连续的整数
import numpy as np data=np.arange(100000000000001,100000000100001) data.shape #(100000,)
随机的时间列
|
效果:随机生成一个字符串日期列表 ['2023-05-25 11:09:00', '2023-05-25 09:30:59', '2023-05-24 18:34:03', '2023-05-24 15:50:42', '2023-05-23 21:12:59', '2023-05-23 17:52:01', '2023-05-23 09:46:55'] 封装示例 from tpf.data.make import TimeGen tg = TimeGen() ts = tg.year1_ymh(count=30000) len(ts) 30000 ts[:3] ['2025-06-21 18:38:22', '2025-06-21 18:28:28', '2025-06-21 18:27:28'] minute_one_year方法以minute_min为最小分钟间隔,生成一个时间列表 - 比如,11分钟,30分钟等 传入ymdhms_time方法,生成从当前时间开始的系列随机时间
|
from tpf import random_yyyymmdd
df["dtt"] = random_yyyymmdd(dt_format="%Y-%m-%d")
df["dtt"]
0 2016-11-24
1 2016-11-24
2 2016-11-24
3 2016-11-24
4 2016-11-24
...
564 2016-11-24
565 2016-11-24
566 2016-11-24
567 2016-11-24
568 2016-11-24
Name: dtt, Length: 569, dtype: object
|
|
|
|
|
|
|
IBM·交易数据
|
位置
/wks/aitpf/datasets/ibm_aml
/wks/aitpf/datasets/ibm_aml/21-数据加载.ipynb
IBM数据集处理明细
http://172.26.64.200:33033/gnn_ibm
读取·无时间列
#IMPORT STATEMENTS
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
BASE_DIR = "/wks/datasets/ibm_aml"
data_path = os.path.join(BASE_DIR,"HI-Small_Trans.csv")
df=pd.read_csv(data_path)
df.shape #(5078345, 11)
封装方式:去掉了时刻列,保留关键7列转化为数字
/opt/wks/aiwks/datasets/ibm_aml/22-2-数据集.ipynb
数据观察
http://172.26.114.122:33033/gnn_ibm#dl_activate
使用示例
/opt/wks/aiwks/jupyter/dl_kejian/ai44/day28_attention/IBM-DL-数据集.ipynb
|
|
加载
import pandas as pd
from tpf import read,write
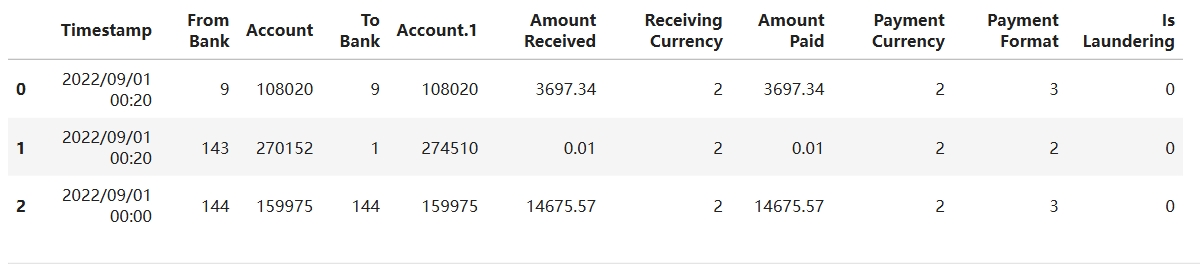
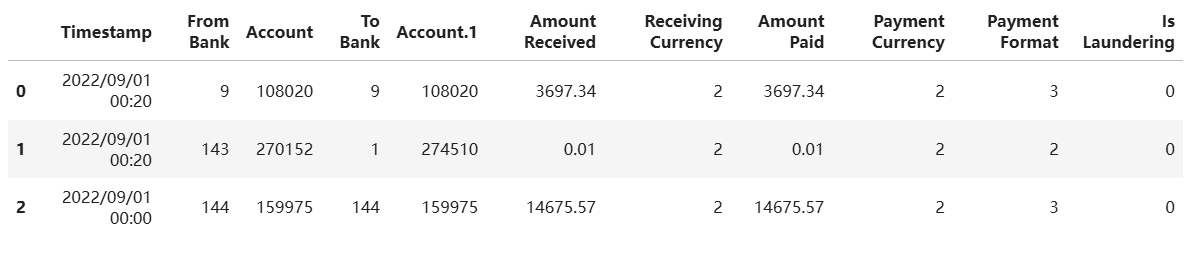
df = pd.read_csv("/wks/datasets/ibm_aml/ibm_small_2.csv")
df[:3]
cls_dict = read("/wks/datasets/ibm_aml/ibm_small_2.dict")
for col in cls_dict:
print(col)
UNK
From Bank
Account
Receiving Currency
Payment Format
Receiving Currencyk
处理过程 /opt/wks/aiwks/datasets/ibm_aml/22-2_编码全数据集.ipynb #IMPORT STATEMENTS import numpy as np import pandas as pd import os BASE_DIR = "/wks/datasets/ibm_aml" data_path = os.path.join(BASE_DIR,"HI-Small_Trans.csv") df=pd.read_csv(data_path) df.shape from tpf.d1 import CsvStat st = CsvStat(data=df,print_level=2,) cls_dict = st.word2id(["From Bank","Account",'Receiving Currency', 'Payment Format']) st.head(3) cls_dict2 = st.word2id(["Account.1"],word2id=cls_dict["Account"]) cls_dict["Account"] = cls_dict2['Account.1'] cls_dict2 = st.word2id(["To Bank"],word2id=cls_dict["From Bank"]) cls_dict["From Bank"] = cls_dict2['To Bank'] cls_dict2 = st.word2id(['Payment Currency'],word2id=cls_dict["Receiving Currency"]) cls_dict["Receiving Currencyk"] = cls_dict2['Payment Currency'] st.head(3)
data = st.data
data.to_csv("ibm_small_2.csv",index=False)
from tpf import read,write
write(cls_dict,"ibm_small_2.dict")
|
|
加载
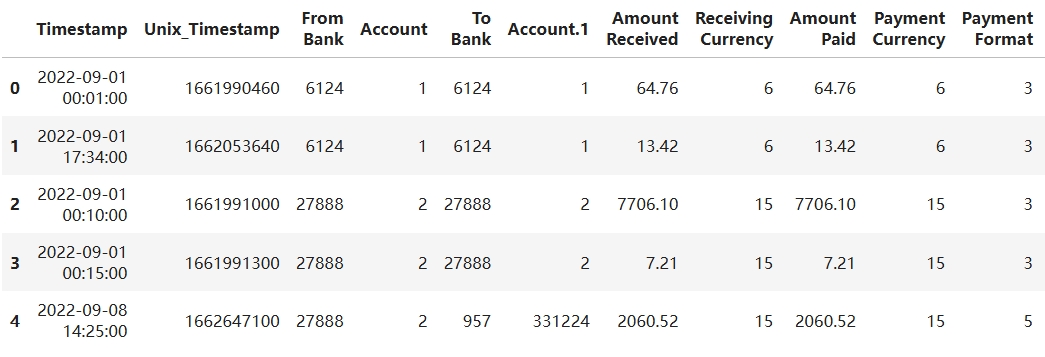
import pandas as pd
df = pd.read_csv("/wks/datasets/ibm_aml/ibm_time_1.csv")
df[:5]
按Account与Unix_Timestamp升序排序 处理过程
import pandas as pd
from tpf import read,write
df = pd.read_csv("/wks/datasets/ibm_aml/ibm_small_2.csv")
时间处理
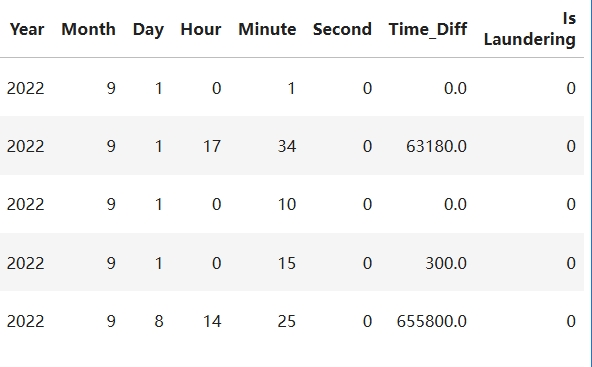
df['Timestamp'] = pd.to_datetime(df['Timestamp'])
df['Year'] = df['Timestamp'].dt.year
df['Month'] = df['Timestamp'].dt.month
df['Day'] = df['Timestamp'].dt.day
df['Hour'] = df['Timestamp'].dt.hour
df['Minute'] = df['Timestamp'].dt.minute
df['Second'] = df['Timestamp'].dt.second
df['Unix_Timestamp'] = df['Timestamp'].astype('int64') // 10**9 # 转换为秒
# 按 Account 列分组,并计算每个分组内 Unix_Timestamp 的差值
df['Time_Diff'] = df.groupby('Account')['Unix_Timestamp'].diff()
df.fillna(0,inplace=True)
df.sort_values(by=['Account','Unix_Timestamp'], inplace=True, ascending=[True,True])
df[:7]
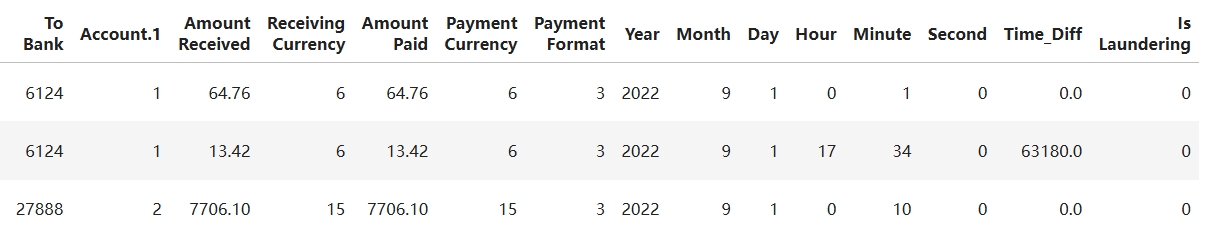
|
|
加载
import torch
from torch import nn
from tpf import pkl_load,pkl_save
#numpy类型
X,y = pkl_load("ibm_seq_Xy1.pkl")
print(X.shape,y.shape) # ((1101563, 10, 14), (1101563, 10))
过滤掉了交易个数不足SEQ_LENGTH长度的账户
处理过程
import pandas as pd
df = pd.read_csv("/wks/datasets/ibm_aml/ibm_time_1.csv")
acc_list = df['Account'].unique()
import torch
from torch import nn
from tpf.datasets import SeqData as sd
# 参数配置
SEQ_LENGTH = 10 # 滑动窗口长度
BATCH_SIZE = 64
HIDDEN_SIZE = 32
EPOCHS = 50
数据量大,最好一次取一个账户的数据;然后再做二次合并
acc_count = 0
for acc in acc_list:
acc_group = df[df["Account"] == acc]
if acc_group.shape[0] < SEQ_LENGTH:
continue
drop_cols = ['Timestamp', 'Unix_Timestamp', 'Account', 'Account.1']
acc_group = acc_group.drop(columns=drop_cols)
label = acc_group["Is Laundering"]
data = acc_group.drop(columns=["Is Laundering"])
if acc_count == 0:
X,y = sd.create_sequences11(data=data, label=label,
seq_length=SEQ_LENGTH, step=3, is_label_long=True)
else:
X2,y2 = sd.create_sequences11(data=data, label=label,
seq_length=SEQ_LENGTH, step=3, is_label_long=True)
X = torch.cat([X,X2],dim=0)
y = torch.cat([y,y2],dim=0)
acc_count += 1
# if acc_count> 3:
# break
X.shape,y.shape
from tpf import pkl_load,pkl_save #存储为Numpy类型 pkl_save((X.numpy(),y.numpy()),"ibm_seq_Xy1.pkl") 数据集
import numpy as np
import torch
from torch import nn
from tpf import pkl_load,pkl_save
#numpy类型
X,y = pkl_load("ibm_seq_Xy1.pkl")
print(X.shape,y.shape) # ((1101563, 10, 14), (1101563, 10))
ll = y.shape[0]
y_1 = []
X_1 = []
for i in range(ll):
tmp_y = (y[i]==1).sum()
if tmp_y>0:
y_1.append(y[i])
X_1.append(X[i])
X1 = np.array(X_1)
y1 = np.array(y_1)
X1.shape,y1.shape # ((4932, 10, 14), (4932, 10))
|
IBM·数据观察
import pandas as pd
import numpy as np
from datetime import date, timedelta
df = pd.read_csv("/wks/datasets/ibm_aml/bb11_train_ibm_small.csv")
df[:3]
import pandas as pd
# 假设你的 DataFrame 名为 df
# 计算各列的不重复值个数
unique_counts = {
'ORGANKEY': df['ORGANKEY'].nunique(),
'ACCT_NUM': df['ACCT_NUM'].nunique(),
'CFIC': df['CFIC'].nunique(),
'TCAC': df['TCAC'].nunique()
}
# 创建组合列并计算不重复值个数
df['ORGANKEY_ACCT_NUM'] = df['ORGANKEY'].astype(str) + '_' + df['ACCT_NUM'].astype(str)
df['CFIC_TCAC'] = df['CFIC'].astype(str) + '_' + df['TCAC'].astype(str)
# 计算组合列的不重复值个数
combined_counts = {
'ORGANKEY_ACCT_NUM': df['ORGANKEY_ACCT_NUM'].nunique(),
'CFIC_TCAC': df['CFIC_TCAC'].nunique()
}
print("各列不重复值个数:")
print(unique_counts)
print("\n组合列不重复值个数:")
print(combined_counts)
各列不重复值个数:
{'ORGANKEY': 30470, 'ACCT_NUM': 496999, 'CFIC': 15811, 'TCAC': 420640}
组合列不重复值个数:
{'ORGANKEY_ACCT_NUM': 496999, 'CFIC_TCAC': 420640}
从上面的数据可以看出,不存在不同的机构中出现相同账户的情况,
- 因此完全可以使用以账户作为主体,
- 而不是机构+账户作为主体
# 合并两列的所有值,然后计算唯一值个数
unique_values = pd.concat([df['ACCT_NUM'], df['TCAC']]).nunique()
print(f"ACCT_NUM 和 TCAC 所有不重复值的总数: {unique_values}")
ACCT_NUM 和 TCAC 所有不重复值的总数: 515088
# 转换为字符串后合并并去重
unique_set = set(df['ACCT_NUM'].astype(str)) | set(df['TCAC'].astype(str))
unique_count = len(unique_set)
print(f"ACCT_NUM 和 TCAC 所有不重复值的总数: {unique_count}")
ACCT_NUM 和 TCAC 所有不重复值的总数: 515088
|
|
|
|
|
|
|
|