual;
|
|
|
|
|
|
|
|
条件表达式
SELECT employee_id, first_name, salary,
CASE
WHEN salary > 10000 THEN 'High'
WHEN salary > 5000 THEN 'Medium'
ELSE 'Low'
END as salary_level
FROM employees;
--------------------------------------------------------------------
|
SELECT employee_id, first_name,
DECODE(job_id, 'IT_PROG', 'Programmer',
'SA_REP', 'Sales Rep',
'Other') as job_title
FROM employees;
---------------------------------------------------------------------------------
|
SELECT NVL(commission_pct, 0) as commission, -- 如果为NULL返回0
NVL2(commission_pct, 'Has', 'No') as has_commission, -- 非NULL返回Has,NULL返回No
COALESCE(commission_pct, manager_id, 0) as first_non_null -- 返回第一个非NULL值
FROM employees;
COALESCE 英/ˌkəʊəˈles/ 美/ˌkoʊəˈles/ vi. 合并;结合;联合 NVL: - 接受两个参数。 - 语法:NVL(expr1, expr2) - 如果 expr1 为 NULL,则返回 expr2;否则,返回 expr1。 - 适用于简单的空值替换场景。 COALESCE: - 接受两个或多个参数。 - 语法:COALESCE(expr1, expr2, ..., exprn) - 返回参数列表中第一个非空值。如果所有参数都为 NULL,则返回 NULL - 可以处理多个表达式,返回第一个非空值
CREATE TABLE employees (
employee_id NUMBER,
first_name VARCHAR2(50),
middle_name VARCHAR2(50),
last_name VARCHAR2(50)
);
-- 示例数据
INSERT INTO employees (employee_id, first_name, middle_name, last_name) VALUES (1, 'John', NULL, 'Doe');
INSERT INTO employees (employee_id, first_name, middle_name, last_name) VALUES (2, 'Jane', 'A.', 'Smith');
-- 使用 COALESCE 获取完整姓名
SELECT
employee_id,
first_name || ' ' || COALESCE(middle_name, '') || ' ' || last_name AS full_name
FROM
employees;
在查询中,COALESCE(middle_name, '') 用于处理可能为空的中间名。 如果 middle_name 为 NULL,COALESCE(middle_name, '') 将返回空字符串,从而避免在连接姓名时出现多余的 NULL 值。 |
|
|
|
|
集合操作
-- 合并两个查询结果(去重) SELECT employee_id FROM employees WHERE department_id = 10 UNION SELECT employee_id FROM employees WHERE salary > 10000;
-- 合并两个查询结果(不去重)
SELECT employee_id FROM employees WHERE department_id = 10
UNION ALL
SELECT employee_id FROM employees WHERE salary > 10000;
|
-- 返回两个查询的交集
SELECT employee_id FROM employees WHERE department_id = 10
INTERSECT
SELECT employee_id FROM employees WHERE salary > 10000;
|
-- 返回第一个查询有而第二个查询没有的结果 SELECT employee_id FROM employees WHERE department_id = 10 MINUS SELECT employee_id FROM employees WHERE salary > 10000; |
|
|
|
|
PL/SQL·块结构
DECLARE
-- 变量声明
v_employee_id NUMBER := 100;
v_salary employees.salary%TYPE;
BEGIN
-- 执行部分
SELECT salary INTO v_salary
FROM employees
WHERE employee_id = v_employee_id;
-- 条件判断
IF v_salary > 10000 THEN
DBMS_OUTPUT.PUT_LINE('High salary');
ELSE
DBMS_OUTPUT.PUT_LINE('Normal salary');
END IF;
-- 异常处理
EXCEPTION
WHEN NO_DATA_FOUND THEN
DBMS_OUTPUT.PUT_LINE('Employee not found');
END;
--------------------------------------------------------------------------
|
|
|
|
|
|
|
|
参考文章
Oracle用户密码过期,修改永不过期