skill概述
|
渐进式加载:引导大模型思考,或者定制思考模板 2. **分析代码结构** - 识别代码的主要组成部分:文件头、函数/类定义、关键逻辑块 - 根据 [references/language-guide.md](references/language-guide.md) 了解目标语言的注释规范 3. **生成注释内容** - 根据 [references/comment-styles.md](references/comment-styles.md) 选择合适的注释风格 - 为文件添加文件头注释(说明文件用途、作者、日期等) - 为函数/类添加文档注释(说明功能、参数、返回值) - 为复杂逻辑添加行内注释(解释关键算法和业务逻辑) 本质还是提示词 但方式是渐近式加载,先引导大模型思考,或者定制思考模板,再让它执行 当然,它也支持工具调用 如果你的描述足够精准,会自动使用该技能; 如果不够精准,模型会先思考如何使用这个技能,再执行 - skillsmp.com 
元技能:生成技能的技能 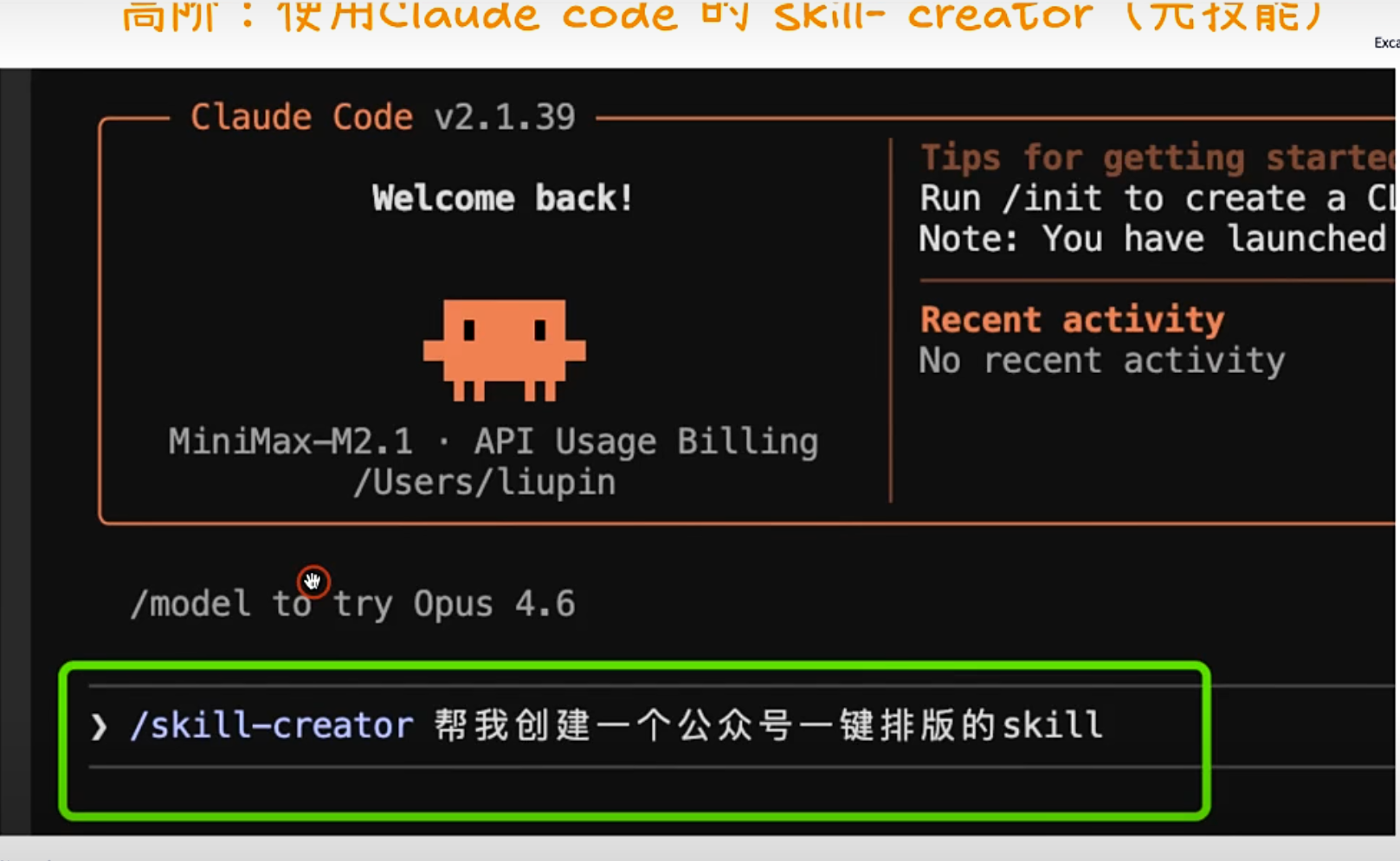

- SKILL.md:就解决文档过长的问题 - 是模型本身在读取SKILL.md,到某一步发现需要读某个文档时,就去读 - 这是模型的能力,模型自身拥有的能力 - 它类似于agent智能处理,也类似于工作流流式处理的能力 使用建议:先去搜索类似别人做好的 
|
|
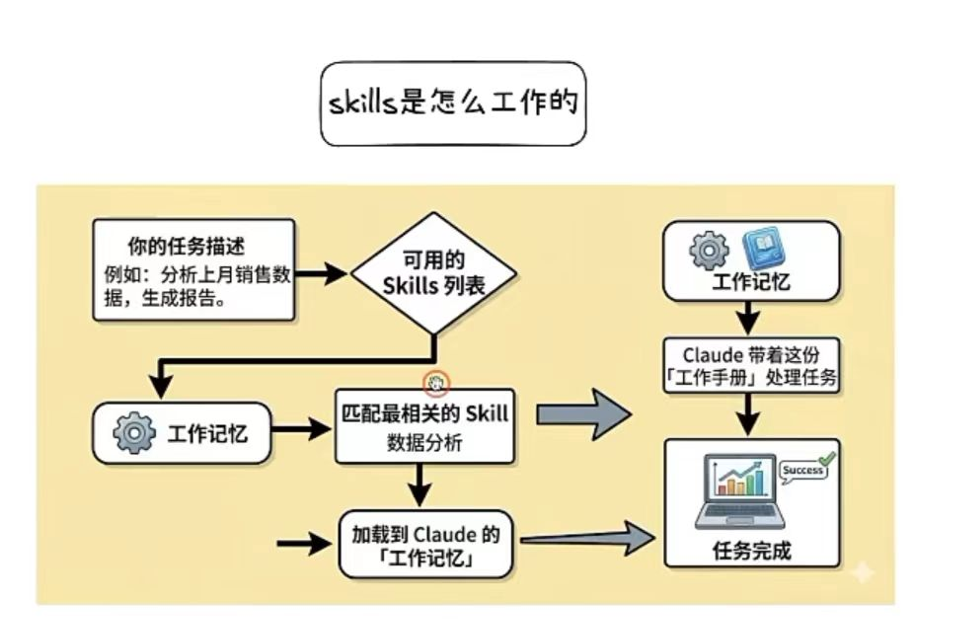
标准化、可复用: 把每个任务做深做精,然后再串联起来 大模型的“技能”(Skills)是标准化、可复用的任务执行模块,相当于“AI的专业资格证”; 而智能体(Agent)是能自主规划、协调资源的完整系统,相当于“AI的项目经理”。 两者并非替代关系,而是执行层与调度层的分工。 当前行业共识正从“造一个万能智能体”转向“沉淀高质量技能生态”。 以下从定义、核心差异、优劣势对比三个维度展开。 |
--- name: code-commenter description: 自动为代码文件插入适当注释;支持多种编程语言和注释风格;保持代码原格式和缩进 --- # Code Commenter ## 任务目标 - 本 Skill 用于:为代码文件自动生成并插入注释,提高代码可读性 - 能力包含:代码语义分析、注释生成、代码格式保持、多语言支持 - 触发条件:用户要求"为代码添加注释"、"解释这段代码"、"为函数添加文档"等 ## 前置准备 - 无需额外依赖,智能体直接处理代码文件 - 确保目标代码文件可读写 ## 操作步骤 ### 标准流程 1. **读取代码文件** - 使用 `read_file` 读取目标代码文件完整内容 - 识别编程语言(通过文件扩展名或代码特征) 2. **分析代码结构** - 识别代码的主要组成部分:文件头、函数/类定义、关键逻辑块 - 根据 [references/language-guide.md](references/language-guide.md) 了解目标语言的注释规范 3. **生成注释内容** - 根据 [references/comment-styles.md](references/comment-styles.md) 选择合适的注释风格 - 为文件添加文件头注释(说明文件用途、作者、日期等) - 为函数/类添加文档注释(说明功能、参数、返回值) - 为复杂逻辑添加行内注释(解释关键算法和业务逻辑) 4. **插入注释** - 使用 `edit_file` 或 `write_file` 在适当位置插入注释 - 保持原代码的缩进和格式 - 确保注释使用正确的语言符号(# // /* */等) 5. **验证修改** - 确认注释插入位置正确 - 验证代码逻辑未受影响 - 检查注释内容准确清晰 ### 可选分支 - **当仅添加文件头注释**:执行步骤1→2→3(文件头)→4→5 - **当仅添加函数文档**:执行步骤1→2→3(函数)→4→5 - **当处理多个文件**:对每个文件依次执行完整流程 ## 资源索引 - 领域参考:见 [references/comment-styles.md](references/comment-styles.md)(何时读取:选择注释风格时) - 领域参考:见 [references/language-guide.md](references/language-guide.md)(何时读取:识别编程语言后) ## 注意事项 - 仅在需要时读取参考文档,保持上下文简洁 - 注释应简洁明了,避免过度注释 - 保持注释与代码同步更新 - 优先使用目标语言的标准注释规范(如Python的docstring) - 插入注释时必须使用原文件的完整上下文,确保 `old_content` 唯一且准确 ## 使用示例 ### 示例1:为Python函数添加注释 - 功能说明:为单个Python文件中的函数添加docstring - 执行方式:智能体自然语言处理 - 关键要点:使用三引号docstring格式,说明参数和返回值 ### 示例2:为JavaScript文件添加完整注释 - 功能说明:为JS文件添加文件头、函数文档和关键逻辑注释 - 执行方式:智能体自然语言处理 - 关键要点:使用JSDoc风格,包含@params和@return ### 示例3:批处理多个Python文件 - 功能说明:为项目中多个.py文件添加注释 - 执行方式:智能体逐文件处理 - 关键要点:统一注释风格,保持一致性 |
|
# Skill 机制详解
## 目录
1. [Skill 机制简介](#一skill-机制简介)
2. [Skill 工作流程](#二skill-工作流程)
3. [Skill 比单纯 Prompt 更好用](#三skill-比单纯-prompt-更好用)
4. [Skill 典型文件目录结构](#四skill-典型文件目录结构)
5. [SKILL.MD 内容简介](#五skillmd-内容简介)
6. [Skill 各个目录作用](#六skill-各个目录作用)
7. [Skill 触发方式](#七skill-触发方式)
8. [Skill 在智能体整体架构的位置](#八skill-在智能体整体架构的位置)
9. [Skill 和 Tool / MCP / Prompt 的区别](#九skill-和-tool--mcp--prompt-的区别)
10. [例子:AI 安全评测报告 Skill](#十例子ai-安全评测报告-skill)
11. [Skill 设计关键点](#十一skill-设计关键点)
12. [Skill 目录位置](#十二skill-目录位置)
13. [Skill 的本质](#十三skill-的本质)
14. [最小可用模板](#十四最小可用模板)
---
## 一、Skill 机制简介
从原理上看,Skill 解决的是一个老问题:**大模型本身会推理,但不擅长长期稳定地重复执行固定流程。**
比如你希望一个智能体做到这些事:
- 遇到"分析日志"类任务,就按固定排障流程来
- 遇到"生成周报"类任务,就套某个模板
- 遇到"改代码"类任务,要先跑测试、再改、再回归
- 遇到"处理 PDF"类任务,要调用固定脚本,而不是每次都靠模型自由发挥
如果你每次都把这些规则写进 Prompt,会有几个问题:
- Prompt 很长,浪费上下文
- 每次都要重复写
- 容易漏规则
- 模型执行不稳定
所以 Skill 的核心思想是:**把某一类任务的"操作知识"模块化,平时只保留一个简短索引,需要时再展开。**
OpenAI 的 Codex 文档明确提到,Skill 使用 **progressive disclosure(渐进式披露)**:系统先只看 Skill 的元数据,比如 `name`、`description`、路径等;只有模型判断当前任务匹配这个 Skill 时,才加载完整的 `SKILL.md` 内容。
## 二、Skill 工作流程
你可以把一次调用想成 4 步:
### 1. 先注册技能
系统里有一批 Skill,每个 Skill 都是一个目录,最核心文件是 `SKILL.md`。其中至少会写两件事:
- `name`
- `description`
这两个字段是最关键的"索引"。OpenAI 和 GitHub Copilot 的文档都要求 `SKILL.md` 必须存在,并且要包含这些基础元数据。
> **百度搜索的 Skill 结构**:每次和大模型交互都会把 `name` 和 `description` 里的内容塞进大模型的 Prompt 里去,模型根据 `description` 判断是否需要使用这个 Skill。
### 2. 运行时先做"技能匹配"
当用户提一个任务,比如:
- "帮我排查 GitHub Actions 为什么挂了"
- "把这个目录里的图片批量转 PNG"
- "按团队规范生成发布说明"
系统不会把所有 Skill 全文都加载进模型,而是**先看 Skill 的 `description`**,判断哪些 Skill 可能相关。Codex 文档里说得很直白:隐式触发主要依赖 `description`。这个很关键,**节省大量不必要的 Token**(当轮对话不需要用到的 Skill 的详情描述)。
### 3. 命中后加载 Skill 详情
一旦某个 Skill 被选中,系统会把该 Skill 的 `SKILL.md` 注入当前上下文。GitHub Copilot 文档也是类似说法:当 Copilot 选择使用某个 Skill 时,`SKILL.md` 会被注入到 Agent Context 中。
### 4. 按技能说明执行,并调用配套资源
此时模型会:
- 按 `SKILL.md` 的步骤执行
- 读取 Skill 目录里的参考文档
- 必要时运行 Skill 附带脚本
- 用模板、Schema、样例文件来约束输出格式
所以,Skill 其实是一个 **"模型推理 + 外部资源 + 固定流程"** 的组合体。
## 三、Skill 比单纯 Prompt 更好用
它的价值主要有 4 个:
### 1. 减少上下文膨胀
不是每个任务都加载全部规则,只在匹配时展开。这个就是 Skill **最重要的工程价值**。
### 2. 把流程沉淀成可复用资产
例如:
- "发版检查 Skill"
- "漏洞报告撰写 Skill"
- "安全评测报告 Skill"
- "日志排障 Skill"
这些都可以在团队里复用,而不是每个人都重新写 Prompt。
### 3. 把不稳定的步骤外包给脚本
Skill 可以带脚本,模型负责理解和决策,确定性的机械操作交给脚本。OpenAI 的博客专门建议把 **mechanics** 放进 scripts。
### 4. 更适合团队协作
因为它本质上是**目录和文件**,能进 Git 仓库,能评审,能版本管理,能 CI 化。
## 四、Skill 典型文件目录结构
现在主流实现里,最常见的目录大致长这样:
```
skills/
└── my-skill/
├── SKILL.md # 必需:技能定义、元数据、执行说明
├── scripts/ # 可选:可执行脚本
│ ├── run.sh
│ └── parse.py
├── references/ # 可选:参考文档
│ ├── API.md
│ └── examples.md
├── assets/ # 可选:模板、静态资源、schema
│ ├── template.md
│ └── output_schema.json
└── agents/
└── openai.yaml # 可选:某些平台的额外配置
```
这个结构和 OpenAI Codex 文档给出的结构基本一致:`SKILL.md` 必需,`scripts/`、`references/`、`assets/` 可选,另外还能有 `agents/openai.yaml`。
很多社区仓库也采用类似形态,比如 Streamlit 的 agent-skills 仓库同样把 Skill 定义为"一个目录 + 必需的 `SKILL.md` + 可选 supporting directories"。
## 五、SKILL.MD 内容简介
最小可用版本一般是:
```markdown
---
name: github-actions-failure-debugging
description: Guide for debugging failing GitHub Actions workflows. Use this when asked to debug failing GitHub Actions workflows.
---
按照下面流程排查:
1. 先查看最近 workflow run
2. 总结失败 job 日志
3. 必要时再拉完整日志
4. 输出根因、影响范围、修复建议
```
GitHub Copilot 官方文档明确说 `SKILL.md` 是 Markdown 文件,前面带 YAML frontmatter,至少包含:
- `name`
- `description`
正文则写给 Agent 的执行说明、示例、约束。
OpenAI 的技能文档也是同样要求:`SKILL.md` 必须包含 `name` 和 `description`。
## 六、Skill 各个目录作用
### 1. `SKILL.md`
这是**入口文件**,作用相当于:
- 索引
- 触发条件说明
- 执行流程说明
- 输出约束说明
它最像"给模型看的 SOP"。
### 2. `scripts/`
这里放真正可执行的东西,比如:
- shell 脚本
- Python 脚本
- 小工具 CLI
适合做**确定性步骤**,比如:
- 批量转换文件
- 解析日志
- 生成固定格式输出
- 校验 JSON/Schema
- 调 API 拉取数据
OpenAI 博客建议把这种机械、确定的流程放到脚本中,而不是让模型自己"想办法做"。
### 3. `references/`
这里是补充知识,通常不是每次都要读,但需要时可以读,比如:
- 团队规范
- 接口说明
- 业务背景
- 样例文档
- Playbook
它的作用是**避免把大量背景知识硬塞进 `SKILL.md`**。
### 4. `assets/`
放静态资源,例如:
- 模板
- 示例输入输出
- Schema
- 词表
- 配置片段
- 图片、表格等资源
这类内容通常不是"知识说明",而是被 Skill 直接引用的材料。
### 5. `agents/openai.yaml`
这是某些平台的额外配置文件。OpenAI 文档里提到它可用于 appearance 和 dependencies 之类的附加元数据。
你可以把它理解成**"平台相关配置层"**,不是所有 Skill 都必须有。
## 七、Skill 触发方式
一般有两种:
### 1. 显式触发
用户或开发者直接指定:
- 用某个 Skill
- 在命令里点名某个 Skill
- 在 UI 里选择某个 Skill
OpenAI Codex 文档里就说了,Codex 可以被显式调用 Skill。
### 2. 隐式触发
系统根据用户任务语义,**自动匹配 Skill 的 `description`**,命中后再加载。
所以 `description` **不能乱写**。它不只是"介绍",实际上还是**一个路由规则**。
## 八、Skill 在智能体整体架构的位置
如果把智能体系统拆层,Skill 大概在这一层:
```
用户任务
↓
任务理解 / 路由
↓
skill 匹配
↓
加载 skill 说明与资源
↓
模型推理 + 工具调用 + 脚本执行
↓
产出结果
```
所以它本质上不是"模型参数的一部分",也不是"底层工具本身"。
更准确地说,它是:**位于提示层和工具层之间的一层"能力编排封装"**。
它把:
- 任务说明
- 工具使用规范
- 执行顺序
- 输出格式
- 参考资料
这些原本零散的东西,封装成一个可复用单元。
## 九、Skill 和 Tool / MCP / Prompt 的区别
这个很容易混。
### Skill vs Prompt
- **Prompt**:一次性的指令
- **Skill**:可复用、可管理、可按需加载的指令包
### Skill vs Tool
- **Tool**:具体能力接口,比如读文件、发请求、执行 shell
- **Skill**:告诉模型"什么时候用哪些 Tool,按什么流程用"
所以 **Tool 更像"手"**,**Skill 更像"作业指导书"**。
### Skill vs MCP
- **MCP**:更像给 Agent 提供外部系统能力的**协议/接入层**
- **Skill**:更像基于这些能力封装的**工作流**
可以简单理解为:
- **MCP** 负责"接进来"
- **Tool** 负责"能调用"
- **Skill** 负责"怎么用得对"
## 十、例子:AI 安全评测报告 Skill
比如你做一个"AI 安全评测报告" Skill。
目录可能是这样:
```
skills/
└── ai-safety-report/
├── SKILL.md
├── references/
│ ├── scoring-rule.md
│ └── report-outline.md
├── assets/
│ ├── report-template.md
│ └── labels.json
└── scripts/
└── summarize_results.py
```
### `SKILL.md` 里写:
- **什么时候触发**:当用户要求写 AI 安全评测报告、测评结论、风险概览时
- **必须先做什么**:先读测试结果,再按模板归纳
- **输出格式**:先写总评,再写分维度结论,再写案例
- **禁止做什么**:不要编造分数,不要扩展未提供的测评样本
### `references/`
- 打分规则
- 你们团队内部术语规范
### `assets/`
- 报告模板
- 风险标签映射表
### `scripts/`
- 自动把 JSON 测试结果汇总成 Markdown 表格
这样模型就不会每次都"自由创作",而是按你想要的方式干活。
## 十一、Skill 设计关键点
### 1. `description` 要能路由
`description` 不是广告文案,而是**"匹配条件"**。
应该写清楚:
- 这个 Skill 做什么
- 什么时候用
- 什么时候不要用
OpenAI 文档明确建议把 **scope 和 boundary** 写清楚,因为隐式匹配依赖 `description`。
### 2. `SKILL.md` 不要写成百科全书
主说明要短,细节拆到 `references/`。
### 3. 把确定性逻辑放脚本
例如解析、转换、校验、汇总,都适合放 `scripts/`。
### 4. 输出格式尽量明确
最好给:
- 模板
- 示例
- Schema
- 禁止项
### 5. 让 Skill 可审计、可版本化
因为它本质是文件目录,所以非常适合进 Git 管理。
## 十二、Skill 目录位置
"Skill 长什么样"比较一致,但"放在哪儿"会因平台不同而变。
例如 GitHub Copilot 文档里提到,项目级 Skill 可以放在:
- `.github/skills/`
- `.claude/skills/`
个人级 Skill 可以放在:
- `~/.copilot/skills/`
- `~/.claude/skills/`
OpenAI 的博客示例里则提到 repo-local skills 常放在:
- `.agents/skills/`
OpenClaw 的 Skills 根据来源分了几个地方:
- `~/.openclaw/skills`
- `
|
|
|
skill·使用
|
web73页面模板更新
请使用/ai/wks/elec/skills/web73-template-updater工具对/ai/wks/web73/views/xuetu目录下以llm_开头的html页面进行更新
阅读/home/xt/wks/xy/skills/web73-template-updater这个技能
请使用web73-template-updater工具对web73/views/xuetu目录下以math_开头的html页面进行更新
- 交互式沟通
--------------------
### 生成skills
```
按照下面的要求,生成一个skills
```
## 页面模板更新
### 任务背景
web73(一个使用了模板的go gin html前端) 项目中的 页面需要统一引入必要的 JavaScript 库和模板组件,以支持 Markdown 渲染、数学公式显示和数据可视化功能。
### 更新内容
对 `D:\wks\web73\views\xuetu\` 目录下所有以 `fibu_` 为前缀的 HTML 页面进行标准化更新:
**Head 标签添加内容**:
```html
<script type="text/javascript" src="/static/js/d3.711.js"></script>
<script type="text/javascript" src="/static/js/page.js"></script>
<script type="text/javascript" src="/static/js/marked.min.js"></script>
{{template "header_css" .}}
```
**Body 结束标签前添加**:
```html
{{template "header_js" .}}
```
### 更新规则
1. **完整页面更新** - 如果 HTML 页面包含 `<head>` 标签,则进行更新
2. **组件模板跳过** - 如果页面没有 `<head>` 标签(如 `rust_tab.html`),则跳过,因为它们只是其他页面的组件部分
```
1. 我希望 `D:\wks\web73\views\xuetu\` 目录,即web73所在的目录可以 作为参数输入,或者能灵活指定,
2. 以 `fibu_` 为前缀的页面,以什么格式为前缀,我也希望可以灵活指定,比如在描述时可以改变为以其他的名称为开头,比如,以llm_为开头,以nlp_为开头 ,希望可以通过以自然语言的方式指定
3. 当我提到"web73页面模板更新"时应该触发该skills
```
### 使用
```
web73页面模板更新
请使用/ai/wks/elec/skills/web73-template-updater工具对/ai/wks/web73/views/xuetu目录下以llm_开头的html页面进行更新
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
CoPaw
|
https://mp.weixin.qq.com/s/Rrnh3civ6LN5kaWPqYeRtw
## python环境配置
```
xt@u24:~/app/bin$ ll
total 24
drwxrwxr-x 5 xt xt 4096 Mar 9 20:45 ./
drwxrwxr-x 3 xt xt 4096 Mar 9 20:35 ../
drwxr-xr-x 2 xt xt 4096 Dec 23 10:49 micromamba_arm64/
-rwxr-xr-x 1 xt xt 866 Dec 23 11:36 micromamba_setup.sh*
drwxr-xr-x 4 xt xt 4096 Dec 23 10:54 micromamba_windows/
drwxr-xr-x 2 xt xt 4096 Dec 23 10:49 micromamba_x86_64/
xt@u24:~/app/bin$
xt@u24:~/app/bin$ ./micromamba_setup.sh
```
```
export PATH=/home/xt/app/bin:$PATH
$ which micromamba
/wks/python/bin/micromamba
export MAMBA_EXE='/home/xt/app/bin/micromamba';
export MAMBA_ROOT_PREFIX='/python/micromamba';
micromamba shell init --shell bash --root-prefix=$MAMBA_ROOT_PREFIX
micromamba create -n py313 python=3.13
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
openclaw
|
帮我用pyinaturalist爬取凤蝶科的图片资料,按属种分目录存储,文件名最好加上原作者账号 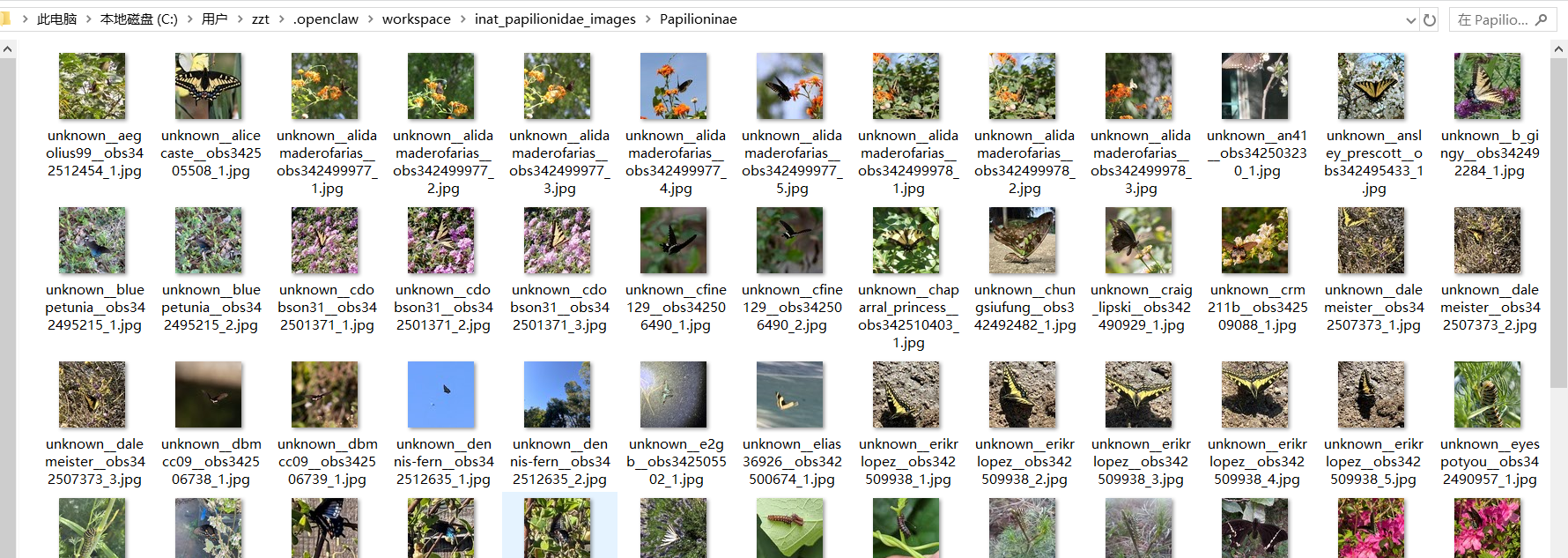
|
|
|
|
|
|
|
|
|
|
|
|
|
ironclaw
IronClaw:用 Rust 打造的"偏执级"安全 AI 助手,你的数据终于不用再裸奔了
https://mp.weixin.qq.com/s/h4pP3-1OyTbpVDPp6XMACg
那有没有一个既保留了 OpenClaw 强大能力、又从根本上解决安全问题的方案?
有。NEAR Protocol 的联合创始人 Illia Polosukhin 带着团队,用 Rust 从零重写了一个——IronClaw。
名字里带个"Iron"(铁),安全理念也确实硬核到底:你的 AI 助手,应该为你工作,而不是对付你。
IronClaw 到底是什么简单说,IronClaw 是一个开源的私人 AI 助手。
它继承了 OpenClaw 的全部好用特性——管理消息、自动执行任务、
连接各种聊天工具——同时用 Rust 语言重新构建了整个底层,把"安全"二字刻进了 DNA。
如果拿现实生活做类比,
OpenClaw 就像你雇了一个能力超强但"管不住手"的助手,你得时刻盯着他别乱翻你的抽屉。
而 IronClaw 更像是你雇了一个带着"安全等级"门禁卡的助手——他只能进你允许的房间,
带着手套操作你的文件,任何可疑动作都会被实时监控和拦截。
看看它的主要定位:
- 🔒 数据不出你的电脑:所有信息本地存储、加密保管
- 🔍 代码完全透明:开源可审计,没有隐藏的遥测和数据采集
- 🧩 能力自动扩展:需要什么工具?描述一下它就帮你造
- 🛡️ 纵深防御:多层安全机制防止提示注入和数据泄露
安全性到底有多"偏执"这是 IronClaw 最值得说道的地方。
它不是象征性地加了个密码就完事,而是搭建了一套完整的"洋葱式"安全架构。
WASM 沙箱隔离所有不受信任的工具都在 WebAssembly 容器里运行。
你可以把它想象成一个"数字防弹玻璃房"——工具在里面干活,但碰不到外面的东西。
具体措施包括:
基于能力的权限控制:要访问网络?得申请。
要读密钥?先审批端点白名单:
HTTP 请求只能发往你明确批准的地址
密钥注入机制:敏感信息在宿主边界注入,WASM 代码根本看不到原始密钥
泄露检测:自动扫描所有请求和响应,发现有人"夹带私货"立刻拦截提示注入防御
现在 AI 应用最大的安全隐患之一就是提示注入——恶意内容假装是新指令来"劫持" AI。
IronClaw 对此搞了三道防线:
模式检测:识别已知的注入套路
内容清洗:对外部输入做转义处理
策略引擎:支持"阻断/警告/审查/清洗"
四种处理级别数据加密存储所有数据都存在你自己的 PostgreSQL 数据库中,
密钥使用 AES-256-GCM 算法加密。
重点是——没有遥测、没有数据分析、没有任何数据共享。
所有工具执行都有完整的审计日志。
|
多通道覆盖
它支持 REPL 命令行、HTTP Webhooks、
WASM 通道(对接 Telegram、Slack 等)和 Web 网关等多种接入方式。
换句话说,你想怎么跟它聊就怎么聊。
自动化引擎
内置 Cron 定时任务、事件触发器、Webhook 处理器。
你可以让它每天早上 9 点帮你刷新数据,或者接到特定通知时自动执行预设流程。
还有"心跳系统"一直在后台跑,主动帮你巡检和维护。
智能记忆系统 IronClaw 使用 全文搜索 + 向量搜索 的混合检索方案(基于倒数排名融合算法), 这意味着它不仅记得你说过什么,还能理解语义关联。 它有弹性的文件系统工作空间,能保存笔记、日志和上下文。 还有"身份文件"功能,保证它在不同对话中保持一致的风格和偏好。 自我扩展 这是它的"杀手锏"之一。你描述一下需要什么功能,IronClaw 会自动把它构建成一个 WASM 工具。 还支持 MCP(模型上下文协议)连接外部服务, 以及插件式架构——扔一个新的 WASM 工具进去,不用重启就能用。 |
IronClaw 是受 OpenClaw 启发的 Rust 重实现版本,但两者有几个关键差异: 语言选择:TypeScript → Rust。 Rust 的内存安全特性从编译阶段就杜绝了缓冲区溢出、空指针、数据竞争等经典安全漏洞。 同时还能编译成单个二进制文件,部署极其简单。 沙箱方案:Docker → WASM。 Docker 容器体积大、启动慢,适合服务端部署; WASM 容器轻量、启动快、权限粒度更细,更适合本地工具隔离的场景。 数据存储:SQLite → PostgreSQL。 前者适合轻量应用,后者是生产级方案,支持向量搜索插件 pgvector, 天然适合 AI 应用的语义检索需求。 安全思路: OpenClaw 的安全性需要用户自己操心(比如建议跑在树莓派上做隔离), IronClaw 则是"安全融入设计"——从架构层面就为你兜底。 |
|
|
|
|
|
|
|
|
|
|
ironclaw·安装
|
环境要求 Rust 1.85 以上 PostgreSQL 15 以上(需安装 pgvector 扩展) NEAR AI 账号(安装向导会引导你完成认证) 安装方式
Windows 用户可以下载安装包,也可以用 PowerShell 一行搞定:
irm https://github.com/nearai/ironclaw/releases/latest/download/ironclaw-installer.ps1 | iex
macOS/Linux 用户也有对应的脚本:
curl --proto '=https' --tlsv1.2 -LsSf https://github.com/nearai/ironclaw/releases/latest/download/ironclaw-installer.sh | sh
安装完成后运行 ironclaw onboard,向导会帮你配置数据库连接、NEAR AI 认证和密钥加密。
选择 AI 模型
IronClaw 默认使用 NEAR AI 提供的模型,但它兼容任何 OpenAI 格式的 API 端点。
也就是说,你可以接 OpenRouter(300+ 模型可选)、Together AI、Fireworks AI,甚至用 Ollama 跑本地模型。
真正的"模型自由"。
GitHub 仓库:https://github.com/nearai/ironclaw
|
|
```
xt@qisan:/wks/app/pg$ gcc --version|grep ubuntu
gcc (Ubuntu 9.4.0-1ubuntu1~20.04.2) 9.4.0
```
```
sudo su - postgres
pg_ctl -D /wks/app/pg/data -l logfile start
psql -U postgres
postgres=# \password
Enter new password for user "postgres":Book_1234
Enter it again:
postgres-# \q
```
```
-- 创建用户 tpf,密码为 Book_1234
CREATE USER tpf WITH PASSWORD 'Book_1234';
-- 创建数据库 db1
CREATE DATABASE db1;
-- 将数据库所有权授予 tpf(可选,根据需要)
GRANT ALL PRIVILEGES ON DATABASE db1 TO tpf;
```
|
|
```
curl https://sh.rustup.rs -sSf | sh
source "$HOME/.cargo/env"
$ which rustc
/home/xt/.cargo/bin/rustc
$ rustc --version
rustc 1.92.0 (ded5c06cf 2025-12-08)
```
|
|
```
xt@qisan:~$ curl --proto '=https' --tlsv1.2 -LsSf https://github.com/nearai/ironclaw/releases/latest/download/ironclaw-installer.sh | sh
System glibc version (`2.31') is too old; checking alternatives
ERROR: no compatible downloads were found for your platform x86_64-unknown-linux-gnu
xt@qisan:~$ cat /etc/os-release
NAME="Ubuntu"
VERSION="20.04.6 LTS (Focal Fossa)"
```
安装24.04
|
|
### pg
#### 安装
pg需要编译,因此需要重新安装
sudo apt install bison flex libreadline-dev
sudo apt install -y libicu-dev pkg-config
mkdir -p /wks/app/pg/pg17/{data,walback}
adduser postgres
chown -R postgres:postgres /wks/app/pg
su - postgres
cd /wks/app/pg
wget https://ftp.postgresql.org/pub/source/v17.6/postgresql-17.6.tar.gz
tar -xvf postgresql-17.6.tar.gz
PGHOME=/wks/app/pg/pg17
PGDATA=$PGHOME/data
ARCLOG_PATH=$PGHOME/walback
PATH=$PGHOME/bin:$PATH
export PGHOME PGDATA ARCLOG_PATH PATH
cd /wks/app/pg/postgresql-17.6/
./configure --prefix=/wks/app/pg/pg17
make
make install
$ pg_config --version
PostgreSQL 17.6
$ which pg_config
/wks/app/pg/pg17//bin/pg_config
#### 初始化
initdb
initdb -D /wks/app/pg/pg17/data -U postgres --encoding=UTF8 --locale=en_US.UTF-8
pg_ctl -D /wks/app/pg/pg17/data -l logfile start
psql -U postgres
postgres=# \password
Enter new password for user "postgres":Book_1234
Enter it again:
-- 创建用户 tpf,密码为 Book_1234
CREATE USER tpf WITH PASSWORD 'Book_1234';
-- 创建数据库 db1
CREATE DATABASE db1;
-- 将数据库所有权授予 tpf(可选,根据需要)
GRANT ALL PRIVILEGES ON DATABASE db1 TO tpf;
postgres-# \q
$ pg_ctl stop
waiting for server to shut down.... done
server stopped
|
|
|
|
|
|
|
ironclaw·docker
|
## 快捷键
- pg1: sudo docker start u24;sudo docker exec -it u24 su - postgres
- pgs1: pg_ctl -D /home/postgres/app/pg17/data -l logfile start
- pgs2: /home/postgres/app/pg17/bin/pg_ctl stop
## pg安装
```
apt update
apt install bison flex libicu-dev pkg-config wget sudo vim curl
apt install libreadline-dev zlib1g-dev libz-dev git
adduser postgres
su - postgres
mkdir -p ~/app/pg17/{data,walback}
cd ~/app
wget https://ftp.postgresql.org/pub/source/v17.6/postgresql-17.6.tar.gz
tar -xvf postgresql-17.6.tar.gz
PGHOME=/home/postgres/app/pg17
PGDATA=$PGHOME/data
ARCLOG_PATH=$PGHOME/walback
PATH=$PGHOME/bin:$PATH
export PGHOME PGDATA ARCLOG_PATH PATH
cd ~/app/postgresql-17.6/
./configure --prefix=/home/postgres/app/pg17
make
make install
```
## pg初始化
```
initdb
pg_ctl -D /home/postgres/app/pg17/data -l logfile start
psql -U postgres
postgres=# \password
Enter new password for user "postgres":Book_1234
Enter it again:
postgres-# \q
CREATE USER tpf WITH PASSWORD 'Book_1234';
CREATE DATABASE db1;
GRANT ALL PRIVILEGES ON DATABASE db1 TO tpf;
```
## vec插件安装
```
$ pg_config --version
PostgreSQL 17.6
tar -xvf pgvector0.8.1.tar.gz
cd pgvector
make
sudo make install
```
```
$ psql -U postgres
psql (17.6)
Type "help" for help.
postgres=# CREATE EXTENSION vector;
CREATE EXTENSION
postgres=# SELECT vector_dims('[1,2,3]'::vector);
vector_dims
-------------
3
(1 row)
postgres=# SELECT * FROM pg_extension WHERE extname = 'vector';
oid | extname | extowner | extnamespace | extrelocatable | extversion | extconfig | extcond
ition
-------+---------+----------+--------------+----------------+------------+-----------+--------
------
16390 | vector | 10 | 2200 | t | 0.8.1 | |
(1 row)
```
|
|
```
curl https://sh.rustup.rs -sSf | sh
source "$HOME/.cargo/env"
$ which rustc
/home/xt/.cargo/bin/rustc
$ rustc --version
rustc 1.92.0 (ded5c06cf 2025-12-08)
```
alias xt1="sudo docker start u24;sudo docker exec -it u24 su - xt"
|
|
linux
curl --proto '=https' --tlsv1.2 -LsSf https://github.com/nearai/ironclaw/releases/latest/download/ironclaw-installer.sh | sh
```
xt@u24:~$ curl --proto '=https' --tlsv1.2 -LsSf https://github.com/nearai/ironclaw/releases/latest/download/ironclaw-installer.sh | sh
downloading ironclaw 0.16.1 x86_64-unknown-linux-gnu
installing to /home/xt/.cargo/bin
ironclaw
ironclaw-update
everything's installed!
启动pg数据库
postgres@u24:~$ pgs1
pg_ctl: another server might be running; trying to start server anyway
waiting for server to start.... done
server started
xt@u24:~$ ironclaw onboard
postgres://postgres:Book_1234@127.0.0.1:5432/db1
Select storage method:
[1] OS Keychain (recommended for local installs)
[2] Environment variable (for CI/Docker)
[3] Skip (disable secrets features)
> 2
1
Provider:
[1] NEAR AI - multi-model access via NEAR account
[2] Anthropic - Claude models (direct API key)
[3] OpenAI - GPT models (direct API key)
[4] Ollama - local models, no API key needed
[5] OpenRouter - 200+ models via single API key
[6] OpenAI-compatible - custom endpoint (vLLM, LiteLLM, etc.)
> 1
```
```
xt@u24:~$ ironclaw onboard
╭─────────────────────────╮
│ IronClaw Setup Wizard │
╰─────────────────────────╯
Step 1/9: Database Connection
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
ℹ Which database backend would you like to use?
Select a database backend:
[1] PostgreSQL - production-grade, requires a running server
[2] libSQL - embedded SQLite, zero dependencies, optional Turso cloud sync
> 1
ℹ Enter your PostgreSQL connection URL.
ℹ Format: postgres://user:password@host:port/database
Database URL: postgres://tpf:Book_1234@127.0.0.1:5432/db1
ℹ Testing connection...
✗ Connection failed: Database error: pgvector extension not found on your PostgreSQL server.
Install it:
macOS: brew install pgvector
Ubuntu: apt install postgresql-17-pgvector
Docker: use the pgvector/pgvector:pg17 image
Source: https://github.com/pgvector/pgvector#installation
Then restart PostgreSQL and re-run: ironclaw onboard
Try again? [Y/n] Y
Database URL: postgres://tpf:Book_1234@127.0.0.1:5432/db1
ℹ Testing connection...
✓ Database connection successful
Run database migrations? [Y/n] Y
ℹ Running migrations...
Error: Database error: Migration failed: `error applying migration V1__initial`, `db error`
xt@u24:~$ ironclaw onboard
╭─────────────────────────╮
│ IronClaw Setup Wizard │
╰─────────────────────────╯
Step 1/9: Database Connection
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
ℹ Which database backend would you like to use?
Select a database backend:
[1] PostgreSQL - production-grade, requires a running server
[2] libSQL - embedded SQLite, zero dependencies, optional Turso cloud sync
> 1
ℹ Enter your PostgreSQL connection URL.
ℹ Format: postgres://user:password@host:port/database
Database URL: postgres://postgres:Book_1234@127.0.0.1:5432/db1
ℹ Testing connection...
✓ Database connection successful
Run database migrations? [Y/n] Y
ℹ Running migrations...
✓ Migrations applied
Step 2/9: Security
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
ℹ Checking OS keychain for existing master key...
ℹ The secrets master key encrypts sensitive data like API tokens.
ℹ Choose where to store it:
Select storage method:
[1] OS Keychain (recommended for local installs)
[2] Environment variable (for CI/Docker)
[3] Skip (disable secrets features)
> 1
ℹ Generating master key...
Error: Configuration error: Failed to store in keychain: Keychain error: Failed to connect to secret service: no secret service provider or dbus session found
xt@u24:~$ ironclaw onboard
╭─────────────────────────╮
│ IronClaw Setup Wizard │
╰─────────────────────────╯
Step 1/9: Database Connection
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
ℹ Existing database URL: postgres://postgres:****@127.0.0.1:5432/db1
Use this database? [Y/n] Y
✓ Database connection successful
Step 2/9: Security
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
ℹ Checking OS keychain for existing master key...
ℹ The secrets master key encrypts sensitive data like API tokens.
ℹ Choose where to store it:
Select storage method:
[1] OS Keychain (recommended for local installs)
[2] Environment variable (for CI/Docker)
[3] Skip (disable secrets features)
> 2
ℹ Generate a key and add it to your environment:
export SECRETS_MASTER_KEY=011fa46abd76316f85ad26a614b792edb4b421b1ed52da3004e68d7f86d5d6a8
ℹ Add this to your shell profile or .env file.
✓ Configured for environment variable
Step 3/9: Inference Provider
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
ℹ Select your inference provider:
Provider:
[1] NEAR AI - multi-model access via NEAR account
[2] Anthropic - Claude models (direct API key)
[3] OpenAI - GPT models (direct API key)
[4] Ollama - local models, no API key needed
[5] OpenRouter - 200+ models via single API key
[6] OpenAI-compatible - custom endpoint (vLLM, LiteLLM, etc.)
> 1
╔════════════════════════════════════════════════════════════════╗
║ NEAR AI Authentication ║
╠════════════════════════════════════════════════════════════════╣
║ Choose an authentication method: ║
║ ║
║ [1] GitHub (requires localhost browser access) ║
║ [2] Google (requires localhost browser access) ║
║ [3] NEAR Wallet (coming soon) ║
║ [4] NEAR AI Cloud API key ║
║ ║
╚════════════════════════════════════════════════════════════════╝
Enter choice [1-4]: 2
Opening google authentication...
https://private.near.ai/v1/auth/google?frontend_callback=http%3A%2F%2F127.0.0.1%3A9876
(Could not open browser automatically, please copy the URL above)
Waiting for authentication...
✓ Authentication successful!
✓ NEAR AI configured
Step 4/9: Model Selection
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Available models:
Select a model:
[1] anthropic/claude-opus-4-6
[2] anthropic/claude-sonnet-4-5
[3] black-forest-labs/FLUX.2-klein-4B
[4] deepseek-ai/DeepSeek-V3.1
[5] google/gemini-3-pro
[6] openai/gpt-5.2
[7] openai/gpt-oss-120b
[8] Qwen/Qwen3-30B-A3B-Instruct-2507
[9] Qwen/Qwen3.5-122B-A10B
[10] zai-org/GLM-5-FP8
[11] Custom model ID
> 4
✓ Selected deepseek-ai/DeepSeek-V3.1
Step 5/9: Embeddings (Semantic Search)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
ℹ Embeddings enable semantic search in your workspace memory.
Enable semantic search? [Y/n] Y
Select embeddings provider:
[1] NEAR AI (uses same auth, no extra cost)
[2] OpenAI (requires API key)
> 2
ℹ OPENAI_API_KEY not set in environment.
ℹ Add it to your .env file or environment to enable embeddings.
✓ Embeddings configured for OpenAI
Step 6/9: Channel Configuration
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
ℹ Tunnel Configuration (for webhook endpoints):
ℹ A tunnel exposes your local agent to the internet, enabling:
ℹ - Instant Telegram message delivery (instead of polling)
ℹ - Slack, Discord, GitHub webhooks
Configure a tunnel? [y/N] y
Select tunnel provider:
[1] ngrok - managed tunnel, starts automatically
[2] Cloudflare - cloudflared tunnel, starts automatically
[3] Tailscale - Tailscale Funnel/Serve, starts automatically
[4] Custom - your own tunnel command
[5] Static URL - you manage the tunnel yourself
> 4
ℹ Enter a shell command to start your tunnel.
ℹ Use {port} and {host} as placeholders.
ℹ Example: bore local {port} --to bore.pub
Tunnel command: date
Health check URL (optional):
URL pattern (substring to match in stdout) (optional):
✓ Custom tunnel configured.
Which channels do you want to enable?
(Use arrow keys to navigate, space to toggle, enter to confirm)
> [x] CLI/TUI (always enabled)
[ ] HTTP webhook
[ ] Signal
[ ] Discord (will install)
[ ] Slack (will install)
[ ] Telegram (will install)
[ ] Whatsapp (will install)
Step 7/9: Extensions
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
ℹ Available tools from the extension registry:
ℹ Select which tools to install. You can install more later with:
ℹ ironclaw registry install
|
|
以下是 Ironclaw 安装选择的完整指南:
| 安装步骤 | 新手推荐 | 说明 |
|---------|---------|------|
| **Tunnel Configuration** (隧道配置) | **N** (不启用) | 用于将本地服务暴露到公网,接收外部webhook。新手先用轮询模式即可,后续需要再配置 |
| **Channels** (通信渠道) | **只选 Telegram** | • CLI/TUI: 必须保留
• Telegram: ✅ 推荐,API开放,文档多,易上手 • 其他(Discord/Slack等): ❌ 不选,配置复杂或国内用不上 | | **Tools** (工具集成) | **只选 Web Search** | • Web Search: ✅ 推荐,国内可用,配置简单 • Telegram Tool: ⭕ 可选,如需agent主动发消息 • 谷歌全家桶: ❌ 不选,需要翻墙 • GitHub: ❌ 不选,国内访问不稳定 | | **Docker Sandbox** (Docker沙箱) | **Y** (启用) | • ✅ 启用:安全隔离,防止AI代码破坏系统 • ❌ 不启用:代码直接运行,有安全风险 | ## 最终配置清单: ``` 已选配置: ├── Channels: Telegram(用于接收和回复消息) ├── Tools: Web Search(用于联网搜索) ├── Docker: 启用(安全隔离) └── Tunnel: 不启用(先用轮询模式) ``` 这样配置可以让新手: 1. ✅ 快速上手,配置最少 2. ✅ 国内可用,不需要翻墙 3. ✅ 安全性有保障 4. ✅ 后续扩展灵活 |
|
pg_ctl -D /wks/app/pg/pg17/data -l logfile start
xt@qisan:/ai/wks/rust/ironclaw/ironclaw-staging/target/release$ ./ironclaw config get llm_backend
xt@qisan:/ai/wks/rust/ironclaw/ironclaw-staging/target/release$ ./ironclaw
- 你能做什么?
我能做很多事情!以下是我的主要能力:
🔧 工具与自动化
任务管理:创建、监控、取消多步骤任务
HTTP请求:访问外部API,下载文件
数据处理:JSON解析、查询、转换
时间操作:时区转换、时间计算、定时任务
🖼️ 图像处理
根据文字描述生成图像
编辑现有图像
分析图像内容(识别物体、场景等)
📡 通信与集成
发送消息到各种平台(Telegram、Slack等)
安装和管理扩展(通道、工具、MCP服务器)
连接到外部服务(API集成)
🧠 记忆与上下文
持久化存储重要信息
搜索过去的对话和决策
维护每日日志和长期记忆
⚙️ 系统管理
创建定时/事件驱动的例行任务
安装和管理技能(ClawHub技能库)
扩展系统功能(搜索和安装新工具)
📁 文件操作
读写工作空间文件
管理记忆数据库
🎯 实际应用场景
自动化日常工作流程
数据收集和处理
图像创作和编辑
消息通知和提醒
外部服务集成
信息记忆和检索
你有什么具体想做的吗?我可以根据你的需求提供更详细的指导或直接帮你完成!
|
|
|
|
|
|
|
ironclaw·使用
|
sudo su - postgres
pg_ctl -D /wks/app/pg/pg17/data -l logfile start
cd /ai/wks/rust/ironclaw/ironclaw-staging/target/release
./ironclaw
xt@qisan:/ai/wks/rust/ironclaw/ironclaw-staging/target/release$ ./ironclaw
|
|
```
$ cat /home/xt/.ironclaw/.env
DATABASE_BACKEND="postgres"
DATABASE_URL="postgres://postgres:Book_1234@127.0.0.1:5432/db1"
LLM_BACKEND="deepseek"
DEEPSEEK_MODEL="deepseek-chat"
DEEPSEEK_API_KEY="sk-5369c5...432"
ONBOARD_COMPLETED="true"
```
$ ./ironclaw
Error: Configuration error: Missing required setting 'LLM_BASE_URL'. Set LLM_BASE_URL when LLM_BACKEND=glm. Run 'ironclaw onboard' to configure, or set the required environment variables.
$ ./ironclaw onboard
╭─────────────────────────╮
│ IronClaw Setup Wizard │
╰─────────────────────────╯
Step 1/9: Database Connection
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
ℹ Existing database URL: postgres://postgres:****@127.0.0.1:5432/db1
Use this database? [Y/n]
|
|
|
|
|
|
|
|
|
|
|
|
|
参考